溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下MySQL中如何進行大文本存儲壓縮的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
select
table_name as '表名',
table_rows as '記錄數',
truncate(data_length/1024/1024, 2) as '數據容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)',
truncate(DATA_FREE/1024/1024, 2) as '碎片占用(MB)'
from
information_schema.tables
where
table_schema=${數據庫名}
order by
data_length desc, index_length desc;
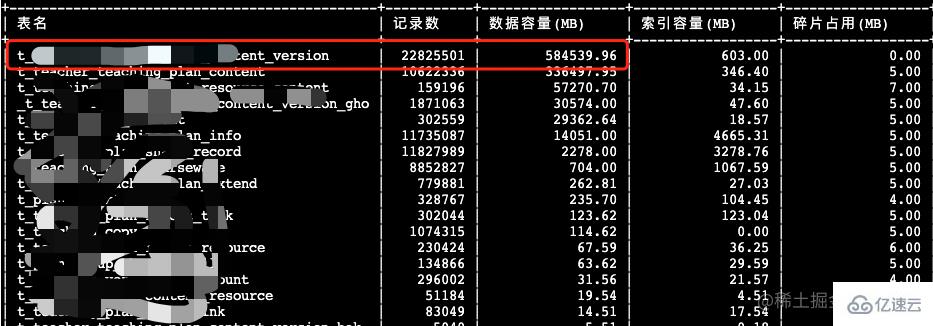

我們都知道innodb的頁塊默認大小為16k,如果表中一行數據長度超出了16k,就會出現行溢出,溢出的行是存放在另外的地方(uncompress blob page)。由于innodb采用聚簇索引把數據進行存放起來,即B+Tree結構,因此每個頁塊中至少有兩行數據,否則就失去了B+Tree的意義,這樣就得出一行數據最大的長度限制為8k(大字段在數據頁會存儲768個字節數據,剩余的數據溢出到另外的頁中,數據頁還有20個字節記錄溢出頁的地址)
對 dynamic 格式來說,如果大對象字段(text/blob)存儲數據大小小于 40 字節,那全部放在數據頁,剩余的場景,數據頁只保留一個 20 字節的指針指向溢出頁。 這種場景下,如果每個大對象字段保存的數據小于 40 個字節,也就和 varchar(40),效果一樣。
innodb-row-format-dynamic:dev.mysql.com/doc/refman/…
稀疏文件(Sparse File):稀疏文件與其他普通文件基本相同,區別在于文件中的部分數據全為0,且這部分數據不占用磁盤空間
文件空洞:文件位移量可以大于文件的實際長度(位于文件中但未被寫過的字節被設為0),空洞是否占用磁盤空間由操作系統決定
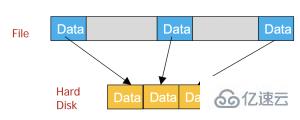
文件空洞部分不占用磁盤空間、文件所占用的磁盤空間仍然是連續的
適用場景:由于數據量太大,磁盤空間不足,負載主要體現在IO上,而服務器的CPU又有比較多的余量的場景。
相關文檔:dev.mysql.com/doc/refman/…
