溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“C++怎么實現數據庫連接池”,內容詳細,步驟清晰,細節處理妥當,希望這篇“C++怎么實現數據庫連接池”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
為了提高Mysql數據庫的訪問瓶頸,常用的方法有如下兩個:
增加連接池,來提高MYsql Server的訪問效率,在高并發的情況下,每一個用戶大量的TCP三次握手。Mysql Server的連接認證,Mysql Server關閉連接回收資源和TCP四次揮手所耗費的性能時間也是明顯的,增加連接池就是為了減少這一部分的性能損耗。
注:常見的MySQL、Oracle、SQLServer等數據庫都是基于C/S架構設計的。
市面上主流的Mysql數據庫連接池,對于短時間內的大量增刪改查操作的性能提升很明顯,但大多數都是Java實現的,該項目的開展就是為了提高Mysql Server的訪問效率,實現基于C++代碼的數據庫連接池模塊。
針對于系統啟動時就創建一定數量的連接,用戶一旦執行CURD操作,直接拿出一條連接即可,不需要TCP的連接過程和資源回收過程,使用完該連接后歸還給連接池的連接隊列,供之后使用。
連接池一般包含了數據庫連接所用的ip地址、port端口號、username用戶名、password密碼以及其他一些性能參數:比如初始連接量、最大連接量、最大空閑時間、連接超時時間等
本項目重點實現上述通用功能:
初始連接量表示連接池事先會和MySQL Server創建的initSize數量的Connection連接。在完成初始連接量之后,當應用發起MySQL訪問時,不用創建新的MySQLServer連接,而是從連接池中直接獲取一個連接,當使用完成后,再把連接歸還到連接池中。
當并發訪問MySQL Server的請求增加,初始連接量不夠用了,此時會增加連接量,但是增加的連接量的上限就是maxSIze。因為每一個連接都會占用一個socket資源,一般連接池和服務器都是部署在一臺主機上,如果連接池的連接數量過多,那么服務器就不能響應太多的客戶端請求了。
當高并發過去,因為高并發而新創建的連接在很長時間(maxIdleTime)內沒有得到使用,那么這些新創建的連接處于空閑,并且占用著一定的資源,這個時候就需要將其釋放掉,最終只用保存iniSize個連接就行。
當MySQL的并發訪問請求量過大,連接池中的連接數量已經達到了maxSize,并且此時連接池中沒有可以使用的連接,那么此時應用阻塞connectionTimeOut的時間,如果此時間內有使用完的連接歸還到連接池,那么他就可以使用,如果超過這個時間還是沒有連接,那么它獲取數據庫連接池失敗,無法訪問數據庫。
連接池只需要一個實例,所以ConnectionPool以單例`模式設計;
從ConnectionPool中可以獲取和Mysql的連接Connection;
空閑連接Connection全部維護在一個線程安全的Connection隊列中,使用線程互斥鎖保證隊列的線程安;
如果Connection隊列為空,還需要再獲取連接,此時需要動態創建連接,上限數量是maxSize;
隊列中空閑連接時間超過maxIdleTime的就會被釋放掉,只保留初始的initSize個連接就可以了,這個功能點肯定要放在獨立的線程中去做;
如果Connection隊列為空,而此時連接的數量已達上限maxSize,那么等待ConnectionTimeout時間還獲取不到空閑的連接,那么獲取連接失敗,此處從Connection隊列獲取空閑連接,可以使用帶超時時間的mutex互斥鎖來實現連接超時時間;
用戶獲取的連接用shared_ptr智能指針來管理,用lambda表達式定制連接釋放的功能(不真正釋放連接,而是把連接歸還到連接池中);
連接的生產和連接的消費采用生產者-消費者線程模型來設計,使用了線程間的同步通信機制條件變量和互斥鎖。
圖示如下:
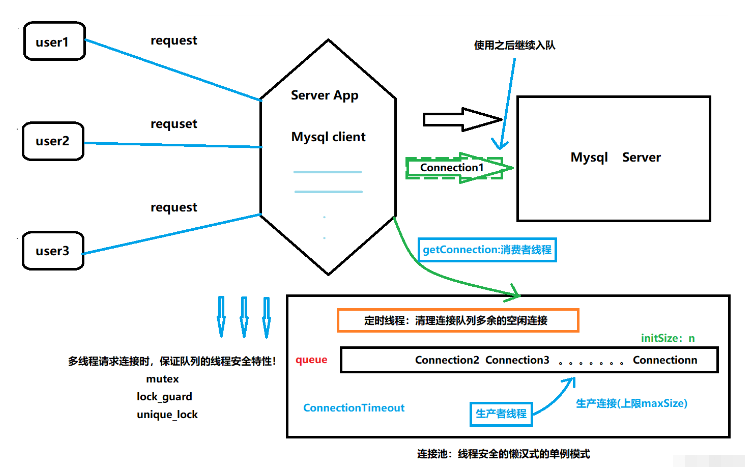
目的:在C++下輸入Sql語句對數據庫進行操作的代碼封裝
說明:這里的MYSQL的數據庫編程直接采用oracle公司提供的C++客戶端開發包 , 讀者可以自己查閱資料或搜索官方文檔自行學習相關API的使用方法。
Connection.h:
class Connection
{
public:
// 初始化數據庫連接
Connection();
// 釋放數據庫連接資源
~Connection();
// 連接數據庫
bool connect(string ip,
unsigned short port,
string user,
string password,
string dbname);
// 更新操作 insert、delete、update
bool update(string sql);
// 查詢操作 select
MYSQL_RES* query(string sql);
// 刷新一下連接的起始的空閑時間點
void refreshAliveTime() { _alivetime = clock(); }
// 返回存活的時間
clock_t getAliveeTime()const { return clock() - _alivetime; }
private:
MYSQL* _conn; // 表示和MySQL Server的一條連接
clock_t _alivetime; // 記錄進入空閑狀態后的起始存活時間
};Connection.cpp:
Connection::Connection()
{
// 初始化數據庫連接
_conn = mysql_init(nullptr);
}
Connection::~Connection()
{
// 釋放數據庫連接資源
if (_conn != nullptr)
mysql_close(_conn);
}
bool Connection::connect(string ip, unsigned short port,
string username, string password, string dbname)
{
// 連接數據庫
MYSQL* p = mysql_real_connect(_conn, ip.c_str(), username.c_str(),
password.c_str(), dbname.c_str(), port, nullptr, 0);
return p != nullptr;
}
bool Connection::update(string sql)
{
// 更新操作 insert、delete、update
if (mysql_query(_conn, sql.c_str()))
{
LOG("更新失敗:" + sql);
return false;
}
return true;
}
MYSQL_RES* Connection::query(string sql)
