溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了基于idea如何操作hbase數據庫并映射到hive表的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇基于idea如何操作hbase數據庫并映射到hive表文章都會有所收獲,下面我們一起來看看吧。
依賴條件:需要有Hadoop,hive,zookeeper,hbase環境
映射:每一個在 Hive 表中的域都存在于 HBase 中,而在 Hive 表中不需要包含所有HBase 中的列。HBase 中的 RowKey 對應到 Hive 中為選擇一個域使用 :key 來對應,列族(cf:)映射到 Hive 中的其它所有域,列為(cf:cq)
配置映射環境
[root@siwen ~]# stop-hbase.sh -----關閉hbase
[root@siwen ~]# zkServer.sh stop -----關閉zookeeper
[root@siwen ~]# stop-alll.sh -----關閉hadoop
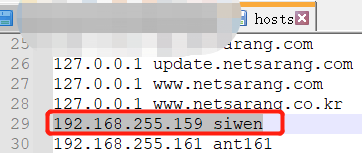
1,修改host文件:
C:\Windows\System32\drivers\etc在此目錄下的hosts文件把此機器的ip和hostname加入進去
2,修改hive-site.xml
[root@siwen ~]# cd /opt/soft/hive312/conf/
[root@siwen conf]# vim ./hive-site.xml
加入下面幾行
<property> <name>hive.zookeeper.quorum</name> <value>192.168.255.159</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>192.168.255.159</value> </property> <property> <name>hive.aux.jars.path</name> <value>file:///opt/soft/hive312/lib/hive-hbase-handler-3.1.2.jar,file:///opt/soft/hive312/lib/zookeeper-3.4.6.jar,file:///opt/soft/hive312/lib/hbase-client-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-common-2.3.5-tests.jar,file:///opt/soft/hive312/lib/hbase-server-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-common-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-protocol-2.3.5.jar,file:///opt/soft/hive312/lib/htrace-core-3.2.0-incubating.jar</value> </property>
3,拷貝jar包
①將hbase235/lib目錄下所有的jar包都拷貝到hive下面
[root@siwen conf]# cp /opt/soft/hbase235/lib/* /opt/soft/hive312/lib/
是否覆蓋內容的時候,可以輸入n,不覆蓋;或者覆蓋了也沒問題
②統一guava文件
[root@siwen lib]# find ../lib/guava* -------查看所有的guava文件
[root@siwen lib]# rm -rf ../lib/guava-11.0.2.jar -------刪除11版本的
[root@siwen conf]# cd /opt/soft/hbase235/lib/
[root@siwen lib]# pwd
/opt/soft/hbase235/lib
[root@siwen lib]# cp /opt/soft/hive312/lib/guava-27.0-jre.jar ./ -----把hive的guava文件拷貝給hbase
#啟動hadoop [root@siwen lib]# start-all.sh #啟動zookeeper [root@siwen lib]# zkServer.sh start #啟動hbase [root@siwen lib]# start-hbase.sh #啟動hive [root@siwen lib]# nohup hive --service metastore & [root@siwen lib]# nohup hive --service hiveserver2 &
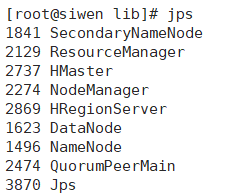
開始使用idea創建maven工程
在pom.xml 里面添加依賴
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>2.3.5</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>2.3.5</version> </dependency>
1,編寫初始化方法:配置hbase信息,連接數據庫
//定義一個config,用于獲取配置對象
static Configuration config = null;
//獲取連接
private Connection conn = null;
Admin admin = null;
@Before
public void init() throws IOException {
//配置hbase信息,連接hbase數據庫
config = HBaseConfiguration.create();
config.set(HConstants.HBASE_DIR, "hdfs://192.168.255.159:9000/hbase");
config.set(HConstants.ZOOKEEPER_QUORUM, "192.168.255.159");
config.set(HConstants.CLIENT_PORT_STR, "2181");
//hbase連接工廠
conn = ConnectionFactory.createConnection(config);
//拿到admin
admin = conn.getAdmin();
}2,編寫關閉方法
@After
public void close() throws IOException {
System.out.println("執行close()方法");
if (admin!=null)
admin.close();
if (conn!=null)
conn.close();
}3,編寫創建命名空間方法
@Test
public void createNameSpace() throws IOException {
NamespaceDescriptor bigdata = NamespaceDescriptor.create("bigdata").build();
