溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
譯者前言
近期的主要工作是在為公司的 APP 增加搜索功能。因為也遇到了需要把關系型數據庫中的數據同步 ElasticSearch 中的問題,故抽了點時間翻譯了這篇官方的博文。最近,在數據同步方面也有些思考。
本篇文章的重點不在 Logstash 的 JDBC 插件的使用方法,而是數據同步會遇到的一些細節問題如何處理。我覺得,這些設計思想是通用的,無論你使用的何種方式進行數據同步。
翻譯正文
為了利用 ElasticSearch 強大的搜索能力,大部分的業務都會在關系型數據庫的基礎上部署 ElasticSearch。這類場景下,保持 ElasticSearch 和關系型數據庫之間的數據同步是非常必要的。
本篇博文將會介紹如何通過 Logstash 實現在 MySQL 和 ElasticSearch 之間數據的高效復制與同步。
注:文中演示的代碼和方法都經過在 MySQL 中的測試,理論上適應于所有的關系型數據庫。
本文中,組件的相關信息如下:
MySQL: 8.0.16.
Elasticsearch: 7.1.1
Logstash: 7.1.1
Java: 1.8.0_162-b12
JDBC input plugin: v4.3.13
JDBC connector: Connector/J 8.0.16數據同步概述
本文將會通過 Logstash 的 JDBC input 插件進行 ElasticSearch 和 MySQL 之間的數據同步。從概念上講,JDBC 插件將通過周期性的輪詢以發現上次迭代后的新增和更新的數據。為了正常工作,幾個條件需要滿足:
ElasticSearch 中 _id 設置必須來自 MySQL 中 id 字段。它提供了 MySQL 和 ElasticSearch 之間文檔數據的映射關系。如果一條記錄在 MySQL 更新,那么,ElasticSearch 所有關聯文檔都應該被重寫。要說明的是,重寫 ElasticSearch 中的文檔和更新操作的效率相同。在內部實現上,一個更新操作由刪除一個舊文檔和創建一個新文檔兩部分組成。
當 MySQL 中插入或更新一條記錄時,必須包含一個字段用于保存字段的插入或更新時間。如此一來, Logstash 就可以實現每次請求只獲取上次輪詢后更新或插入的記錄。Logstash 每次輪詢都會保存從 MySQL 中讀取到的最新的插入或更新時間,該時間大于上次輪詢最新時間。
如果滿足了上述條件,我們就可以配置 Logstash 周期性的從 MySQL 中讀取所有最新更新或插入的記錄,然后寫入到 Elasticsearch 中。
關于 Logstash 的配置代碼,本文稍后會給出。
MySQL 設置
MySQL 庫和表的配置如下:
CREATE DATABASE es_db
USE es_db
DROP TABLE IF EXISTS es_table
CREATE TABLE es_table (
id BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY unique_id (id),
client_name VARCHAR(32) NOT NULL,