在MySQL5.7版本之前就提供的頁壓縮功能,在創建表時指定 ROW_FORMAT = COMPRESS,并通過 KEY_BLOCK_SIZE 設置壓縮頁的大小
存在設計上的缺陷,有可能會導致性能下降明顯,然后其設計初衷是為了提升性能,引入了“日志即數據”的理念
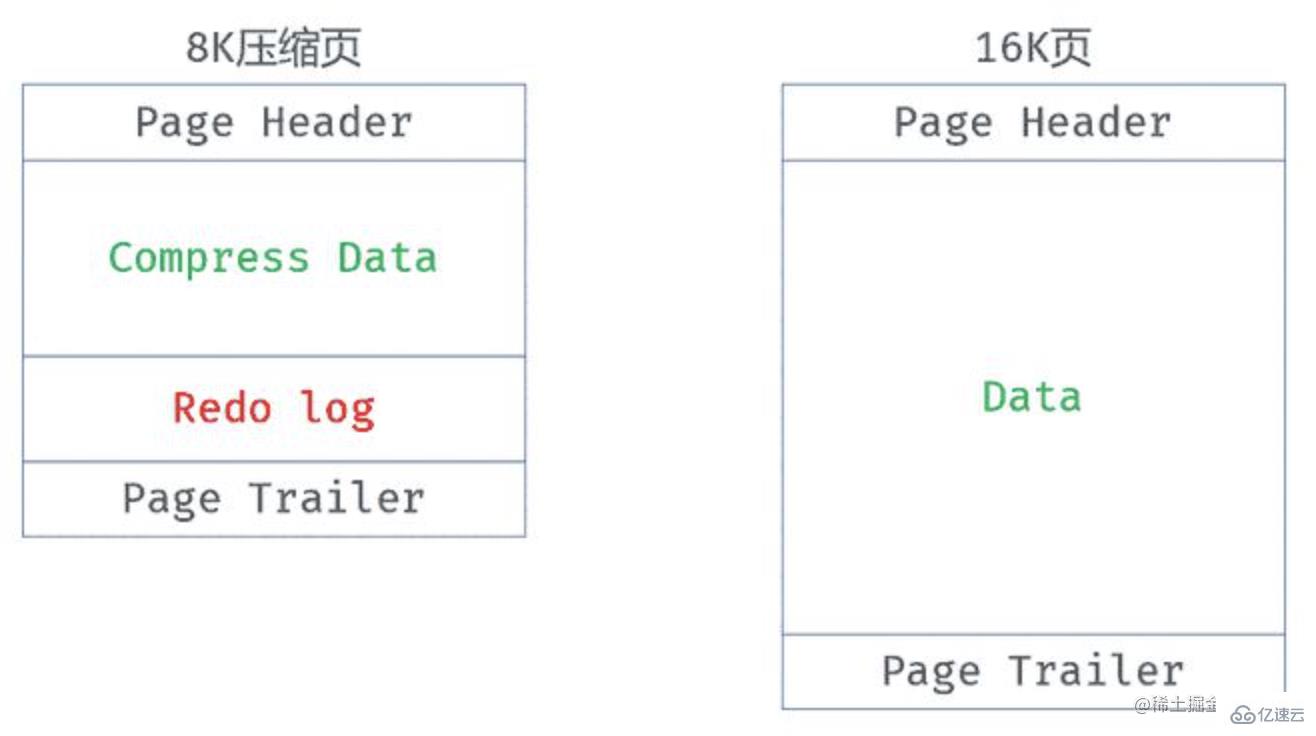

對于壓縮頁的數據修改,并不會直接修改頁本身,而是將修改日志存儲在這個頁中,這確實對數據的變更比較友好,不用每次修改都進行壓縮/解壓
對于數據的讀取,壓縮的數據是無法直接讀取的,所以這種算法會在內存中保留一個解壓后的16K的頁,以供數據的讀取
這就導致了一個頁在緩沖池中可能會有兩個版本(壓縮版和非壓縮版),引發一個非常嚴重的問題,即緩沖池中能緩存的頁的數量大大的減少了,從而可能會導致數據庫的性能極大的下降
工作原理:寫入頁面時,使用指定的壓縮算法對頁面進行壓縮,壓縮后寫入磁盤,其中通過打孔機制從頁面末尾釋放空(需要操作系統支持空洞特性)
ALTER TABLE xxx COMPRESSION = ZLIB 可以啟用TPC頁壓縮功能,但這只是對后續增量數據進行壓縮,如果期望對整個表進行壓縮,則需要執行 OPTIMIZE TABLE xxx
實現過程:一個壓縮頁在緩沖池中都是一個16K的非壓縮頁,只有在數據刷盤的時候,會進行一次壓縮,壓縮后剩余的空間會用 0x00 填滿,利用文件系統的空洞特性(hole punch)對文件進行裁剪,釋放 0x00 占用的稀疏空間
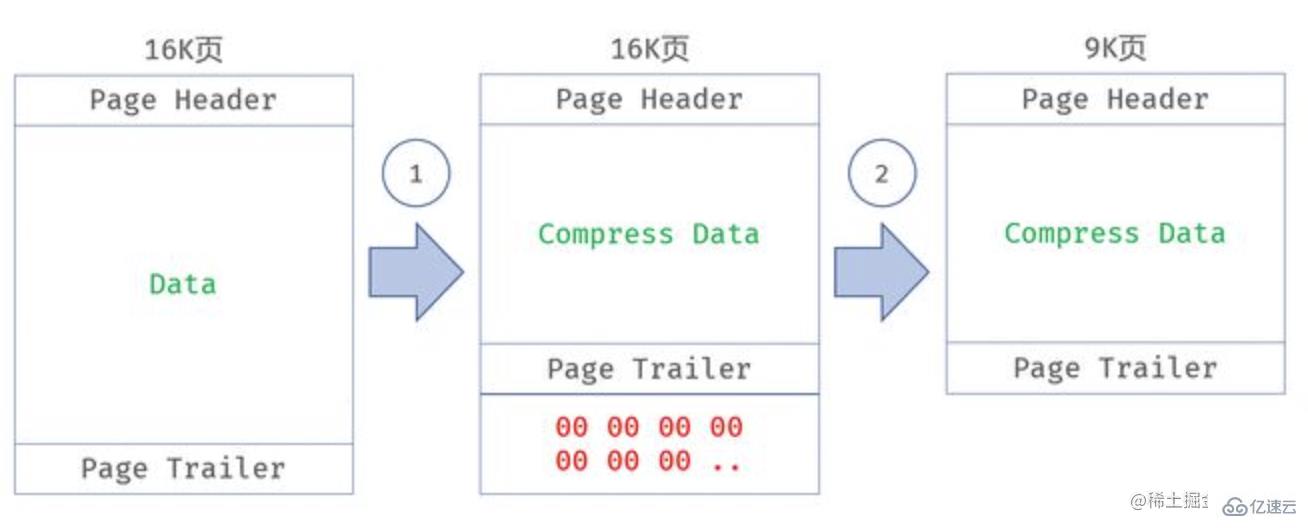
TPC雖好,但它依賴操作系統的 Hole Punch 特性,且裁剪后的文件大小需要和文件系統塊大小對齊(4K)。即假如壓縮后的頁大小是9K,那么實際占用的空間是12K
MySQL目前沒有直接針對列壓縮的方案,有一個曲線救國的方法,就是在業務層使用MySQL提供的壓縮和解壓函數來針對列進行壓縮和解壓操作。也就是如果需要對某一列做壓縮,在寫入時調用COMPRESS函數對那個列的內容進行壓縮,讀取的時候,使用UNCOMPRESS函數對壓縮過的數據進行解壓。
使用場景:針對表中某些列數據長度比較大的情況,一般是 varchar、text、blob、json等數據類型
相關函數:
壓縮函數:COMPRESS()
解壓縮函數:UNCOMPRESS()
字符串長度函數:LENGTH()
未解壓字符串長度函數:UNCOMPRESSED_LENGTH()
測試:
插入數據:insert into xxx (content) values (compress('xxx....'))
