溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Python常見類型轉換有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Python常見類型轉換有哪些”吧!
| 類型 | 舉例 | 說明 |
| 二進制 | a = 0b1010 | 二進制以0b打頭 |
| 八進制 | b = 0o2345 | 八進制以0o打頭(注意是字母的o) |
| 十進制 | c = 500 | 十進制沒有前綴 |
| 十六進制 | d = 0x12ff | 十六進制以0x打頭 |
| 字符串 | e = "ftz" | 字符串的內容用引號或雙引號括住 |
| 字節 | f = b'f12345' | 字節以b修飾,內容用引號或雙引號括住 |
| bin十六進制 | g = b'\x18\x17\x25' | 報文中的碼流存在形式 |
>>> var = 100 >>> bin(var) #其他進制轉二進制 '0b1100100' >>> oct(var) #其他進制轉八進制 '0o144' >>> int(var) #其他進制轉十進制 100 >>> hex(var) #其他進制轉十六進制 '0x64' >>>
>>> var = 100 >>> >>> strNum = str(var) #數值轉字符串 >>> strNum '100' >>> >>> intNum = int(strNum) #字符串轉數值 >>> intNum 100 >>>
注意:字符串轉數值常見,轉換成功的前提是被轉換的對象只有全是數字字符才可以,不然會報錯如下所示,此場景的轉換一般在轉換前要對對象進行判斷用字符串的方法isdigit()
>>> int('abc')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'abc'
>>> 'abc'.isdigit()
False
>>> '124'.isdigit()
True
>>>解碼的本質是選擇二進制對應的圖形,編碼的本質是把字符圖形轉成相應編碼的二進制。這只是一種顯示的變化,在內存上并不一定有變化
>>> byteMyName = b'ftz' >>> strMyName = 'ftz' >>> >>> strMyName.encode() #字符串轉byte b'ftz' >>> byteMyName.decode() #byte轉字符串 'ftz'
下面具體看下兩個轉換方法
decode方法有兩個參數,encoding默認是用'utf-8'進行解碼,errors默認用'strict'模式,如果需要一定的容錯,則用'ignore'
| decode(self, /, encoding='utf-8', errors='strict') | Decode the bytes using the codec registered for encoding. | | encoding | The encoding with which to decode the bytes. | errors | The error handling scheme to use for the handling of decoding errors. | The default is 'strict' meaning that decoding errors raise a | UnicodeDecodeError. Other possible values are 'ignore' and 'replace' | as well as any other name registered with codecs.register_error that | can handle UnicodeDecodeErrors.
decode() 方法的語法格式如下:
bytes.decode([encoding="utf-8"][,errors="strict"])
decode() 方法用于將 bytes 類型的二進制數據轉換為 str 類型,這個過程也稱為“解碼”
decode()參數及含義
| 參數 | 含義 |
|---|---|
| bytes | 表示要進行轉換的二進制數據。 |
| encoding="utf-8" | 指定解碼時采用的字符編碼,默認采用 utf-8 格式。當方法中只使用這一個參數時,可以省略“encoding=”,直接寫編碼方式即可。 注意,對 bytes 類型數據解碼,要選擇和當初編碼時一樣的格式。 |
| errors = "strict" | 指定錯誤處理方式,其可選擇值可以是:
|
encode方法同樣有兩個參數,encoding默認是用'utf-8'編碼進行轉換
| encode(...) | S.encode(encoding='utf-8', errors='strict') -> bytes | | Encode S using the codec registered for encoding. Default encoding | is 'utf-8'. errors may be given to set a different error | handling scheme. Default is 'strict' meaning that encoding errors raise | a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and | 'xmlcharrefreplace' as well as any other name registered with | codecs.register_error that can handle UnicodeEncodeErrors.
encode() 方法的語法格式如下:
str.encode([encoding="utf-8"][,errors="strict"])
注意,格式中用 [] 括起來的參數為可選參數,也就是說,在使用此方法時,可以使用 [] 中的參數,也可以不使用。
encode()參數及含義
| 參數 | 含義 |
|---|---|
| str | 表示要進行轉換的字符串。 |
| encoding = "utf-8" | 指定進行編碼時采用的字符編碼,該選項默認采用 utf-8 編碼。例如,如果想使用簡體中文,可以設置 gb2312。 當方法中只使用這一個參數時,可以省略前邊的“encoding=”,直接寫編碼格式,例如 str.encode("UTF-8")。 |
| errors = "strict" | 指定錯誤處理方式,其可選擇值可以是:
|
上面的都是鋪墊,本節將是要重點介紹的內容。在用scapy構造報文或者編輯報文的過程中,常常需要從報文中提取我們感興趣的內容或者將我們改造的數據插入到報文中。這里面就需要用到各種轉換。最基本的操作就是將bin十六進制(報文中的數據,也稱為碼流)轉int、轉byte、轉str。相反插入一段數據或者構造的數據到報文中,則是將int、byte、str類型轉成bin十六進制。