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);配置中有幾點需要說明,如下:
es_table,MySQL 的數據表,我們將把它的數據同步到 ElasticSearch 中;
id,記錄的唯一標識。注意,id 定義為主鍵的同時,也定義為唯一建,可以保證每個 id 在表中只出現一次。同步 ElasticSearch 時,將會轉化為文檔的 _id;
client_name,表示用戶定義用來保存數據的字段,為使博文保持簡潔,我們只定義了一個字段,更多字段也很容易加入。接下來的演示,我們會更新該字段,用以說明不僅僅新插入記錄會同步到 MySQL,更新記錄同樣會同步到 MySQL;
modification_time,用于保存記錄的更新或插入時間,它使得 Logstash 可以在每次輪詢時只請求上次輪詢后新增更新的記錄;
insertion_time,該字段用于一條記錄插入時間,主要是為演示方便,對同步而言,并非必須;
MySQL 操作
前面設置完成,我們可以通過如下命令插入記錄:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);`使用如下命令更新記錄:
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;使用如下命令更新插入記錄:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client_name when created>) ON DUPLICATE KEY UPDATE client_name=<client name when updated>同步代碼
Logstash 的 pipeline 配置代碼如下,它實現了前面描述的功能,從 MySQL 到 ElasticSearch 的數據同步。
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => "<my username>"
jdbc_password => "<my password>"
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *",
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time)) > :sql_last_value AND modification_time < NOW() ORDER BY modification_time desc"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug" }
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[%metedata][_id]}"
}
}關于 Pipeline 配置的幾點說明,如下:
tracking_column此處配置為 "unix_ts_in_secs"。它被用于追蹤最新的記錄,并被保存在 .logstash_jdbc_last_run 文件中,下一次輪詢將以這個邊界位置為準進行記錄獲取。SELECT 語句中,可通過 :sql_last_value 訪問該配置字段的值。
