溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“ChatGPT跨越認知邊界實例分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“ChatGPT跨越認知邊界實例分析”吧!
我的有的朋友跟我說,用ChatGPT編程需要你至少要跟他對等水平,因為現階段我們還不能做到完全不需要關心它寫出來的代碼,當你要讀懂它寫的代碼的時候,就必須能力對等。還有的朋友跟我說,ChatGPT的不能超過你的認知水平,你的認知水平的上限決定了它的表現,比如你認知水平不行,導致自己不能分解任務的時候,那么你用ChatGPT也寫不出代碼。
上面說的都沒錯,但是如果是以往的工具,它可能到這里就會出現一種分層。這種分層就會導致人和人的差距的鴻溝在企業里可能就會變成一種劃分職級的邊界。但是ChatGPT跟以往的工具都不同,以往的工具他沒有辦法提升你的認知,沒有辦法提升你的水平。但是ChatGPT可以扮演多種角色,除了當一個生產工具之外,它還可以當一個教學工具。也就是說,當你進入到了一種低認知的狀態,他可以立刻轉變為教學工具,讓你通過學習進入高認知狀態,提升你的水平。然后你就又可以一種較高認知的水準進行工作了。
舉個例子,在我們的這個程序里:
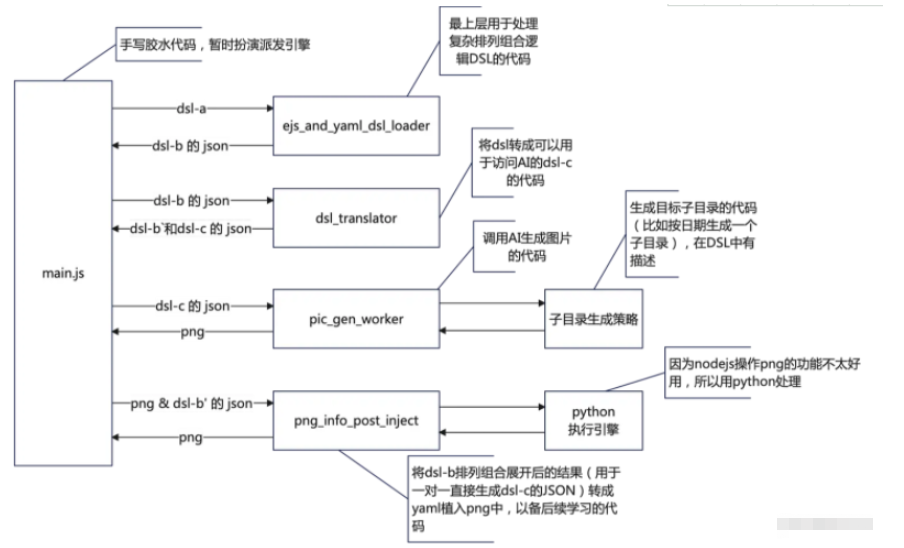
開發最后的png_info_post_inject模塊時,我其實并不會操作png的內嵌信息,以前也沒有過類似的經驗。所以一開始,我只是想當然的認為nodejs應該可以吧。所以我問了他很多的問題,做了很多的設計,甚至改了很多遍。就是想讓他用Node.js給我做出來。經過一系列的嘗試之后,果然就失敗了。(主要是我用的AI自己會在圖片里留一些信息,我又不想覆蓋掉,我還想它的信息和我的信息在作圖AI的軟件里都能被看到。)我又讓他給了我其他的庫或原生的寫法,都不太好用。由于我太有自信了,所以這個過程中我全程TDD,為了搭建這個測試環境還浪費了我很多時間。
然后在這個時候我就進入了一種迷茫的狀態。我不知道該怎么辦了。
