溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Kafka核心思想概括和底層原理”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Kafka核心思想概括和底層原理”吧!
所有的消息以“有序日志“的方式存儲,生產者將消息發布到末端(可理解為追加),消費者從某個邏輯位按序讀取。
【場景一】消息中間件
在選擇消息中間件時,我們的主要關注點有:性能、消息的可靠性,順序性。
1.性能
關于Kafka的高性能,主要是因為它在實現上利用了操作系統一些底層的優化技術,盡管作為寫業務代碼的程序員,這些底層知識也是需要了解的。
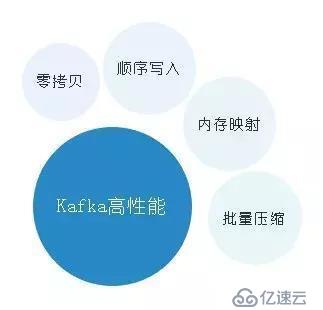
【優化一】零拷貝
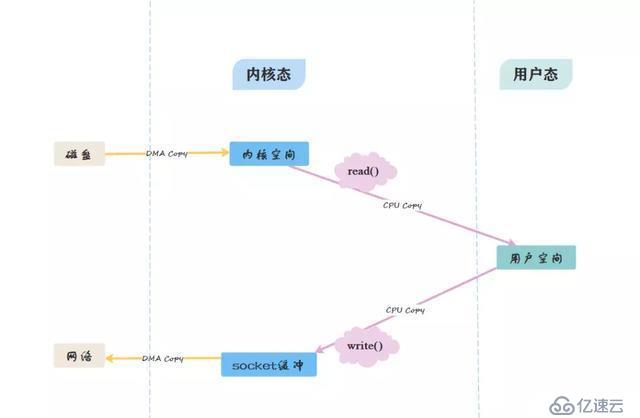
這是Kafka在消費者端的優化,我們通過兩張圖來比較一下傳統方式與零拷貝方式的區別:
傳統方式:
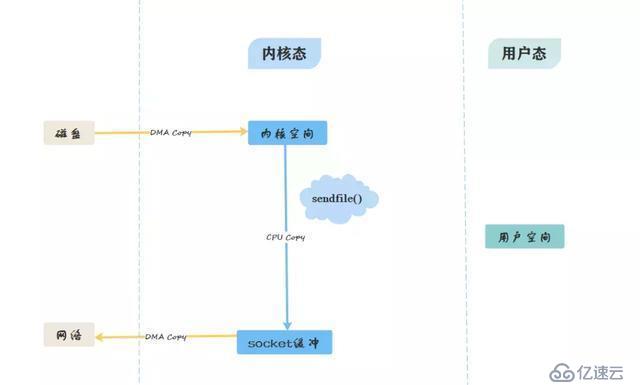
零拷貝方式:
終極目標:如何讓數據不經過用戶空間?
從圖中可看出,零拷貝省略了拷貝到用戶緩沖的步驟,通過文件描述符,直接從內核空間將數據復制到網卡接口。
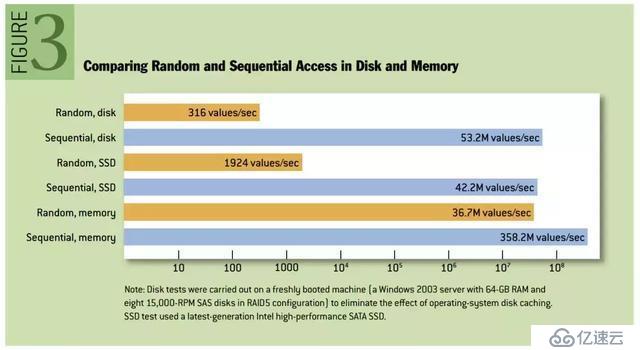
【優化二】順序寫入磁盤
寫入消息時,采用文件追加的方式,并且不允許修改已經寫入的消息,于是寫入磁盤的方式是順序寫入。我們通常認為的基于磁盤讀寫性能較差,指的是基于磁盤的隨機讀寫;事實上,基于磁盤的順序讀寫,性能接近于內存的隨機讀寫,以下是性能對比圖:
【優化三】內存映射
概括:用戶空間的一段內存區域映射到內核空間,這樣,無論是內核空間或用戶空間對這段內存區域的修改,都可以直接映射到另一個區域。
優勢:如果內核態和用戶態存在大量的數據傳輸,效率是非常高的。
為什么會提高效率:概括來講,傳統方式為read()系統調用,進行了兩次數據拷貝;內存映射方式為mmap()系統調用,只進行一次數據拷貝
【優化四】批量壓縮
生產者:批量發送消息集消費者:主動拉取數據,同樣采用批量拉取的方式
2.可靠性
Kafka的副本機制是保證其可靠性的核心。
關于副本機制,我將它理解為Leader-Follower機制,就是多個服務器中有相同數據的多個副本,并且劃分的粒度是分區。很明顯,這樣的策略就有下面幾個問題必須解決:
各副本間如何同步?