unix_ts_in_secs由 SELECT 語句生成,是 "modification_time" 的 UNIX TIMESTAMP。它被前面討論的 "track_column" 引用。使用 UNIX TIMESTAMP,而非其他時間形式,可以減少復雜性,防止時區導致的時間不一致問題。
sql_last_value內建的配置參數,指定每次輪詢的開始位置。在 input 配置中,可被 SELECT 語句引用。在每次輪詢開始前,從 .logstash_jdbc_last_run 中讀取,此案例中,即為 "unix_ts_in_secs" 的最近值。如此便可保證每次輪詢只獲取最新插入和更新的記錄。
schedule通過 cron 語法指定輪詢的執行周期,例子中,"/5 " 表示每 5 秒輪詢一次。
modification_time < NOW()SELECT 語句查詢條件的一部分,當前解釋不清,具體情況待下面的章節再作介紹。
filter
該配置指定將 MySQL 中的 id 復制到 metadata 字段 _id 中,用以確保 ElasticSearch 中的文檔寫入正確的 _id。而之所以使用 metadata,因為它是臨時的,不會使文檔中產生新的字段。同時,我們也會把不希望寫入 Elasticsearch 的字段 id 和 @version 移除。
output在 output 輸出段的配置,我們指定了文檔應該被輸出到 ElasticSearch,并且設置輸出文檔 _id 為 filter 段創建的 metadata 的 _id。如果需要調試,注釋部分的 rubydebug 可以實現。
SELECT 語句的正確性分析
接下來,我們將開始解釋為什么 SELECT 語句中包含 modification_time < NOW() 是非常重要的。為了解釋這個問題,我們將引入兩個反例演示說明,為什么下面介紹的兩種最直觀的方法是錯誤的。還有,為什么 modification_time < Now() 可以克服這些問題。
直觀場景一
當 where 子句中僅僅包含 UNIX_TIMESTAMP(modification_time) > :sql_last_value,而沒有 modification < Now() 的情況下,工作是否正常。這個場景下,SELECT 語句是如下形式:
statement => "SELECT *, UNIX_TIMESTAMP(modification_time)
AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >
:sql_last_value) ORDER BY modification_time ASC"粗略一看,似乎沒發現什么問題,應該可以正常工作。但其實,這里有一些邊界情況,可能導致一些文檔的丟失。舉個例子,假設 MySQL 每秒插入兩個文檔,Logstash 每 5 秒執行一次。如下圖所示,時間范圍 T0 至 T10,數據記錄 R1 至 R22。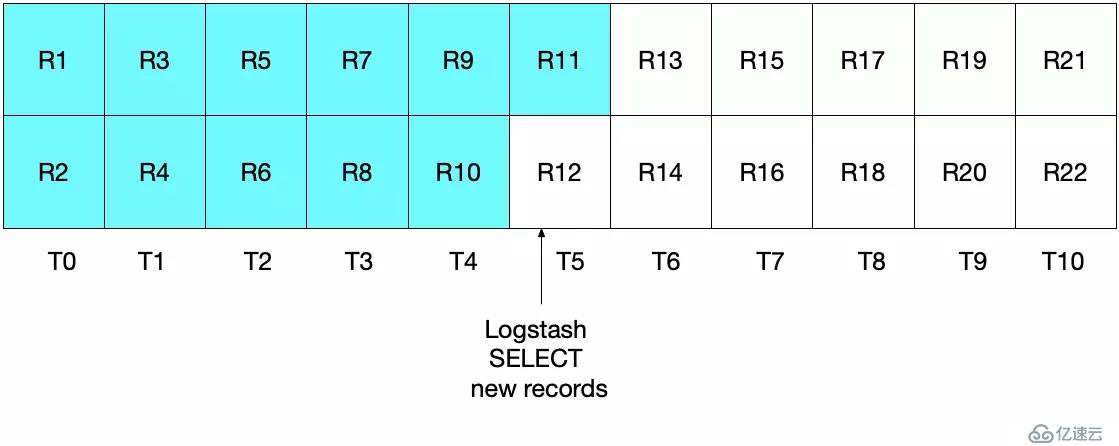
Logstash 的第一次輪詢發生在 T5 時刻,讀取記錄 R1 至 R11,即圖中青色區域。此時,sql_last_value 即為 T5,這個時間是從 R11 中獲取到的。