{
// 查詢操作 select
if (mysql_query(_conn, sql.c_str()))
{
LOG("查詢失敗:" + sql);
return nullptr;
}
return mysql_use_result(_conn);
}這里需要說明的是:在Windows上使用數據庫需要進行相關配置
大致配置內容如下:
右鍵項目- C/C++ - 常規 -附加包含目錄 - 增加mysql.h的頭文件路徑;
右鍵項目 - 鏈接器 - 常規 - 附加庫目錄 - 填寫libmysql.lib的路徑;
右鍵項目 - 鏈接器 - 輸入 - 附加依賴項 - 填寫libmysql.lib的路徑;
把libmysql.dll的動態鏈接庫(Linux下后綴名是.so庫)放在工程目錄下。
連接池僅需要一個實例,同時服務器肯定是多線程的,必須保證線程安全,所以采用懶漢式線程安全的單例:
CommonConnectionPool.h: 部分代碼
class ConnectionPool
{
public:
// 獲取連接池對象實例
static ConnectionPool* getConnectionPool();
// 給外部提供接口,從連接池中獲取一個可用的空閑連接
shared_ptr<Connection> getConnection();
private:
// 單例#1 構造函數私有化
ConnectionPool();
};CommonConnectionPool.cpp: 部分代碼
// 線程安全的懶漢單例函數接口
ConnectionPool* ConnectionPool::getConnectionPool()
{
static ConnectionPool pool; //靜態對象初始化由編譯器自動進行lock和unlock
return &pool;
}連接池的數據結構是queue隊列,最早生成的連接connection放在隊頭,此時記錄一個起始時間,這一點在后面最大空閑時間時會發揮作用:如果隊頭都沒有超過最大空閑時間,那么其他的一定沒有
CommonConnectionPool.cpp 的連接池構造函數:
// 連接池的構造
ConnectionPool::ConnectionPool()
{
// 加載配置項了
if (!loadConfigFile())
{
return;
}
// 創建初始數量的連接
for (int i = 0; i < _initSize; ++i)
{
Connection* p = new Connection();//創建一個新的連接
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAliveTime(); // 刷新一下開始空閑的起始時間
_connectionQue.push(p);
_connectionCnt++;
}
}連接數量沒有到達上限,繼續創建新的連接
if (_connectionCnt < _maxSize)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAliveTime(); // 刷新一下開始空閑的起始時間
_connectionQue.push(p);
_connectionCnt++;
}掃描整個隊列,釋放多余的連接(高并發過后,新建的連接超過最大超時時間時)
unique_lock<mutex> lock(_queueMutex);
while (_connectionCnt > _initSize)
{
Connection* p = _connectionQue.front();
if (p->getAliveTime() >= (_maxIdleTime * 1000))
{
_connectionQue.pop();
_connectionCnt--;
// 調用~Connection()釋放連接
delete p;
}
else
{
// 如果隊頭的連接沒有超過_maxIdleTime,其他連接肯定沒有
break;
}
}為了將多線程編程的相關操作應用到實際,也為了進行壓力測試,用結果證明使用連接池之后對數據庫的訪問效率確實比不使用連接池的時候高很多,使用了多線程來進行數據庫的訪問操作,并且觀察多線程下連接池對于性能的提升。
代碼如下:
int main()
{
thread t1([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
conn.update(sql);
}
});
thread t2([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
conn.update(sql);
}
});
thread t3([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
conn.update(sql);
}
});
thread t4([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "male");
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
conn.update(sql);
}
});
t1.join();
t2.join();
t3.join();
t4.join();
return 0;
}連接池中連接隊列的連接的生產和消費需要保證其線程安全,于是我們需要引入互斥鎖mutex,線程同步通信確保執行順序,以及唯一鎖。
代碼如下:
class ConnectionPool
{
private:
// 設置條件變量,用于連接生產線程和連接消費線程的通信
condition_variable cv;
// 維護連接隊列的線程安全互斥鎖
mutex _queueMutex;
};
for (;;)
{
unique_lock<mutex> lock(_queueMutex);
while (!_connectionQue.empty())
{
// 隊列不為空,此處生產線程進入等待狀態
cv.wait(lock);
}
// 連接數量沒有達到上限,繼續創建新的連接
if (_connectionCnt < _maxSize)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
// 刷新一下開始空閑的起始時間
p->refreshAliveTime();
_connectionQue.push(p);
_connectionCnt++;
}
// 通知消費者線程,可以消費連接了
cv.notify_all();
