溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
? streaming流式計算是一種被設計用于處理無限數據集的數據處理引擎,而無限數據集是指一種不斷增長的本質上無限的數據集,而window是一種切割無限數據為有限塊進行處理的手段。
? Window是無限數據流處理的核心,Window將一個無限的stream拆分成有限大小的”buckets”桶,我們可以在這些桶上做計算操作。
window可以分為兩大類:
CountWindow:按照指定的數據條數生成一個Window,與時間無關。比較少用
TimeWindow:按照時間生成Window。非常常用,下面主要將時間窗口有哪些類型。主要有四類:滾動窗口(Tumbling Window)、滑動窗口(Sliding Window)、會話窗口(Session Window)和全局窗口(global window比較少用 )。
概述:將數據依據固定的窗口長度對數據進行切片。只有一個工作參數,就是窗口大小
特點:時間對齊,窗口長度固定,沒有重疊。
? 滾動窗口分配器將每個元素分配到一個指定窗口大小的窗口中,滾動窗口有一個固定的大小,并且不會出現重疊(前后時間點都是緊接著的)。例如:如果你指定了一個5分鐘大小的滾動窗口,窗口的創建如下圖所示: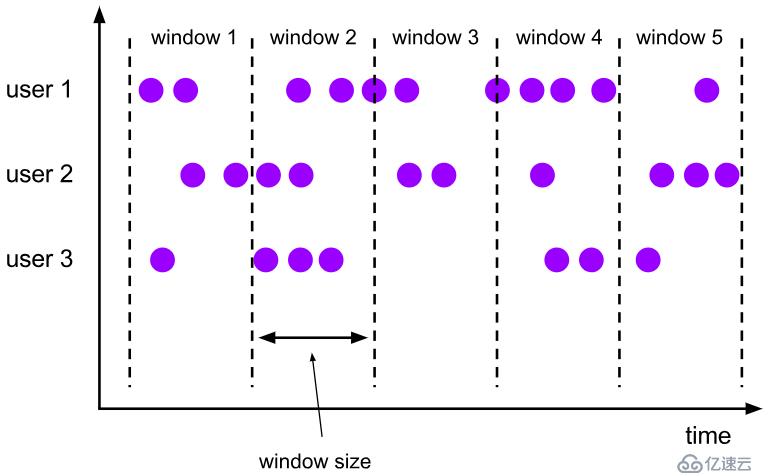
? 圖 1.2.1 滾動窗口
適用場景:適合做BI統計等(做每個時間段的聚合計算)。
概述:滑動窗口是固定窗口的更廣義的一種形式,滑動窗口工作參數由固定的窗口長度和滑動間隔組成。
特點:時間對齊,窗口長度固定,有重疊。
? 滑動窗口分配器將元素分配到固定長度的窗口中,與滾動窗口類似,窗口的大小由窗口大小參數來配置,另一個窗口滑動參數控制滑動窗口開始的頻率。因此,滑動窗口如果滑動參數小于窗口大小的話,窗口是可以重疊的,在這種情況下元素會被分配到多個窗口中。
例如,你有10分鐘的窗口和5分鐘的滑動,那么每個窗口中5分鐘的窗口里包含著上個10分鐘產生的數據,如下圖所示:
? 圖 1.2.2 滑動窗口
適用場景:對最近一個時間段內的統計(求某接口最近5min的失敗率來決定是否要報警)。
概述:由一系列事件組合一個指定時間長度的timeout間隙組成,類似于web應用的session,也就是一段時間沒有接收到新數據就會生成新的窗口。
特點:時間無對齊。窗口無固定長度
? session窗口分配器通過session活動來對元素進行分組,session窗口跟滾動窗口和滑動窗口相比,不會有重疊和固定的開始時間和結束時間的情況,相反,當它在一個固定的時間周期內不再收到元素,即非活動間隔產生,那個這個窗口就會關閉。一個session窗口通過一個session間隔來配置,這個session間隔定義了非活躍周期的長度,當這個非活躍周期產生,那么當前的session將關閉并且后續的元素將被分配到新的session窗口中去。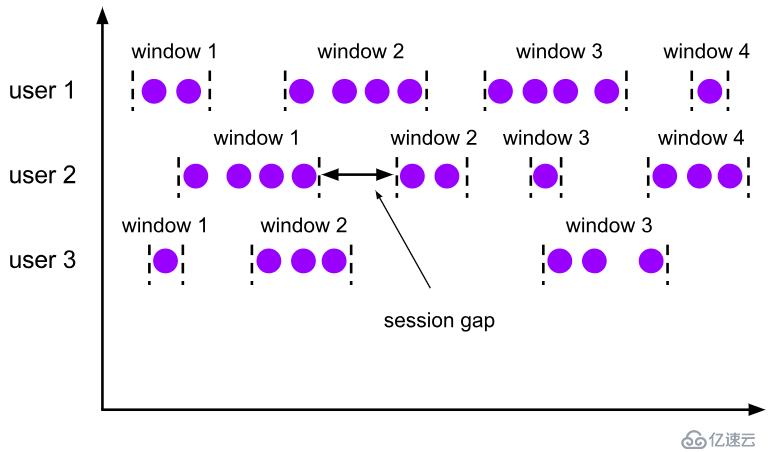
? 圖1.2.3 會話窗口
window數據源分為兩種,一種是典型的KV類型(keyedStream),另一種是非KV類型(Non-keyedStream)。
區別:
keyedStream:
需要在使用窗口操作前,調用 keyBy對KV按照key進行分區,然后才可以調用window操作的api,比如 countWindow,timeWindow等