下面將對十六進制碼流和int、byte、str互轉進行定義
| bin十六進制轉int | 將二進制文件中的b“\x01\x79”轉為“377”的過程。本質上講,就是把一個byte型十六進制數,轉成十進制數的過程。(注意區別:int(0x178)時參數0x179是16進制整型而b’\x01\x79’是byte數組) |
| int轉bin十六進制 | 將“377”轉為二進制文件中的b“\x01\x79”的過程。本質上講,就是把一個十進制數,轉成byte型十六進制數的過程。(注意區別:hex(377)得到的0x179是16進制整型而b’\x01\x79’是byte數組) |
| bin十六進制轉byte | 將二進制文件中的b“\x04\xf9\x38\xad\x13\x26”取為b‘04f9381326’的過程。本質上講,就是將每個十六進制數(4bit),轉成一個采用ascii編碼的byte(8bit)的過程 |
| byte轉bin十六進制 | 將b‘04f9381326’取為二進制文件中的b“\x04\xf9\x38\xad\x13\x26”的過程。本質上講,就是將每個采用ascii編碼的byte(8bit),轉成一個十六進制數(4bit)的過程 |
| bin十六進制轉str | 將二進制文件中b’\x48\x54\x54\x50’取為字符串‘HTTP’的過程。本質上講,就是將ascii編碼轉成對應字符的過程。 |
| str轉bin十六進制 | 將字符串‘HTTP’取為二進制文件中b’\x48\x54\x54\x50’的過程。本質上講,字符轉成就是對應的ascii編碼的過程 |
bin十六進制轉int主要在分析二進制文件、數據包頭時獲取長度等值時使用;相反,int轉bin十六進制就是在構造二進制文件、數據包頭時寫入長度等值時使用。
另外注意把bin十六進制當數值時有大端和小端兩種模式,大端意思是開頭(低地址)權重大,小端為開頭(低地址)權重小。文件系統一般用小端模式,網絡傳輸一般用大端模式。
| 轉換 | 方法 | 說明 |
| int轉bin十六進制 | to_bytes(lenght,byteorder) | lenght表示轉成的多少個字節;byteorder可為big或little分別表示轉bin十六進制時使用大端模式還是小端模式 |
| bin十六進制轉int | int.from_bytes(byte_var,byteorder) | byte_var是要轉成數值的變bin十六進制變量,byteorder還是一樣可為big或little,分別表示從bin十六進制轉為數值時把bin十六進制當大端模式還是小端模式處理 |
舉例:

將端口的對應的碼流\xdc\x39轉成56377
>>> int.from_bytes(b'\xdc\x39','big') 56377 >>>
將56377轉成碼流\xdc\x39
>>> port = 56377 >>> byteFromInt = port.to_bytes(2,'big') >>> byteFromInt b'\xdc9' >>> byteFromInt == b'\xdc\x39' True
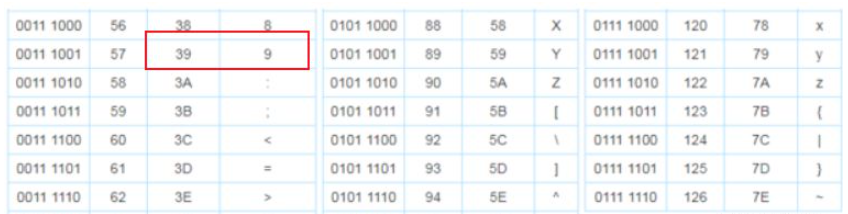
轉出來為什么是\xdc9,我們查一下ascii碼表,9對應的十六進制就是\x39
bin十六進制轉byte主要在分析二進制文件、數據包頭時獲取mac地址、密鑰等平時就以十六進制表示的值時使用;相反,byte轉bin十六進制就是在構造二進制文件、數據包頭時寫入mac地址、密鑰等平時就以十六進制表示的值時使用。這在用scapy構造數據包或者轉換數據包時會經常用到,這里要用到第三方庫binascii,使用時需要先導入
| 轉換 | 方法 | 說明 |
| bin十六進制轉byte | binascii.b2a_hex(bin_var) | bin_var為byte變量常從二進制文件中讀出; 如binascii.b2a_hex(b’\x04\xf9\x38\xad\x13\x26’)結果為b’04f9381326‘ |
| byte轉bin十六進制 | binascii.a2b_hex(hex_byte_var) | hex_byte_var為十六進制字節串; 如binascii.a2b_hex(b’04f9381326’)結果為b’\x04\xf98\x13&’(8對應的ascii編碼是38,&對應的ascii編碼是26) |
舉例:
>>> import binascii >>> binascii.b2a_hex(b'\x48\x6f\x73\x74\x3a\x20\x63') #bin十六進制轉byte b'486f73743a2063' >>> >>> binascii.a2b_hex(b'486f73743a2063') #byte轉bin十六進制 b'Host: c' >>>
實際使用中我們經常會構造十六進制碼流,然后將碼流格式化成byte型,最后將byte轉成bin十六進制
bin十六進制轉主要在分析二進制文件、數據包頭時獲取其量的字符串時使用;相反,byte轉bin十六進制就是在構造二進制文件、數據包頭時寫入字符串時使用。
bin十六進制與str互轉其實就是字符串和byte互轉;此處的bin十六進制就是byte的本質。(b’\x48\x54\x54\x50’和b’HTTP’在內存中是一模一樣的)
| 轉換 | 方法 | 說明 |
| bin十六進制轉str | decode | 在第3節中有詳細介紹 |
| str轉bin十六進制 | encode | 在第3節中有詳細介紹 |
舉例:

>>> byteHost = b'\x48\x6f\x73\x74' >>> >>> byteHost.decode() 'Host' >>> >>> str = 'Host' >>> str.encode() b'Host' >>>
感謝各位的閱讀,以上就是“Python常見類型轉換有哪些”的內容了,經過本文的學習后,相信大家對Python常見類型轉換有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





