溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Go語言進階freecache源碼分析”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Go語言進階freecache源碼分析”文章能幫助大家解決問題。
freecache 是一個用 go 語言實現的本地緩存系統(類似于 lru)。
它有幾個特性值得注意:
通過優秀的內存管理方案,實現了 go 語言的零 gc
是線程安全的,同時支持一定程度的并發,非常適合并發場景
支持設置失效時間,動態失效過期緩存
在一定程度上支持 lru,即“最近最少使用”,會在容量不足的時候優先淘汰較早的數據
這幾個優秀特性使得他非常適合用在生產環境中作為本地緩存。
cacheSize := 100 * 1024 * 1024
cache := freecache.NewCache(cacheSize)
debug.SetGCPercent(20)
key := []byte("abc")
val := []byte("def")
expire := 60 // expire in 60 seconds
cache.Set(key, val, expire)
got, err := cache.Get(key)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(string(got))
}
affected := cache.Del(key)
fmt.Println("deleted key ", affected)
fmt.Println("entry count ", cache.EntryCount())本文計劃先以自然語言描述下列功能的實現方式,再接下來的章節中深入源碼,扒出其具體實現
如何做到零 gc?
數據結構
動態索引
緩存失效
這個庫之所以做到了 0 gc,是因為設定了很巧妙的數據結構,這個數據結構有以下的特點:
無論存多少數據,都只會存在 512 個指針
所有的具體數據的存儲空間,都是預先就分配好的,而不是動態分配的
使用了一些黑科技,比如強制類型轉換以及結構體對齊等技術,將所有的動態數據都管理在預先分配好的連續空間內
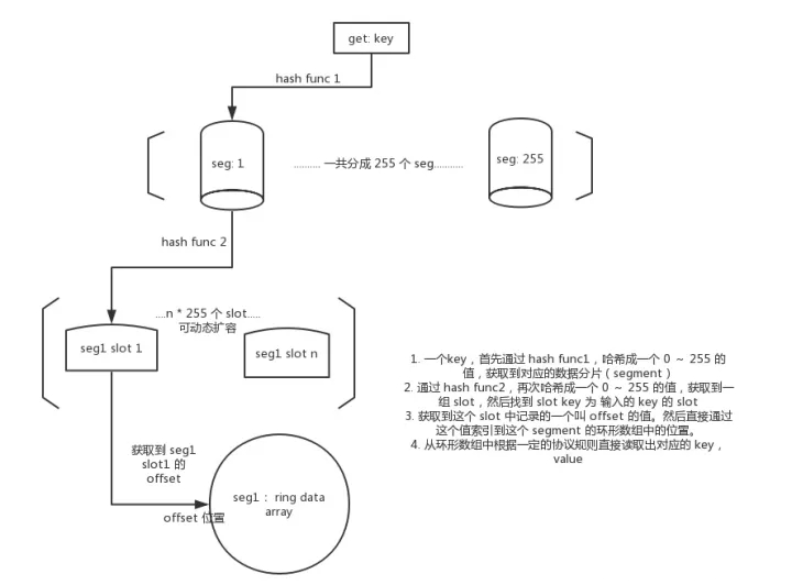
可以將這個數據結構大體上抽象成一個哈希表。即你會看到哈希函數以及對應的數組空間。但是他和傳統的哈希表是有區別的,主要有以下幾點:
線程安全,支持高并發,內存空間高度優化:
為了做到支持高并發以及線程安全,并且保證內存空間的可用性,freecache 實際上劃分出了 256 個獨立數組空間用來存儲對應的底層數據。
這樣在并發訪問的時候,通過對 key 進行分片,使得請求只會打到一個數組空間上,即只會對這 256 個空間中的一個空間加鎖,這樣就大大降低了資源爭搶。
數據的組織方式與傳統哈希表不同:
傳統的哈希表只在數組空間中存 value。而 freecache 則不同,他將 key,value 全部存在了數組空間中。
傳統哈希表的數組是稀疏的。freecache 數據并不是稀疏的,而是連續的,即新的值會不斷 append 到最后。
傳統哈希表使用 hash func 對 key 取索引,索引到稀疏數組中的位置。而 freecache 則通過維護了一個叫“slot(插槽)”的數據結構,通過對 key 進行 hash func,先拿到對應的 slot,然后 slot 中維護著一個索引,可以定位到具體的數據在數組中的位置。
解決哈希沖突的方式不同。當遇到哈希沖突的時候,哈希表需要對底層的稀疏數組進行擴容,會導致可用性大大降低。而 freecache 則是只需要對“slot”的指針數組進行擴容,而無需改變底層數組。因為 slot 指針數組的大小遠小于底層數組,所以擴容的成本是非常非常低的。