幸好我現在的工具是個人工智能。所以我問他:

嗯……Python,我的畫圖AI也是用的python,這個應該可行。但是這回我學聰明了。我并不直接開始TDD。我先建了個spike文件夾。也就是調研用的。這里的代碼呢只是做一個嘗試。并不真正作為產品代碼使用。
其實這個動作在TDD里面也是被講究的,你應該先調研,調研完了之后再來tdd。你不應該帶著對某一個知識點的不理解工作,并且在你的代碼里邊試驗邊學習一個知識點。這種做法非常常見,但是其實是反模式。因為你的代碼里往往都有各種各樣的其他無關因素,造成了你的學習效率不高。學習一個知識點和將這個知識點用于工作,應該是兩個階段。
所以接下來我是這么做的。我新建了一個spike文件夾。然后開始在里面實驗我的代碼這個spike文件夾我有可能最終是不會提交到代碼庫的。
然后我在里面準備了一張test.png
然后調研用python來訪問png,但是我畢竟不太了解這個領域,我決定開始之前double check以下,我又問了一遍
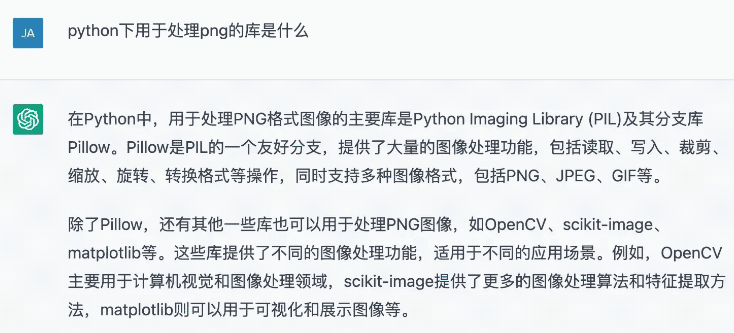
hmm……果然有點小坑,也不知道哪個是哪個,看起來PIL更基礎一點,行吧,我的功能不復雜,可能PIL就夠用了。
于是我問:
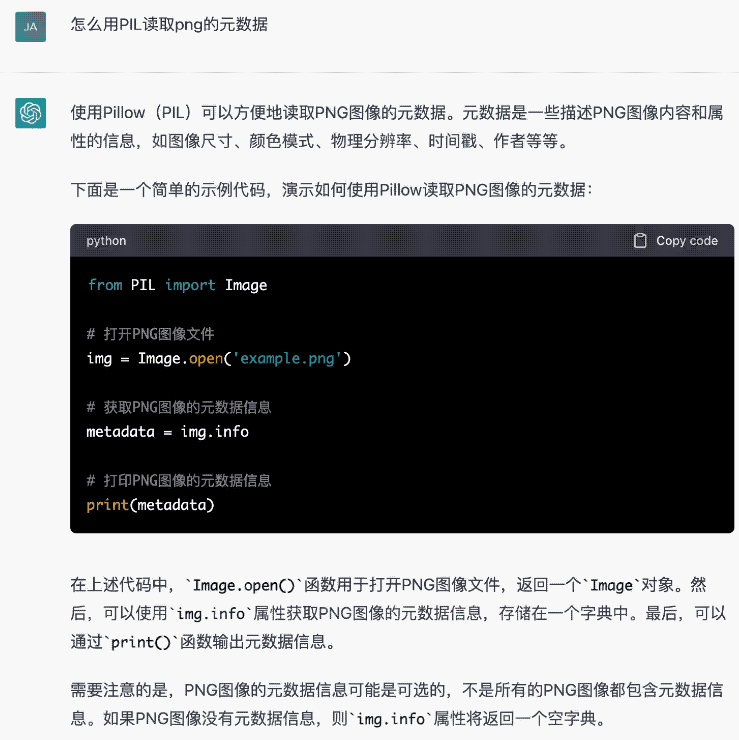
似乎又說PIL就是Pillow,不知道靠不靠譜啊。我們都知道,ChatGPT經常會編造。這也是很多人不信任他的地方。別的領域我們不好說,但是編程領域其實不太有必要不信任他。一個是你看我們可以像這樣去做一個double check。另一個就是我們可以讓他從他講的方案直接生成代碼。如果他的方案不可行,你代碼自然沒法執行。甚至你把代碼提到ide里,它可能都會有語法錯誤,對吧?我們有一套完整的IDE、編譯器和我們的電腦組成的開發環境來驗證它輸出的內容是不是可信的。這也是我為什么這么放心大膽用于編程的原因。
那么既然我們得到了代碼,我就可以開始試驗了,我直接把example.png 改成了test.png,果然打印了出來,這可行!