如果,當 Logstash 完成從 MySQL 讀取數據后,同樣在 T5 時刻,又有一條記錄插入到 MySQL 中。 而下一次的輪詢只會拉取到大于 T5 的記錄,這意味著 R12 將會丟失。如圖所示,青色和灰色區域分別表示當次和上次輪詢獲取到的記錄。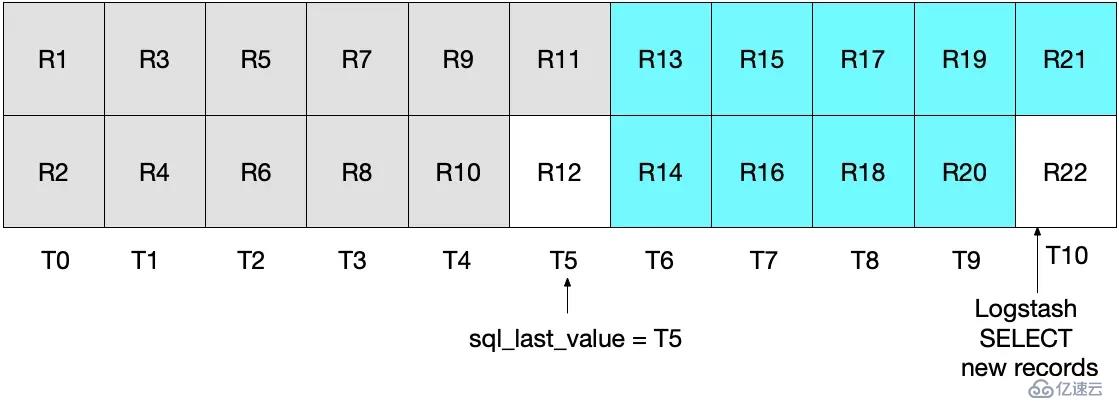
注意,這類場景下的 R12 將永遠不會再被寫入到 ElasticSearch。
直觀場景二
為了解決這個問題,或許有人會想,如果把 where 子句中的大于(>)改為大于等于(>=)是否可行。SELECT 語句如下
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"這種方式其實也不理想。這種情況下,某些文檔可能會被兩次讀取,重復寫入到 ElasticSearch 中。雖然這不影響結果的正確性,但卻做了多余的工作。如下圖所示,Logstash 的首次輪詢和場景一相同,青色區域表示已經讀取的記錄。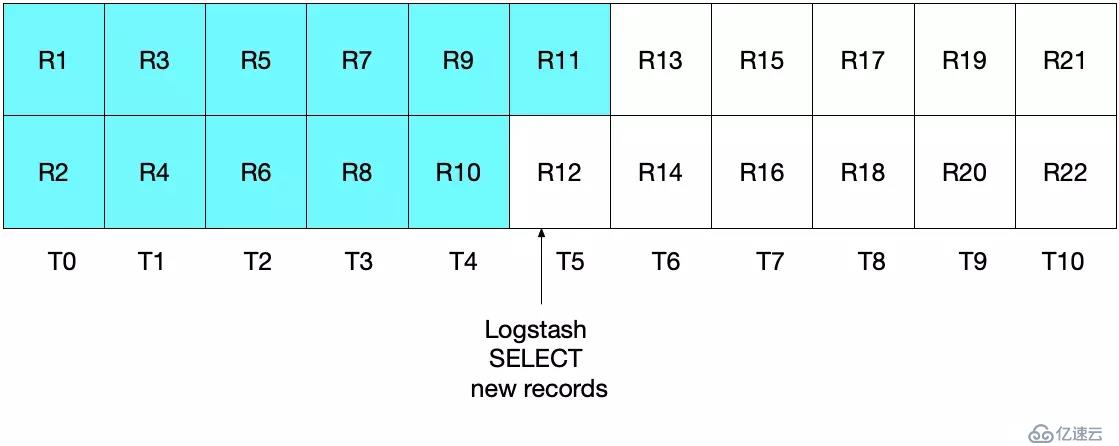
Logstash 的第二次輪詢將會讀取所有大于等于 T5 的記錄。如下圖所示,注意 R11,即紫色區域,將會被再次發送到 ElasticSearch 中。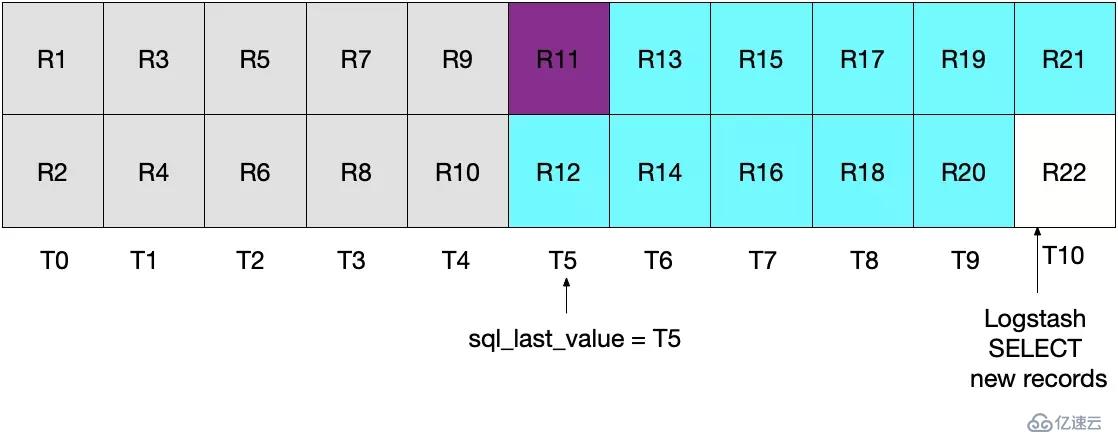
這兩種場景的實現效果都不理想。場景一會導致數據丟失,這是無法容忍的。場景二,存在重復讀取寫入的問題,雖然對數據正確性沒有影響,但執行了多余的 IO。
終極方案
前面的兩場方案都不可行,我們需要繼續尋找其他解決方案。其實也很簡單,通過指定 (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()),我們就可以保證每條記錄有且只發送一次。
如下圖所示,Logstash 輪詢發生在 T5 時刻。因為指定了 modification_time < NOW(),文檔只會讀取到 T4 時刻,并且 sql_last_value 的值也將會被設置為 T4。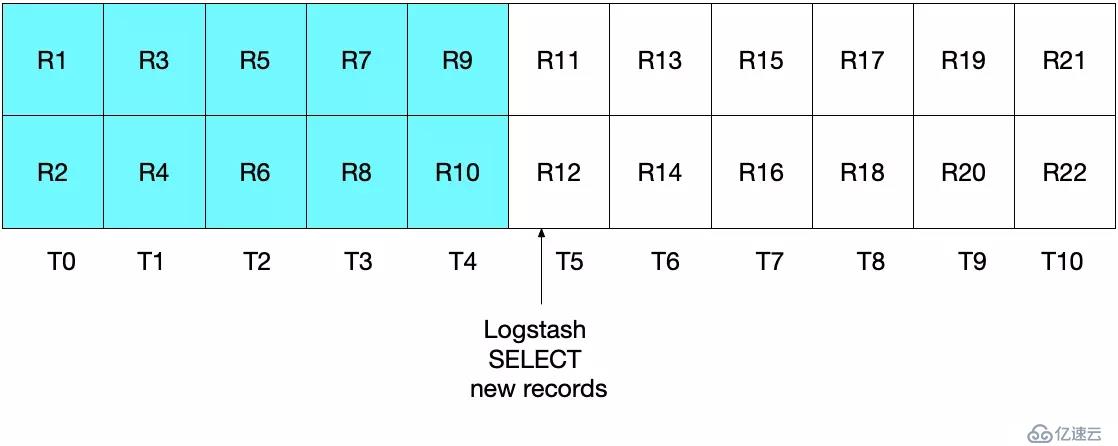
開始下一次的輪詢,當前時間 T10。
由于設置了 UNIX_TIMESTAMP(modification_time) > :sql_last_value,并且當前 sql_last_value 為 T4,因此,本次的輪詢將從 T5 開始。而 modification_time < NOW() 決定了只有時間小于等于 T9 的記錄才會被讀取。最后,sql_last_value 也將被設置為 T9。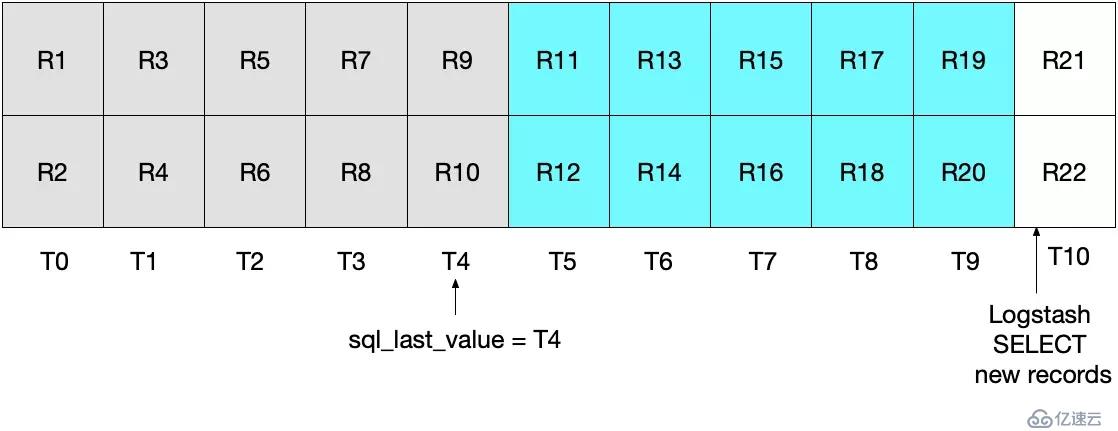
如此,MySQL 中的每個記錄就可以做到都能被精確讀取了一次,如此就可以避免每次輪詢可能導致的當前時間間隔內數據丟失或重復讀取的問題。
系統測試
簡單的測試可以幫助我們驗證配置是否如我們所愿。我們可以寫入一些數據至數據庫,如下:
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey');
INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers');
INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');一旦 JDBC 輸入插件觸發執行,將會從 MySQL 中讀取所有記錄,并寫入到 ElasticSearch 中。我們可以通過查詢語句查看 ElasticSearch 中的文檔。
`GET rdbms_sync_idx/_search`執行結果如下:
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:04:27.436Z",
"modification_time" : "2019-06-18T12:58:56.000Z",
"client_name" : "Jim Carrey"
}
},
Etc …更新 id=1 的文檔,如下:
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;通過 _id = 1,可以實現文檔的正確更新。通過執行如下命令查看文檔:
GET rdbms_sync_idx/_doc/1結果如下:
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:09:30.300Z",
"modification_time" : "2019-06-18T13:09:28.000Z",
"client_name" : "Jimbo Kerry"
}
}文檔 _version 被設置為 2,并且 modification_time 和 insertion_time 已經不一樣了,client_name 已經正確更新。而 @timestamp,不是我們需要關注的,它是 Logstash 默認添加的。
更新添加 upsert 執行語句如下:
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';復制代碼和之前一樣,我們可以通過查看 ElasticSearch 中相應文檔,便可驗證同步的正確性。
文檔刪除
不知道你是否已經發現,如果一個文檔從 MySQL 中刪除,并不會同步到 ElasticSearch 。關于這個問題,列舉一些可供我們考慮的方案,如下:
MySQL 中的記錄可通過包含 is_deleted 字段用以表明該條記錄是否有效。一旦發生更新,is_deleted 也會同步更新到 ElasticSearch 中。如果通過這種方式,在執行 MySQL 或 ElasticSearch 查詢時,我們需要重寫查詢語句來過濾掉 is_deleted 為 true 的記錄。同時,需要一些后臺進程將 MySQL 和 ElasticSearch 中的這些文檔刪除。
另一個可選方案,應用系統負責 MySQL 和 ElasticSearch 中數據的刪除,即應用系統在刪除 MySQL 中數據的同時,也要負責將 ElasticSearch 中相應的文檔刪除。
總結
本文介紹了如何通過 Logstash 進行關系型數據庫和 ElasticSearch 之間的數據同步。文中以 MySQL 為例,但理論上,演示的方法和代碼也應該同樣適應于其他的關系型數據庫。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





