溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“MySQL索引創建原則是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
根據Alibaba規范,指明在業務上具有唯一特性的字段,即使是組合字段,也必須建成唯一索引。

例如,學生表中的學號時具有唯一性的字段,為該字段建立唯一性索引可以快速查詢出某個學生的信息,如果使用姓名的話,可能存在同名的情況,從而降低查詢速度。
某個字段在Select語句的Where條件中經常被使用到,那么就需要給這個字段創建索引,尤其實在數據量大的情況下,創建普通索引就可以大幅提升查詢效率。
比如測試表student_info有100萬數據,假設查詢student_id=112322的用戶信息,如果沒有對student_id字段創建索引,查詢結果如下:
select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花費211ms

為student_id創建索引后,查詢結果如下:
alter table student_info add index idx_sid(student_id); select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花費3ms

索引就是讓數據按照某種順序進行存儲或檢索,因此當使用Group by對數據進行分組查詢或使用Order by對數據進行排序的時候 ,就需要對分組或排序的字段進行索引。如果待排序的列有多個,那可以在這些列上建立組合索引。
比如,按照student_id對學生選秀的課程進行分組,顯示不同的student_id和課程的數量,顯示100條。如果不對student_id創建索引,查詢結果如下:
select student_id,count(*) as num from student_info group by student_id limit 100;#花費2.466s
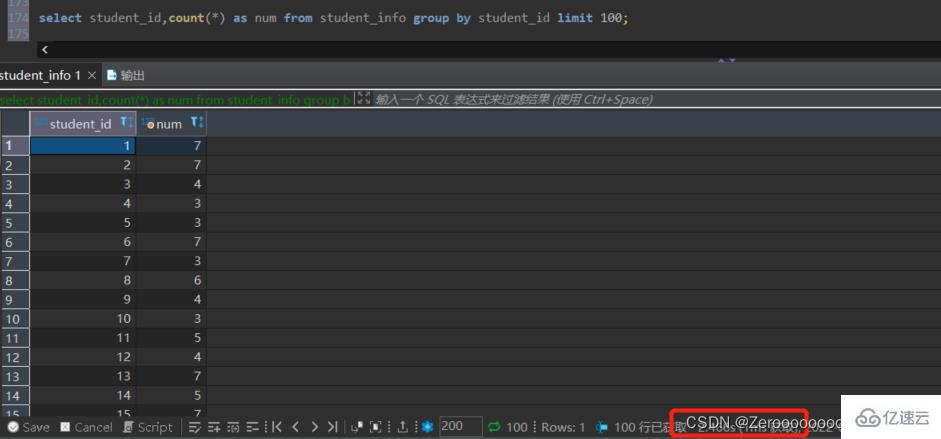
為student_id創建索引后,查詢結果如下:
alter table student_info add index idx_sid(student_id); select student_id,count(*) as num from student_info group by student_id limit 100;#花費6ms