然后就又問了他怎么修改,怎么append,這里就不展示了,其實如果自己走一遍就會發現,這個里面修改可能是完全覆蓋可能是append,我前面說,我想保留原有信息,所以我需要的是append,這個就不是那么直接可用了,跟它折騰了一會。
所以spike這一步的其中一個意義就在這里:我可以在一個非常單純的環境下隨意地測試方案是否可行,而不用帶上其他復雜的上下文,畢竟我做到這里的時候,程序也挺長的了,輸入的intention.yml也挺復雜的了,每次都從頭測試也很低效。
接著我又讓他給我生成了nodejs怎么調用python,在今天之前,我也從來沒用過這個能力。這個能力spike的很快,spike完我就直接封裝了一個runPythonScript函數出來。
接著到了真正的集成點。我們需要把Python代碼封裝成一個node js函數,然后對我們的程序提供服務。這個時候再給大家演示一下:


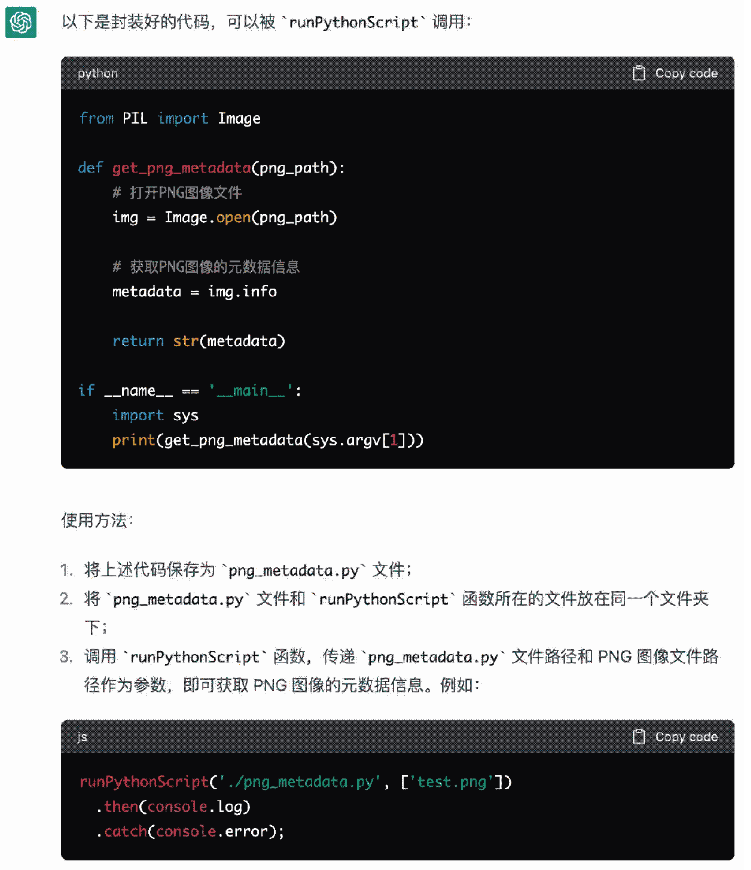
所以可以看到,我們可以直接把代碼給他,不用說太多廢話。他自己能看懂,然后讓他來抹平集成時可能出現的問題。比如傳參問題還有返回值問題。我之前并不知道要怎么傳參和得到返回值,現在我知道了。
所以前面調研環節的另一個價值就體現出來了:你調研得到的代碼可以直接作為prompt使用,并不需要還轉化為什么自然語言,語言就是語言,都能作為prompt的一部分,而且啊,搞不好chatgpt還更喜歡編程語言,畢竟人類的自然語言太不嚴謹了。
感謝各位的閱讀,以上就是“ChatGPT跨越認知邊界實例分析”的內容了,經過本文的學習后,相信大家對ChatGPT跨越認知邊界實例分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





