溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“go time.After性能怎么優化”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“go time.After性能怎么優化”文章能幫助大家解決問題。
在項目中,基本都離不開需要休眠等待一定時間后再執行下一步邏輯的操作,再搭配select,用起來是真的舒服。
func waitWorking() {
select {
case <-time.After(5 * time.Second): // 每隔5秒,主動向客戶端詢問任務狀態
_ = receiver.CheckWorkingEventBus.Publish(receiver)
case <-receiver.updated:
}
}在這個示例中,5秒后會執行Publish函數,或者<-receiver.updated有數據時退出,這是我們比較常用的方式。
但有一點要注意的是:time.After如果沒有被執行到,會導致無法第一時間GC回收內存。
從內存分析中,會看到內存在持續增長,到了一定時間后,才會下降。這個增長幅度隨著你的項目請求量而決定。
這是因為當<-receiver.updated被觸發執行時,導致time.After(5 * time.Second)在5秒后才會有數據進來,在這5秒內,time.After創建的NewTimer(d)是無法回收的。
func After(d Duration) <-chan Time {
return NewTimer(d).C
}明白了這一點之后,我們可以簡單的做一個改進
func waitWorking() {
timer := time.NewTimer(5 * time.Second)
select {
case <-timer.C: // 每隔5秒,主動向客戶端詢問任務狀態
_ = receiver.CheckWorkingEventBus.Publish(receiver)
case <-receiver.updated:
timer.Stop()
}
}當<-receiver.updated被觸發執行時,我們主動調用Stop方法,來告知GC,此timer對象不再使用。
這樣就不至于等到5秒后,GC才知道這個對象不再使用。
這就完了嗎?顯示沒有,如果waitWorking函數會在并發中被調用:
type TaskGroupMonitor struct {
updated chan struct{} // 數據有更新,讓流程重置
name string // 任務名稱
}
func (receiver *TaskGroupMonitor) waitWorking() {
timer := time.NewTimer(5 * time.Second)
select {
case <-timer.C: // 每隔5秒,主動向客戶端詢問任務狀態
_ = receiver.CheckWorkingEventBus.Publish(receiver)
case <-receiver.updated:
timer.Stop()
}
}
func init() {
// 模擬數據庫讀到了100條任務
for i := 0; i < 100; i++ {
taskGroup:= TaskGroupMonitor{}
go taskGroup.waitWorking()
}
}這里假如從數據庫中讀到了100條任務數據,每條數據都在獨立的協程中運行。
這就會導致在這100條任務在運行的過程中,創建了100個time.Timer對象,事實上除了waitWorking,還會有waitStart,waitScheduler,taskFinish等函數也使用了time.Timer對象。
可以想到,項目在運行過程中time.Timer在不停的創建,直到GC后才被回收。這將導致我們的內存一直占用著。
并且time.After或time.NewTicker并不是高精度的時間控制。有時候會慢那么0-3ms,協程數量越多越繁忙,則越不精準。
這對于調度中心而言是無法接收的,我的目標是支持幾千個任務同時監控調度。意味著協程數量會非常高。
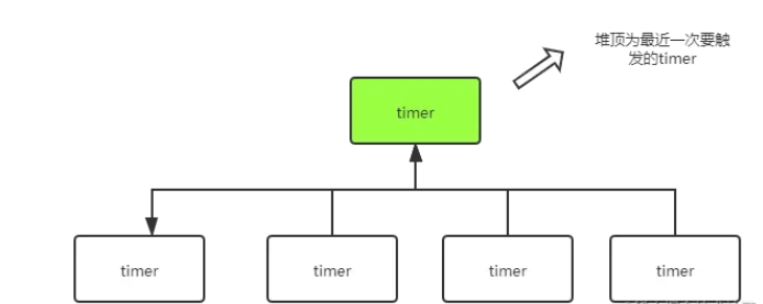
而在GO的time.Timer中是使用64個timersBucket,并使用四叉堆來管理各個timer,雖然在1.17版本有所改進。
但時間上仍然沒有那么準確,對于調度這種場景來說,對ms級別的延遲也是沒辦法接受的。
time.Timer原理不在本篇的范圍內,現在有很多大神有這方面的剖析,感興趣可以去搜搜。
通過簡單的分析,我們已經知道使用time.Timer會有如下缺點:
每個協程需要創建time.Timer(導致內存占用上升)
time.Timer會有延遲(對于ms敏感的場景不適用)
即如此,我們是否可以通過統一的時間管理器來管理所有的時間觸發器呢?