對于既有group by又有order by的查詢語句,建議最好建立聯合索引,并且將group by中的字段放到order by字段的前邊,滿足‘最左前綴匹配原則’,這樣索引的利用率就會高,自然查詢的效率也就會高;同時8.0之后的版本支持降序索引,如果order by之后的字段時降序的,可以考慮直接創建降序索引,也會提高查詢效率。
對數據按照某個條件進行查詢后再進行Update或Delete的操作,如果對Where字段創建了索引,就能答復提升效率。原因是因為需要先根據Where條件列檢索出來這條記錄,然后再對他進行更新或刪除。如果進行更新的時候,更新的字段是非索引字段,提升效率會更明顯,這是因為費索引字段更新不需要對所以進行維護。
比如對student_info表中的name字段為sdfasdfas123123的數據修改student_id為110119,在沒有對name字段建立索引的情況下,執行情況如下:
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花費549ms
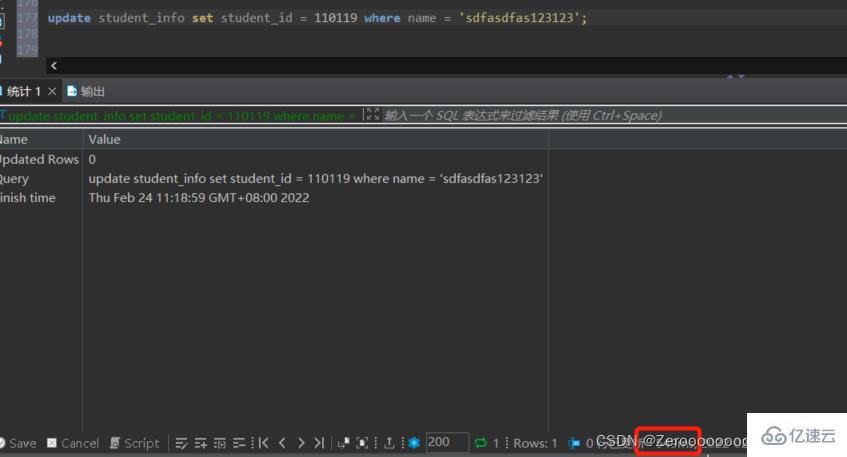
添加索引后,執行情況如下:
alter table student_info add index idx_name(name); update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花費2ms
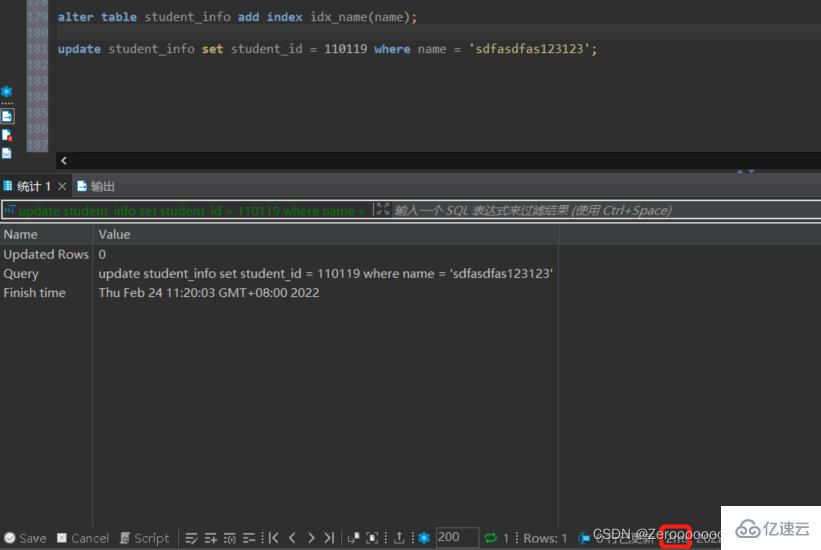
有時候需要對某個字段進行去重,使用Distinct,那么對這個創建索引也會提升查詢效率。
比如查詢課程表中不同student_id都有哪些,如果沒有為student_id創建索引,執行情況如下:
select distinct(student_id) from student_id;#花費2ms
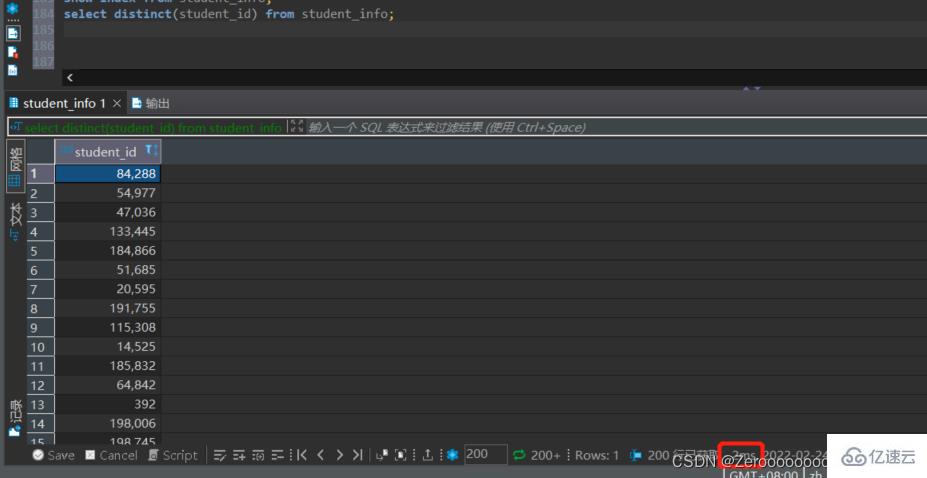
創建索引后,執行情況如下:
alter table student_info add index idx_sid(student_id); select distinct(student_id) from student_id;#花費0.1ms
首先,連接表的數據量盡量不超過3張,因為每增加一張表就相當于增加了一次嵌套的循環,數量級增長非常快,嚴重影響查詢效率。其次,對Where條件創建索引,因為Where才是對數據條件的過濾,如果再數據量非常大的情況下,沒有Where條件過濾時非常可怕的,最后,對于連接的字段創建索引,并且改字段再多張表中類型必須一致。

