溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了tesseract-ocr使用及訓練的方法是什么的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇tesseract-ocr使用及訓練的方法是什么文章都會有所收獲,下面我們一起來看看吧。
Tesseract是一個開源的OCR(Optical Character Recognition,光學字符識別)引擎,可以識別多種格式的圖像文件并將其轉換成文本,目前已支持60多種語言(包括中文)。 Tesseract最初由HP公司開發,后來由Google維護,目前發布在Googel Project上。
安裝Tesseract,從http://code.google.com/p/tesseract-ocr/downloads/list下載Tesseract,3.01上的版本支持中文。安裝后在電腦上會有一個Tesseract-OCR目錄,通過目錄錄下的tesseract.exe程序就可以對圖像的字符進行識別。考慮到萬一有人上不了谷歌,這個Tesseract-OCR文件夾我也上傳了,地址:點擊打開鏈接。文件夾中除了Tesseract的相應文件外,還有一個tesseract-vs2013-include-lib-dll文件,這個是VS2013用來調用API的配置文件,后面的博客會寫到。打開如圖所示。
準備一張待識別的圖片,我選取一段《成都》的歌詞。

接著就可以打開命令行,進入Tesseract-OCR的目錄,輸入:
tesseract.exe gc.jpg result -l chi_sim
其中result表示輸出結果文件txt名稱,chi_sim表示用以識別的語言文件為英文。執行后文件夾中會多一個result.txt。

效果非常不好,因為很多漢字是左右結構,比如:眼淚。所以我要自己訓練自己的中文庫。
訓練樣本需要一個工具,jTessBoxEditor,下載地址:點擊打開鏈接。這個工具是用java開發的,需要jre7以上的版本支持。
1、獲取訓練的圖片,為了方便我使用了原來的圖片一張,樣本當然是越多越好。
2、合并樣本文件,打開jTessBoxEditor,點開train.bat。在菜單欄中Tools->Merge TIFF。在彈出的窗口中可以選擇多張樣本圖片(網上之前有說要.tif格式的圖片,測試.jpg格式的也行),我這邊就用了一張樣本圖片。
一張或者多張圖片可以合成一張tif文件。

3、生成box文件, 打開命令行,輸入:
tesseract.exe gc.font.exp1.tif gc.font.exp1 batch.nochop makebox
生成的BOX文件為gc.font.exp1.box,BOX文件為Tessercat識別出的文字和其坐標。Make BOX的命名的個數為:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang為語言名稱,fontname為字體名稱,num為序號,可以隨便定義。有些博客說對于這個命名無所謂,但是我嘗試到后免出錯了,是tr文件名的問題,在下面我會貼出報錯圖。讀者也可以試試,不知是不是我之前步驟哪里做錯了。
4、文字矯正,打開jTessBoxEditor工具,打開gc.font.exp1.tif文件(必須將上一步生成的.box和.tif樣本文件放在同一目錄),如下圖所示。可以看出有些字符分割和識別都不正確,可以通過該工具手動對每張圖片中識別錯誤的字符進行校正。校正完成后保存即可。(注:發現中文打不上去,在菜單Setting->Font中可以修改,改為宋體即可)
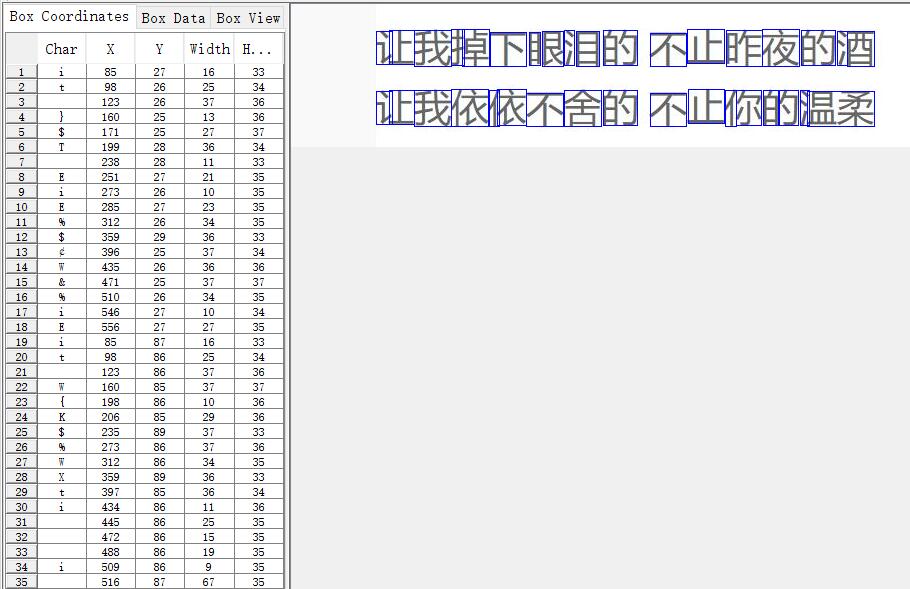
對于標定的方框以及識別的字符進行修改。