Non-keyedstream:
如果使用窗口操作前,沒有使用keyBy算子,那么就認為是Non-keyedstream,調用的window api就是 xxxWindowAll,比如countWindowAll,timeWindowAll,而且因為是非KV,所以無法分區,也就是只有一個分區,那么這個窗口并行度只能是1。這個是要注意的。
CountWindow根據窗口中相同key元素的數量來觸發執行,執行時只計算元素數量達到窗口大小的key對應的結果。
有兩個用法:
countWindow(window_size):只指定窗口大小,此時窗口是滾動窗口
countWindow(window_size, slide):指定窗口大小以及滑動間隔,此時窗口是滑動窗口注意:CountWindow的window_size指的是相同Key的元素的個數,不是輸入的所有元素的總數。
1、滾動窗口
默認的CountWindow是一個滾動窗口,只需要指定窗口大小即可,當元素數量達到窗口大小時,就會觸發窗口的執行。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.readTextFile("/test.txt");
source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String s1 : s.split(" ")) {
collector.collect(new Tuple2<>(s1, 1));
}
}
}).keyBy(0).countWindow(5).reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return new Tuple2<>(t1.f0, t1.f1 + t2.f1);
}
}).print();
env.execute("滾動窗口");
}
}2、滑動窗口
動窗口和滾動窗口的函數名是完全一致的,只是在傳參數時需要傳入兩個參數,一個是window_size,一個是sliding_size。
下面代碼中的sliding_size設置為了2,也就是說,每收到兩個相同key的數據就計算一次,每一次計算的window范圍是5個元素。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.readTextFile("/test.txt");
source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String s1 : s.split(" ")) {
collector.collect(new Tuple2<>(s1, 1));
}
}
}).keyBy(0).countWindow(5,2).reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return new Tuple2<>(t1.f0, t1.f1 + t2.f1);
}
}).print();
env.execute("滑動窗口");
}
}? TimeWindow是將指定時間范圍內的所有數據組成一個window,一次對一個window里面的所有數據進行計算。同樣支持類似上面的滾動窗口和滑動窗口模式。有兩個工作參數:window_size和slide。只指定window_size時是滾動窗口。
1、滾動窗口