}// 啟動一個新的線程,作為連接的生產者 linux thread => pthread_create thread produce(std::bind(&ConnectionPool::produceConnectionTask, this)); produce.detach(); // 啟動一個新的定時線程,掃描超過maxIdleTime時間的空閑連接,進行對于的連接回收 thread scanner(std::bind(&ConnectionPool::scannerConnectionTask, this)); scanner.detach();
對于連接池內的連接數量,生產者和消費者線程都會去改變其值,那么這個變量的修改就必須保證其原子性,于是使用C++11中提供的原子類:atomic_int
atomic_int _connectionCnt; // 記錄連接所創建的connection連接的總數量 // 生產新連接時: _connectionCnt++; // 當新連接超過最大超時時間后被銷毀時 _connectionCnt--;
對于使用完成的連接,不能直接銷毀該連接,而是需要將該連接歸還給連接池的隊列,供之后的其他消費者使用,于是我們使用智能指針,自定義其析構函數,完成放回的操作:
shared_ptr<Connection> sp(_connectionQue.front(),
[&](Connection* pcon) {
// 這里是在服務器應用線程中調用的,所以一定要考慮隊列的線程安全操作
unique_lock<mutex> lock(_queueMutex);
pcon->refreshAliveTime();
_connectionQue.push(pcon);
});測試添加連接池后效率是否提升:
未使用連接池
單線程
int main()
{
clock_t begin = clock();
for (int i = 0; i < 1000; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
clock_t end = clock();
cout << (end - begin) << "ms" << endl;
return 0;
}運行時間如下:

多線程
int main()
{
Connection conn;
conn.connect("127.0.0.1", 3306, "root", "991205", "chat");
clock_t begin = clock();
thread t1([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
});
thread t2([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
});
thread t3([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
});
thread t4([]() {
for (int i = 0; i < 250; ++i)
{
Connection conn;
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
conn.connect("127.0.0.1", 3306, "root", "123456", "chat");
conn.update(sql);
}
});
t1.join();
t2.join();
t3.join();
t4.join();
clock_t end = clock();
cout << (end - begin) << "ms" << endl;
return 0;
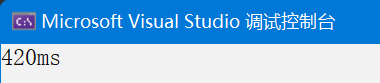
}運行時間如下:
使用連接池
單線程
int main()
{
clock_t begin = clock();
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 1000; ++i)
{
shared_ptr<Connection> sp = cp->getConnection();
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
sp->update(sql);
}
clock_t end = clock();
cout << (end - begin) << "ms" << endl;
return 0;
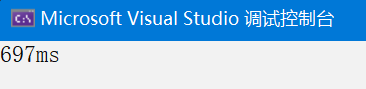
}運行時間如下
多線程
int main()
{
clock_t begin = clock();
thread t1([]() {
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 250; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
}
});
thread t2([]() {
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 250; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
}
});
thread t3([]() {
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 250; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
}
});
thread t4([]() {
ConnectionPool* cp = ConnectionPool::getConnectionPool();
for (int i = 0; i < 250; ++i)
{
char sql[1024] = { 0 };
sprintf(sql, "insert into user(name,age,sex) values('%s',%d,'%s')",
"zhang san", 20, "M");
shared_ptr<Connection> sp = cp->getConnection();
sp->update(sql);
}
});
t1.join();
t2.join();
t3.join();
t4.join();
clock_t end = clock();
cout << (end - begin) << "ms" << endl;
return 0;
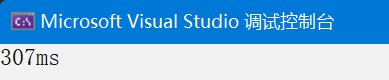
}
比較
在使用了連接池之后,性能確實提升了不少
數據量1000,單線程從1417ms變成697ms
數據量1000,多線程從420ms變成了307ms
讀到這里,這篇“C++怎么實現數據庫連接池”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





