溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下spark編程python代碼分析的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[])
1.1.啟動
IPYTHON_OPTS="notebook" /opt/spark/bin/pyspark

下載應用,將應用下載為.py文件(默認notebook后綴是.ipynb)
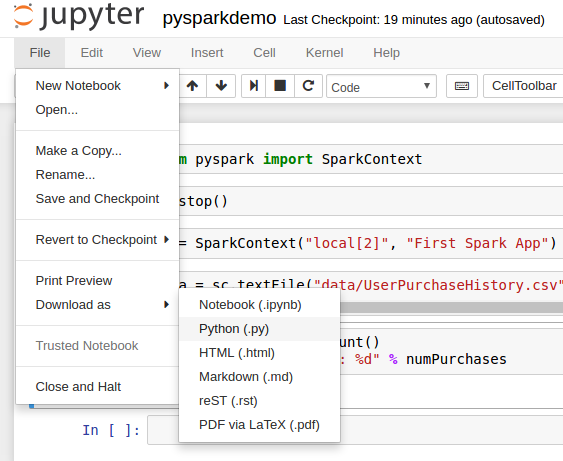
wxl@wxl-pc:/opt/spark/bin$ spark-submit /bin/spark-submit /home/wxl/Downloads/pysparkdemo.py

ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*])
d*
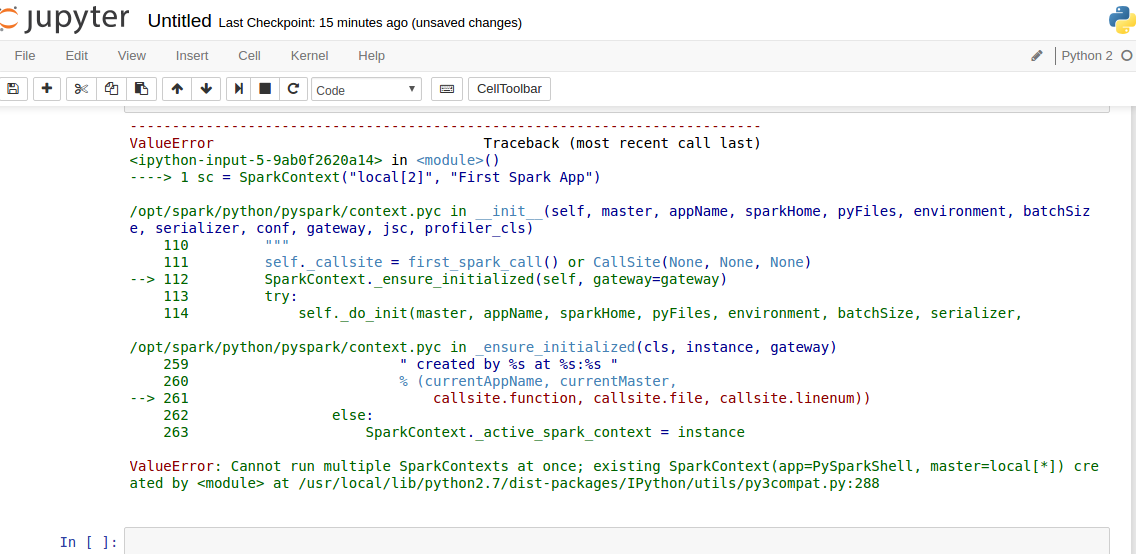
3.1.錯誤
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*])
d*
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*]) created by <module> at /usr/local/lib/python2.7/dist-packages/IPython/utils/py3compat.py:288
3.2.解決,成功運行
在from之后添加
try:
sc.stop()
except:
pass
sc=SparkContext('local[2]','First Spark App')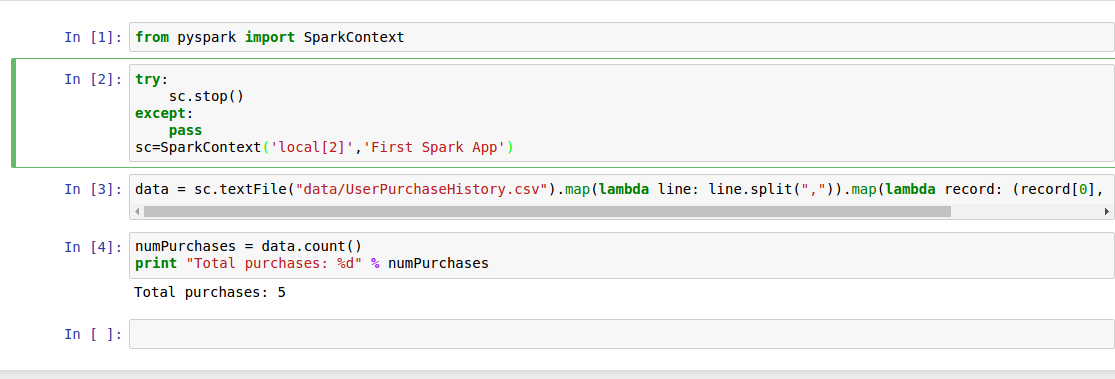
貼上錯誤解決方法來源StackOverFlow
pysparkdemo.ipynb
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"from pyspark import SparkContext"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"try:\n",
" sc.stop()\n",
"except:\n",
" pass\n",
"sc=SparkContext('local[2]','First Spark App')"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"data = sc.textFile(\"data/UserPurchaseHistory.csv\").map(lambda line: line.split(\",\")).map(lambda record: (record[0], record[1], record[2]))"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false,
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Total purchases: 5\n"
]
}
],
"source": [
"numPurchases = data.count()\n",
"print \"Total purchases: %d\" % numPurchases"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.12"
}
},
"nbformat": 4,
"nbformat_minor": 0
}pysparkdemo.py
# coding: utf-8
# In[1]:
from pyspark import SparkContext
# In[2]:
try:
sc.stop()
except:
pass
sc=SparkContext('local[2]','First Spark App')
# In[3]:
data = sc.textFile("data/UserPurchaseHistory.csv").map(lambda line: line.split(",")).map(lambda record: (record[0], record[1], record[2]))
# In[4]:
numPurchases = data.count()
print "Total purchases: %d" % numPurchases
# In[ ]:以上就是“spark編程python代碼分析”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