? Flink默認的時間窗口根據Processing Time 進行窗口的劃分,將Flink獲取到的數據根據進入Flink的時間劃分到不同的窗口中。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.readTextFile("/test.txt");
source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String s1 : s.split(" ")) {
collector.collect(new Tuple2<>(s1, 1));
}
}
}).keyBy(0).timeWindow(Time.seconds(2)).reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return new Tuple2<>(t1.f0, t1.f1 + t2.f1);
}
}).print();
env.execute("滾動窗口");
}
}2、滑動窗口
和上面類似,就是參數里面增加了slide參數,也就是滑動時間間隔。時間間隔可以通過Time.milliseconds(x),Time.seconds(x),Time.minutes(x)等其中的一個來指定。
也就是在窗口算子之后執行reduce算子,用法和普通的reduce一樣,只不過reduce的單位是一個窗口。即每一個窗口返回一次reduce結果。程序在上面,不重復了。
也就是在窗口算子之后執行fold算子,用法和普通的fold一樣,只不過fold的單位是一個窗口。即每一個窗口返回一次reduce結果。程序在上面,不重復了。
指的是max、min等這些聚合算子,只不過是在window算子之后使用,以窗口為單位,每一個窗口返回一次聚合結果,而不是像普通那樣,每一次聚合結果都返回。
在flink中,time有不同分類,如下:
Event Time:
是事件創建的時間。它通常由事件中的時間戳描述,例如采集的日志數據中,每一條日志都會記錄自己的生成時間,Flink通過時間戳分配器訪問事件時間戳。
Ingestion Time:
是數據進入Flink的時間。
Processing Time:
是每一個執行基于時間操作的算子的本地系統時間,與機器相關,默認的時間屬性就是Processing Time。也就是數據被處理時的當前時間。
這些時間有什么不同呢?因網絡傳輸需要時間,所以Ingestion Time不一定和Event Time相等,很多情況下是不等的。同樣Processing Time表示數據處理時的時間,如果數據是很久之前采集的,現在才處理,那么很明顯,三個時間time都不會相等的。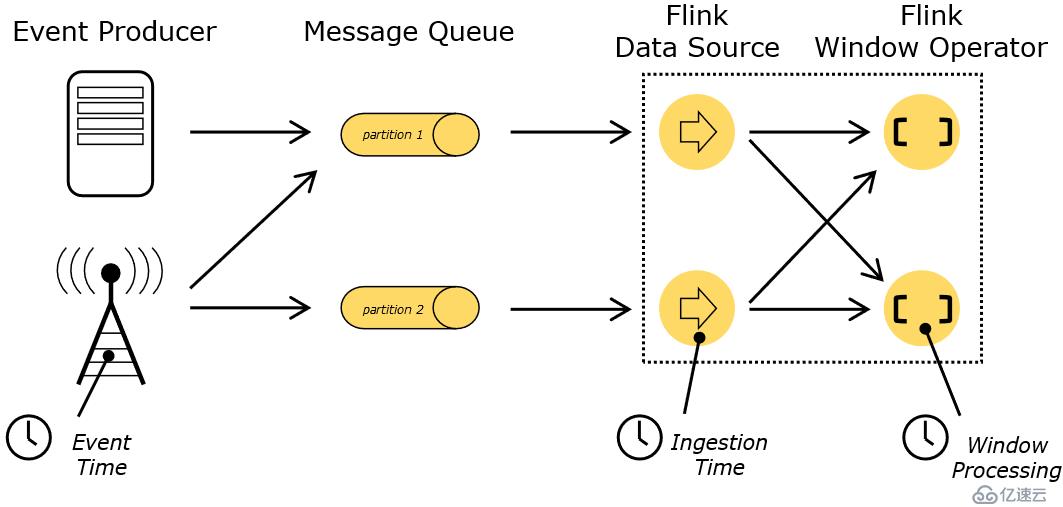
? 圖 2.1 flink--時間的概念
例子:
一條日志進入Flink的時間為2017-11-12 10:00:00.123,到達Window的系統時間為2017-11-12 10:00:01.234,日志的內容如下:
2017-11-02 18:37:15.624 INFO Fail over to rm2
可以看到,三個time都不相等。而對于業務來說,要統計1min內的故障日志個數,哪個時間是最有意義的?—— eventTime,因為我們要根據日志的生成時間進行統計。但是flink默認的窗口的時間是Processing Time,那么如何引入eventTime呢?