#執行創建對象
admin.createNamespace(bigdata);
}4,編寫創建表的方法
@Test
public void createTable() throws IOException {
//創建表的描述類
TableName tableName = TableName.valueOf("bigdata:student");
//獲取表格描述器
HTableDescriptor desc = new HTableDescriptor(tableName);
//創建列族的描述,添加列族
HColumnDescriptor family1 = new HColumnDescriptor("info1");
HColumnDescriptor family2 = new HColumnDescriptor("info2");
desc.addFamily(family1);
desc.addFamily(family2);
admin.createTable(desc);*/5,編寫查看表結構的方法
@Test
public void getAllNamespace() throws IOException {
List<TableDescriptor> tableDesc = admin.listTableDescriptorsByNamespace("bigdata".getBytes());
System.out.println(tableDesc.toString());
}6,編寫插入數據方法
@Test
public void insertData() throws IOException {
//獲取表的信息
Table table = conn.getTable(TableName.valueOf("bigdata:student"));
//設置行鍵
Put put = new Put(Bytes.toBytes("student1"));
//設置列的標識以及列值
put.addColumn("info1".getBytes(), "name".getBytes(), "zs".getBytes());
put.addColumn("info2".getBytes(), "school".getBytes(), "xwxx".getBytes());
//執行添加
table.put(put);
//使用集合添加數據
Put put2 = new Put(Bytes.toBytes("student2"));
put2.addColumn("info1".getBytes(), "name".getBytes(), "zss".getBytes());
put2.addColumn("info2".getBytes(), "school".getBytes(), "xwxx".getBytes());
Put put3 = new Put(Bytes.toBytes("student3"));
put3.addColumn("info1".getBytes(), "name".getBytes(), "zsr".getBytes());
put3.addColumn("info2".getBytes(), "school".getBytes(), "xwxx".getBytes());
List<Put> list = new ArrayList<>();
list.add(put2);
list.add(put3);
table.put(list);
}7,編寫查詢指定數據的方法
#查詢student1的信息
@Test
public void queryData() throws IOException {
Table table = conn.getTable(TableName.valueOf("bigdata:student"));
Get get = new Get(Bytes.toBytes("student1"));
Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
System.out.println("姓名:"+Bytes.toString(value));
value = result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("school"));
System.out.println("學校:"+Bytes.toString(value));
}
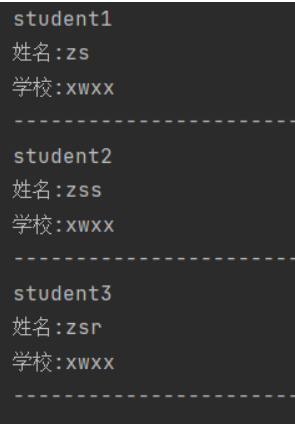
8,編寫掃描數據的方法(所有數據)
@Test
public void scanData() throws IOException {
Table table = conn.getTable(TableName.valueOf("kb21:student"));
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] value = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
System.out.println("姓名:"+Bytes.toString(value));
value = result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("school"));
System.out.println("學校:"+Bytes.toString(value));
System.out.println(Bytes.toString(result.getRow()));
}
}
9,編寫刪除表的方法
@Test
public void deleteTable() throws IOException {
//先禁用
admin.disableTable(TableName.valueOf("bigdata:student"));
//再刪除
admin.deleteTable(TableName.valueOf("bigdata:student"));
}創建外部表
---------主要外部表的字段需要和Hbase中的列形成映射
create external table student(
id string,
name string,
school string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties ("hbase.columns.mapping"=":key,info1:name,info2:school")
tblproperties ("hbase.table.name"="bigdata:student");select * from student
關于“基于idea如何操作hbase數據庫并映射到hive表”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“基于idea如何操作hbase數據庫并映射到hive表”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