答案是顯而易見的,那就是時間輪。
時間輪是一種實現延遲功能的算法, 它在Linux內核中使用廣泛, 是Linux內核定時器的實現方法和基礎之一. 時間輪是一種高效來利用線程資源來進行批量化調度的一種調度模型, 把大量的調度任務全部綁定到同一個調度器上, 利用這個調度器來進行所有任務的管理, 觸發以及運行.
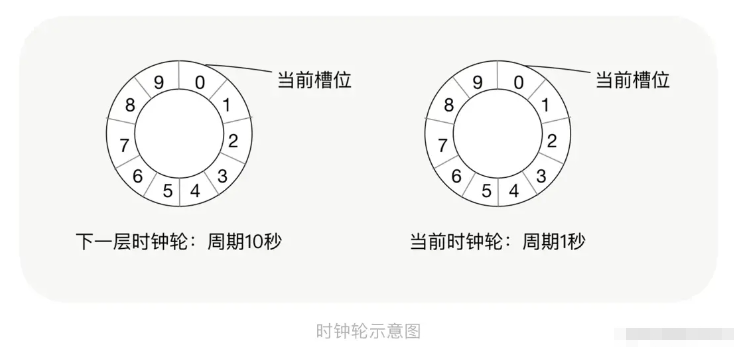
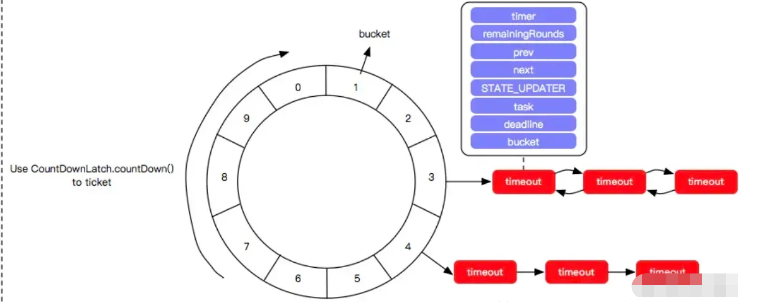
簡單來說,時間輪就是一個模擬時鐘的原理。 實現方式有:單層、雙層、多層三種方式。
而在雙層、多層時間輪中,又有兩種算法:一種是不管幾層,時間周期是一樣的。另一種是低層一圈 = 上層一格(像秒針、分針一樣)
在時鐘里,秒針走完一圈,分針走一格。分針走完一圈,時針走一格。以此類推。
當秒針走到第X格,會到第X格的隊列中找到是否有待執行任務列表,如果有則取出并通知到C變量。
而我在實現這個時間輪就是完全模擬時鐘的這種算法來實現的。我與其它開源的時間輪不一樣的地方是,我是高精度算法的。
時間輪的原理大概就講這么多,畢竟不是一個什么新鮮的算法,網上有很多講的比我更透徹的大神,在這里我主要講使用時間輪的前后對比。
我們來看看如何使用:
// 在項目中,定義一個全局變量tw,并規定第0層,走一格=100ms,一圈有120格 import "github.com/farseer-go/fs/timingWheel" var tw = timingWheel.New(100*time.Millisecond, 120) tw.Start()
接著在項目中我們改成時間輪來控制時間:
func (receiver *TaskGroupMonitor) waitWorking() {
select {
case <-tw.AddPrecision(60 * time.Second).C:
_ = receiver.CheckWorkingEventBus.Publish(receiver)
case <-receiver.updated:
}
}至此,我們使用了全局tw變量來控制時間的延遲管理。
我們來看下,優化前的情況:

100個并發下調度:平均延遲:10ms、CPU:31.4%、內存:115m
優化后:

100個并發下調度:平均延遲:1ms、CPU:21.7%、內存:34.5m
為此,整體性能提升:34%,內存減少:67%
關于“go time.After性能怎么優化”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