比如,只對student_id創建索引,查詢結果如下:
select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花費176ms
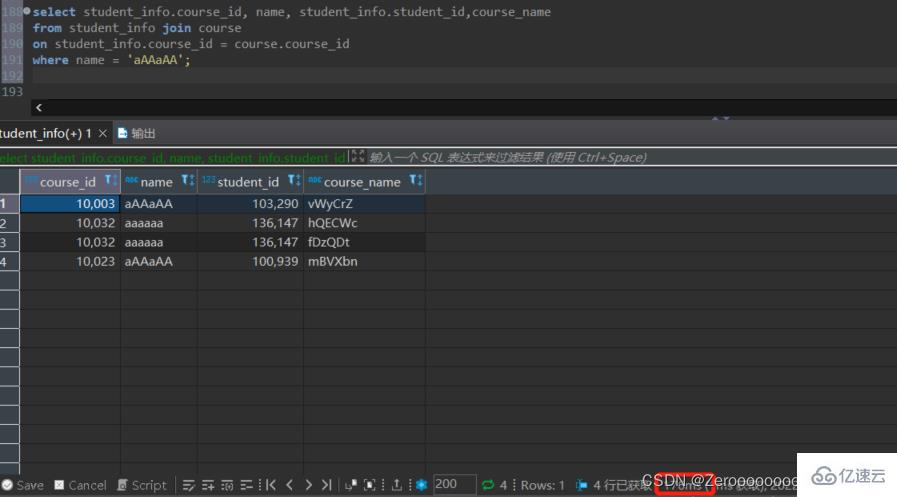
給name字段創建索引后,查詢結果如下:
alter table student_info add index idx_name(name); select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花費2ms

這里所說的類型小值意思是該類型表示的數據范圍的大小。比如在定義表結構的時候要顯示的指定列的類型,以整數類型為例,有TINYINT、MEDIUMINT、INT、BIGINT等,他們占用的存儲空間依次遞增,能表示的數據范圍也是一次遞增。如果相對某個整數列建立索引的話,在表示的整數范圍允許的情況下,盡量讓索引列使用較小的類型,例如能使用INT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
數據類型越小,在查詢時進行的比較操作越快
數據類型越小,索引占用的空間就越少,在一個數據頁內就可以存下更多的記錄,從而減少磁盤I/O帶來的性能損耗,也就意味著可以存儲更多的數據在數據頁中,提高讀寫效率。
上述對于主鍵來說很合適,因為在聚簇索引中既存儲了數據,也存儲了索引,可以很好的減少磁盤I/O;而對于二級索引來說,還需要一次回表操作才能查到完整的數據,也就能加了一次磁盤I/O。
根據Alibaba開發手冊,在字符串上建立索引時,必須指定索引長度,沒有必要對全字段建立索引。

比如有一張商品表,表中的商品描述字段較長,在描述字段上建立前綴索引如下:
create table product(id int, desc varchar(120) not null); alter table product add index(desc(12));
區分度的計算可以使用count(distinct left(列名, 索引長度))/count(*)來確定。
列的基數值得時某一列中不重復數據的個數,比如說某個列包含值2,5,3,6,2,7,2,雖然有7條記錄,但該列的基數卻是5,也就是說,在記錄行數一定的情況下,列的基數越大,該列中的值就越分散;列的基數越小,該列中的值就越集中。這里列的基數指標非常重要,直接影響是否能有效利用索引。最好為列的基數大的列建立索引,為基數太小的列建立索引效果反而不好。
可以使用公式select count(distinct col)/count(*) from table 來計算區分度,越接近1區分度越好。
這條就是通常說的最左前綴匹配原則。 通俗來講就是將Where條件后經常使用的條件字段放在索引的最左邊,將使用頻率相對低的放到右邊。
通常索引的建立是有代價的,如果建立索引的字段沒有出現在where條件(包括group by、order by)中,建議一開始就不要創建索引或將索引刪除,因為索引的存在也會占用空間。
在條件表達式中經常用到的不同值較多的列上建立索引,但字段中如果有大量重復數據,也不用創建索引。比如學生表中的性別字段,只有男和女兩種值,因此無需建立索引。如果建立索引,不但不會提高查詢效率,反而會嚴重降低數據更新速度。
4、避免對經常更新的表創建過多的索引
頻繁更新的字段不一定要創建索引,因為更新數據的時候,索引也要跟著更新,如果索引太多,更新的時候會造成服務器壓力,從而影響效率。
避免對經常更新的表創建過多的索引,并且索引中的列盡可能少。此時雖然提高了查詢速度,同時也會降低更新表的速度。
例如身份證、UUID(在索引比較時需要轉為ASCII,并且插入時可能造成頁分裂)、MD5、HASH、無序長字符串等。
表中的數據被大量更新或者數據的使用方式被改變后,原有的一些索引可能不會被使用到。DBA應定期找出這些索引并將之刪除,從而較少無用索引對更新操作的影響。
例如身份證、UUID(在索引比較時需要轉為ASCII,并且插入時可能造成頁分裂)、MD5、HASH、無序長字符串等。
表中的數據被大量更新或者數據的使用方式被改變后,原有的一些索引可能不會被使用到。DBA應定期找出這些索引并將之刪除,從而較少無用索引對更新操作的影響。
“MySQL索引創建原則是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