? 在Flink的流式處理中,絕大部分的業務都會使用eventTime,一般只在eventTime無法使用時,才會被迫使用ProcessingTime或者IngestionTime。默認使用的是ProcessingTime。那么如何指定flink使用指定的time呢?
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(時間類型);
//三種類型的time對應如下:
TimeCharacteristic.EventTime; eventtime
TimeCharacteristic.IngestionTime; 到達flink的時間
TimeCharacteristic.ProcessingTime; 處理數據的時間這種方式是整個env全局生效的,是直接將env默認的時間設置為eventtime。后面的窗口操作默認就會使用eventtime作為時間依據。如果想不同的窗口設置不同的時間類型,這種方式就行不通了。
stream.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.window這個api就是所有窗口總的api,其他窗口api都是通過這個api封裝出來的。可以通過這個總api,參數直接窗口的類型,比如上面的就是指定eventtime 的timewindow,這樣并不會影響整個env的時間類型。
同樣的,其他時間類型窗口,比如:
SlidingEventTimeWindows 滑動eventtime窗口
基本上看名字就知道是什么時間類型(三大時間類型)、以及什么類型(滑動、滾動、會話窗口)的窗口了。注意:eventtime沒有session窗口,processingTime和? 我們知道,流處理從事件產生,到流經source,再到operator,中間是有一個過程和時間的,雖然大部分情況下,流到operator的數據都是按照事件產生的時間順序來的,但是也不排除由于網絡、背壓等原因,導致亂序的產生,所謂亂序,就是指Flink接收到的事件的先后順序不是嚴格按照事件的Event Time順序排列的。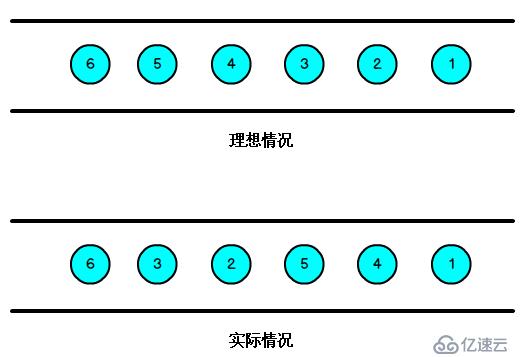
? 圖 2.3 數據的亂序
? 那么此時出現一個問題,一旦出現亂序,如果只根據eventTime決定window的運行,我們不能明確數據是否全部到位,但又不能無限期的等下去,此時必須要有個機制來保證一個特定的時間后,必須觸發window去進行計算了,這個特別的機制,就是Watermark。
解釋:
如果只按照到達的event的eventtime來觸發窗口操作,假設有event1~5。如果到達順序是亂的,比如event5最先達到,然后event1也達到了,那么flink這邊怎么知道這中間還有沒有數據呢?沒辦法的,不能確定數據是否完整到達,也不能無限制等待下去。所以需要一種機制來處理這種情況。
? Watermark是一種衡量Event Time進展的機制,它是數據本身的一個隱藏屬性,數據本身攜帶著對應的Watermark。Watermark是用于處理亂序事件的,而正確的處理亂序事件,通常用Watermark機制結合window來實現。
? 數據流中的Watermark用于表示timestamp小于Watermark的數據,都已經到達了,因此,window的執行也是由Watermark觸發的。
? Watermark可以理解成一個延遲觸發機制,我們可以設置Watermark的延時時長t,每次系統會校驗已經到達的數據中最大的maxEventTime,然后認定eventTime小于maxEventTime - t的所有數據都已經到達,如果有窗口的停止時間等于maxEventTime – t,那么這個窗口被watermark觸發執行。
解釋:
? watermark是一種概率性的機制。假設event1~5,如果event5已經到達了,那么其實按照event產生的先后順序,正常情況下,前面的event1~4應該也到達了。而為了保證前面的event1~4的到達(其實是更多的到達,但是不一定全部都到達),在event5到達了之后,提供一定的延遲時間t。當event5到達,且經過 t 時間之后,正常情況下,前面的event1~4 大概率會到達了,如果沒有到達,屬于少數情況,那么就認為event5之前的event都到達了,無論是否真的全部到達了。如果在延遲時間之后到達了,這個舊數據直接會被丟棄。所以其實watermark就是一種保障更多event亂序到達的機制,提供了一定的延時機制,而因為只會延遲一定的時間,所以也不會導致flink無限期地等待下去。
有序數據流的watermark如下:(watermark設置為0)
? 圖 2.4 有序數據流的watermark
亂序數據流的watermark如下:(watermark設置為2)
? 圖 2.5 亂序數據流的watermark
? 當Flink接收到每一條數據時,都會產生一條Watermark,這條Watermark就等于當前所有到達數據中的maxEventTime - 延遲時長t,也就是說,Watermark是由數據攜帶的,一旦數據攜帶的Watermark比當前未觸發的窗口的停止時間要晚,那么就會觸發相應窗口的執行。由于Watermark是由數據攜帶的,因此,如果運行過程中無法獲取新的數據,那么沒有被觸發的窗口將永遠都不被觸發。
? 上圖中,我們設置的允許最大延遲到達時間為2s,所以時間戳為7s的事件對應的Watermark是5s,時間戳為12s的事件的Watermark是10s,如果我們的窗口1是1s~5s,窗口2是6s~10s,那么時間戳為7s的事件到達時的Watermarker恰好觸發窗口1,時間戳為12s的事件到達時的Watermark恰好觸發窗口2。
? Window會不斷產生,屬于這個Window范圍的數據會被不斷加入到Window中,所有未被觸發的Window都會等待觸發,只要Window還沒觸發,屬于這個Window范圍的數據就會一直被加入到Window中,直到Window被觸發才會停止數據的追加,而當Window觸發之后才接受到的屬于被觸發Window的數據會被丟棄。如果產生的窗口中沒有新到的數據,也就不會有watermark,那么窗口就不會被觸發計算。