選擇兩個或兩個以上的框,Merge可進行合并;Split將框進行拆分;Insert插入框,如果圖片上一個框也沒有,那無法進行插入;Delete刪除框。選擇要修改的字符框,在Character中輸入想要修改的字,再點擊齒輪,即可修改。修改后,如下圖所示:
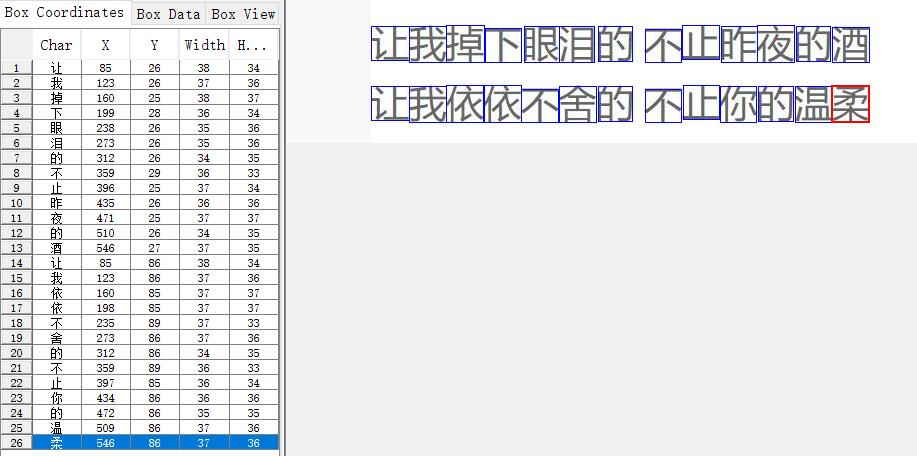
5、生成.tr文件,在命令行中輸入:
tesseract gc.font.exp1.tif gc.font.exp1 nobatch box.train
6、計算字符集,從生成的box文件中提取,繼續輸入:
unicharset_extractor gc.font.exp1.box
7、生成字體特征文件,在當前文件夾中新建任意名稱的文件,里面格式為:
<span><fontname> <italic> <bold> <fixed> <serif> <fraktur> </span>
例如:我建了一個名為font的文件,里面內容為:font 0 0 0 0 0
這個文件可以是手動生成的txt文件,也可以在在命令行中輸入:
echo font 0 0 0 0 0 >font
即可。
8、特征訓練,繼續在命令行輸入:
mftraining -F font -U unicharset gc.font.exp1.tr
在這一步我出現了好幾個錯誤,如下圖
(1)Failed to load unicharset from file uncharset,這是因為剛剛的font的文件,如果是在txt中寫的,一定要寫成font.txt,加上后綴。