為了實現緩存淘汰以及定時失效,它的數組空間在邏輯上是一個環狀的。這么做有以下原因
數組存的數據邏輯上是連續的,而非稀疏數組。充分利用了CPU對數組讀取的緩存優化
通過使用了一系列的首尾計算方式,是足以保證讀取和存儲在首尾的連續性。比如讀數據的時候讀到結尾如果還沒讀完,會跳轉到頭部繼續往下讀。
能以 O(1) 的時間復雜度完成新數據對舊數據的淘汰。我們假設如果數組在邏輯上不是環形的,那么當數組寫滿的時候再寫入新的數據,就需要把數組頭部的數據刪除掉,然后再把之后的數據統統向左移動刪除數據的長度,然后再從最右端寫入新的數據。反之,如果數組是環形的,只需要在數組頭部把舊數據覆蓋即可
通過一些算法手段,可以實現一個很 hack 的 lru 功能。在一定程度上能保證“最近最少使用”的淘汰。
通過上面對數據結構的分析,我們知道他和傳統的哈希表的實現方式大相徑庭。它實際上是使用了一種叫“插槽”的數據結構,專門負責通過 key 索引到數據空間中的某個位置。他的實現比較有意思。它的底層是一個結構體指針數組。他是可以動態擴容的。每個插槽有一個 id,叫 slotId,范圍是 0~255。當遇到哈希沖突的時候,比如出現了2個 slotId 為 100 的 slot,他就會檢測當前的最大重復 slotID 數量 n。如果這個 2 大于 n,他就會擴容到 2n。
// slot 的數據結構
type entryPtr struct {
offset int64 // 記錄了當前 slot 在環形數組中的偏移量
hash26 uint16 // 一個 hash 值,用于在 segment 中定位到具體的 slot
keyLen uint16 // used to compare a key
reserved uint32
}
// 每個分片的數據結構
type segment struct {
rb RingBuf // 環形數組
segId int
hitCount int64
missCount int64
entryCount int64
totalCount int64 // 之后計算 lru 的時候會用到,用于衡量一個數據是否是熱點數據
totalTime int64 // 之后計算 lru 的時候會用到,用于衡量一個數據是否是熱點數據
totalEvacuate int64 // used for debug
totalExpired int64 // used for debug
overwrites int64 // used for debug
vacuumLen int64 // 環形數組可用容量,主要用于環形數組首尾相接的算法
slotLens [256]int32 // 每個 slotId 的長度的數組
slotCap int32 // 每個 slotId 的容量
slotsData []entryPtr // 存儲 slots 的切片,根據 hash26 進行順序排列。相同的 hash26 擁有相同的 slotId
}緩存失效主要包括兩種:
基于過期時間的失效
基于最近最少使用的失效
這兩種失效都有缺陷。
首先它是一種被動失效,而不是通過一個額外的線程定期check。而是每次 set 新的值的時候,如果發現空間不夠用了,他才會嘗試從環形數組的頭端進行check。如果發現當前check的數據過期了,或者使用頻率過低,就會將記錄有效數據的頭指針進行偏移,即相當于“失效”。如果檢查多次都沒能找到需要失效的數據,那么他會將這些檢查過的數據轉移到尾部,并強制當前的頭部的數據失效。
這種失效是不可靠的。比如一個數據,如果在環形數組的中間,那么即便它過期了,也很難被 check 到。并且存在一定的失誤概率,即將一個熱點數據給失效了。
關于“Go語言進階freecache源碼分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