watermark時間(max_eventTime-t) >= window_end_time;
在[window_start_time,window_end_time)中有數據存在。
Punctuated:不間斷產生
數據流中每一個遞增的EventTime都會產生一個Watermark。
在實際的生產中Punctuated方式在TPS很高的場景下會產生大量的Watermark在一定程度上對下游算子造成壓力,所以只有在實時性要求非常高的場景才會選擇Punctuated的方式進行Watermark的生成。
Periodic:周期性產生
周期性的(一定時間間隔或者達到一定的記錄條數)產生一個Watermark。
在實際的生產中Periodic的方式必須結合時間和積累條數兩個維度繼續周期性產生Watermark,否則在極端情況下會有很大的延時。
這兩種有不同的api實現,下面會講
需要先引入eventime,然后引入watermark
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource<String> source = env.readTextFile("/test.txt");
//引入的watermark的實現類
source.assignTimestampsAndWatermarks(xx)watermark的實現有兩大類,對應上面的兩種watermark的產生方式,有兩個接口:
AssignerWithPeriodicWatermarks; 周期性產生watermark,即Period
AssignerWithPunctuatedWatermarks; Punctuated:不間斷產生看看AssignerWithPeriodicWatermarks這個接口的源碼,主要用于周期性產生watermark
public interface AssignerWithPeriodicWatermarks<T> extends TimestampAssigner<T> {
//獲取當前的watermark
@Nullable
Watermark getCurrentWatermark();
}
//父接口===================
public interface TimestampAssigner<T> extends Function {
//獲取當前的時間戳
long extractTimestamp(T var1, long var2);
}主要就是有兩個方法需要覆蓋,getCurrentWatermark()用于生成watermark,extractTimestamp用于獲取每個event的timestamp。
由于這是一個周期性產生watermark的接口,所以需要指定這個生成周期有多長,需要env的配置中指定,如:
env.getConfig().setAutoWatermarkInterval(n ms);
記住間隔時間單位是毫秒例子:
/*根據eventTime 創建處理watermark
*/
public class BoundedOutOfOrdernessGenerator implements AssignerWithPeriodicWatermarks<MyEvent> {
//watermark延遲時間 t,單位是毫秒
private final long maxOutOfOrderness = 3500; // 3.5 seconds
//保存當前最大的時間戳
private long currentMaxTimestamp;
//根據傳遞進來的event,獲取time,然后如果比當前最大的time還大,就替換,否則保持。因為數據亂序到達是無法保證時間是遞增的
@Override
public long extractTimestamp(MyEvent element, long previousElementTimestamp) {
long timestamp = element.getCreationTime();
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
return timestamp;
}
//返回watermark
@Override
public Watermark getCurrentWatermark() {
// return the watermark as current highest timestamp minus the out-of-orderness bound
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
}再加上設置的setAutoWatermarkInterval(n ms),就可以周期性生成watermark。
看看AssignerWithPunctuatedWatermarks這個接口的源碼,主要用于實時產生watermark
public interface AssignerWithPunctuatedWatermarks<T> extends TimestampAssigner<T> {
//獲取最新的watermark
@Nullable
Watermark checkAndGetNextWatermark(T var1, long var2);
}
//父接口
public interface TimestampAssigner<T> extends Function {
//從event中獲取timestamp
long extractTimestamp(T var1, long var2);
}寫法其實和上面的類似,只是這里不會設置生成watermark的時間間隔
1、BoundedOutOfOrdernessTimestampExtractor
繼承了AssignerWithPeriodicWatermarks接口的一個類,看看它的源碼