(2)feature training for Tesseract已停止工作。命令行顯現:
Reading num.tr …
Font id = -1/0, class id = 1/13 on sample 0
font_id >= 0 && font_id < font_id_map_.SparseSiz..\..\classify\trainingsampleset.cpp, line 622
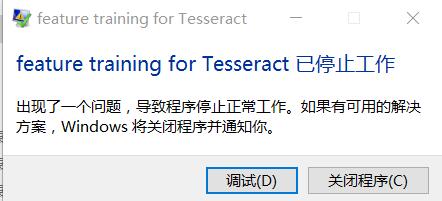
這個問題就是上面命名所導致的,所以還是規范命名。
9、聚集tesseract識別的訓練文件,命令行輸入:
cntraining gc.font.exp1.tr
有人會說其他還有一條shapeclustering語句,說下這個步驟可有可無,這個是在3.02中新加的,主要針對印度語,所以我們在做的時候會有一個警告 warning No shape table file present。
這時候文件夾中會多了四個文件,在unicharset,inttemp,normproto,pfftable文件名前面加上font.。如下圖所示: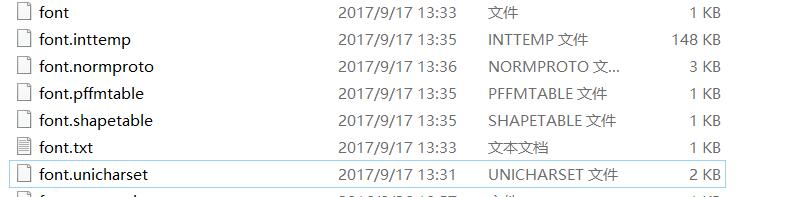
10、最后,合并相關文件,生成字典文件,輸入:
combine_tessdata font.
所有輸入命令如下圖所示
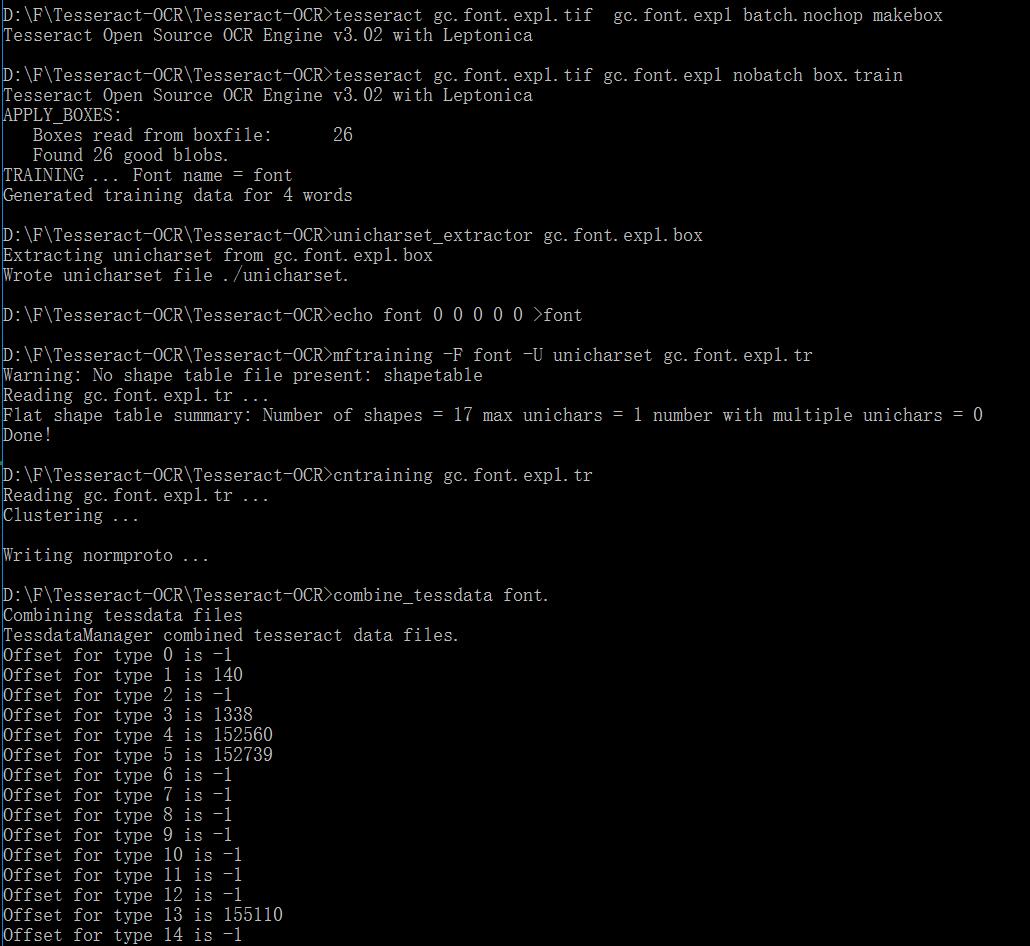
最終,在當前目錄中會產生一個為font.traineddata文件,將其拷到tessdata文件夾中,再測試一下。

關于“tesseract-ocr使用及訓練的方法是什么”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“tesseract-ocr使用及訓練的方法是什么”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