ISR機制:Leader動態維護一個ISR(In-Sync Replica)列表,
Leader故障,如何選舉新的Leader?
要想解決這個問題,就要引出Zookeeper,它是Kafka實現副本機制的前提,關于它的原理且聽下回分解,本篇還是從Kafka角度進行分析。在這里我們只需要了解,一些關于Broker、Topics、Partitions的元信息存儲在Zookeeper中,Leader發生故障時,從ISR集合中進行選舉新的Leader。
request.required.acks來設置數據的可靠性:
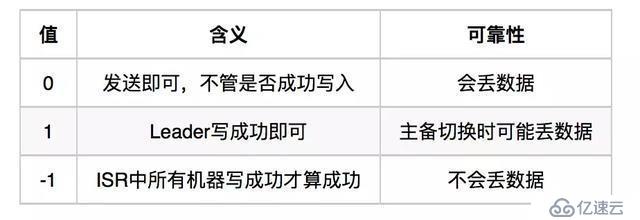
分區機制和副本機制知識點:
3.順序性
順序性保證主要依賴于分區機制 + 偏移量。
提到分區,首先就要解釋一下相關的概念以及他們之間的關系,個人總結如下幾點:
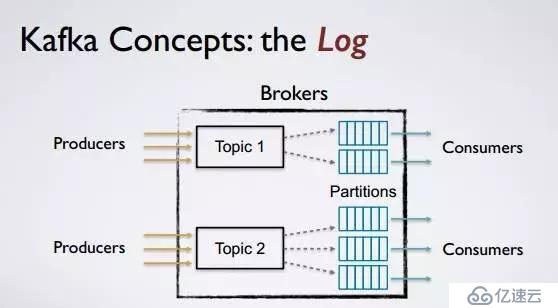
服務器(Broker):指一個獨立的服務器
主題(Topic):消息的邏輯分類,可跨Broker
分區(Partition):消息的物理分類,基本的存儲單元
這里盜一張圖闡述上述概念間的關系
為什么分區機制可以保證消息的順序性?
Kafka可以保證一個分區內消息是有序且不可變的。
生產者:Kafka的消息是一個鍵值對,我們通過設置鍵值,指定消息被發送到特定主題的特定分區。
可以通過設置key,將同一類型的消息,發到同一個分區,就可以保證消息的有序性。
消費者:消費者需要通過保存偏移量,來記錄自己消費到哪個位置,在0.10版本前,偏移量保存在zk中,后來保存在 __consumeroffsets topic中。
【場景二】流處理
在0.10版本后,Kafka內置了流處理框架API——Kafka Streams,一個基于Kafka的流式處理類庫,它利用了上述,至此,Kafka也就隨之發展成為一個囊括消息系統、存儲系統、流處理系統的中央式的流處理平臺。
與已有的Spark Streaming平臺不同的是,Spark Streaming或Flink是一個是一個系統架構,而Kafka Streams屬于一個庫。Kafka Streams秉承簡單的設計原則,優勢體現在運維上。同時Kafka Streams保持了上面提到的所有特性。
關于二者適合的應用場景,已有大佬給出了結論,就不強行總結了。
Kafka Streams:適合”Kafka --> Kafka“場景
Spark Streaming:適合”Kafka --> 數據庫”或“Kafka --> 數據科學模型“場景
到此,相信大家對“Kafka核心思想概括和底層原理”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