package org.apache.flink.streaming.api.functions.timestamps;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.api.windowing.time.Time;
public abstract class BoundedOutOfOrdernessTimestampExtractor<T> implements AssignerWithPeriodicWatermarks<T> {
private static final long serialVersionUID = 1L;
private long currentMaxTimestamp;
private long lastEmittedWatermark = -9223372036854775808L;
private final long maxOutOfOrderness;
//構造方法中接收一個參數,就是延遲時間 t
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0L) {
throw new RuntimeException("Tried to set the maximum allowed lateness to " + maxOutOfOrderness + ". This parameter cannot be negative.");
} else {
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = -9223372036854775808L + this.maxOutOfOrderness;
}
}
public long getMaxOutOfOrdernessInMillis() {
return this.maxOutOfOrderness;
}
//需要重寫的方法,用于獲取timestamp
public abstract long extractTimestamp(T var1);
//獲取watermark的方法已經寫好了,用傳遞進來的延遲時間t來計算得出watermark
public final Watermark getCurrentWatermark() {
long potentialWM = this.currentMaxTimestamp - this.maxOutOfOrderness;
if (potentialWM >= this.lastEmittedWatermark) {
this.lastEmittedWatermark = potentialWM;
}
return new Watermark(this.lastEmittedWatermark);
}
public final long extractTimestamp(T element, long previousElementTimestamp) {
long timestamp = this.extractTimestamp(element);
if (timestamp > this.currentMaxTimestamp) {
this.currentMaxTimestamp = timestamp;
}
return timestamp;
}
}這個類就是實現了用戶可以自定義設定延遲時間t 的一個watermark。
2、AscendingTimestampExtractor
也是繼承了AssignerWithPeriodicWatermarks接口的一個類。具有穩定的遞增時間戳的數據源,比如kafka的分區數據,每一條信息都是遞增+1的,適用于這個類。只需要重寫
extractAscendingTimestamp方法。
package flinktest;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class EventTimeTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.getConfig().setAutoWatermarkInterval(1000);
DataStreamSource<String> source = env.readTextFile("/tmp/test.txt");
source.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.milliseconds(3000)) {
@Override
public long extractTimestamp(String s) {
return Integer.valueOf(s.split(" ")[0]);
}
}).flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
Tuple2<String, Integer> tmpTuple = new Tuple2<>();
for (String s1 : s.split(" ")) {
tmpTuple.setFields(s1, 1);
collector.collect(tmpTuple);
}
}
}).keyBy(0)
.timeWindow(Time.seconds(10))
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return new Tuple2<>(t1.f0, t1.f1 + t2.f1);
}
})
.print();
try {
env.execute("eventtime test");
} catch (Exception e) {
e.printStackTrace();
}
}
}window api的類繼承結構
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