讀取壓縮的數據:select c_id, uncompressed_length(c_content) uncompress_len, length(c_content) compress_len from xxx
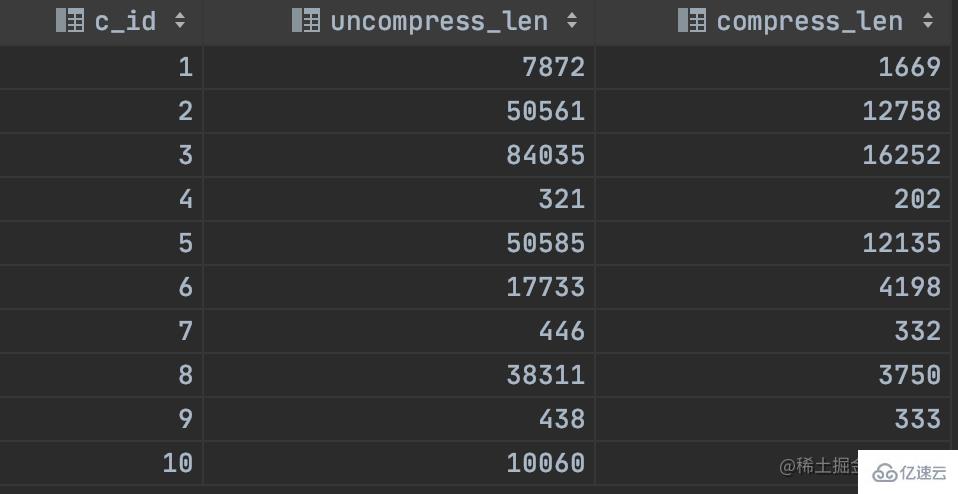
記錄壓縮:每次讀寫記錄的時候,都要進行壓縮或解壓,過度依賴CPU的計算能力,性能相對會比較差
表空間壓縮:壓縮效率高,但要求表空間文件是靜態不增長的,這對于我們大部分的場景都是不適用的
頁面壓縮:既能提升效率,又能在性能中取得一定的平衡
對于一些性能不敏感的業務表,如日志表、監控表、告警表等,這些表只期望對存儲空間進行優化,對性能的影響不是很關注,可以使用COMPRESS頁壓縮
對于一些比較核心的表,則比較推薦使用TPC壓縮
列壓縮過度依賴CPU,性能方面會稍差,且對業務有一定的改造成本,不夠靈活,需要評估影響范圍,做好切換的方案。好處是可以由業務端決定哪些數據需要壓縮,并控制解壓操作
對頁面進行壓縮,在業務側不用進行什么改動,對線上完全透明,壓縮方案也非常成熟
由于處理器和高速緩存存儲器的速度提高超過了磁盤存儲設備,因此很多時候工作負載都是受限于磁盤I/O。數據壓縮可以使數據占用更小的空間,可以節省磁盤I/O、減少網絡I/O從而提高吞吐量,雖然會犧牲部分CPU資源作為代價
對于OLTP系統,經常進行update、delete、insert等操作,通過壓縮表能夠減少存儲占用和IO消耗
壓縮其實是一種平衡,并不一定是為了提升數據庫的性能,這種平衡取決于解壓縮帶來的收益和開銷之間的一種權衡,但壓縮對存儲空間來說,收益無疑是很大的
create table table_origin ( ...... ) comment '測試原表';
create table table_compression_zlib ( ...... ) comment '測試壓縮表_zlib' compression = 'zlib';
create table table_compression_lz4 ( ...... ) comment '測試壓縮表_lz4' compression = 'lz4';
SELECT NAME, FS_BLOCK_SIZE, FILE_SIZE, ALLOCATED_SIZE
FROM information_schema.INNODB_TABLESPACES WHERE NAME like 'test_compress%';

FS_BLOCK_SIZE:文件系統塊大小,也就是打孔使用的單位大小
FILE_SIZE:文件的表觀大小,表示文件的最大大小,未壓縮
ALLOCATED_SIZE:文件的實際大小,即磁盤上分配的空間量
壓縮率:
zlib:1320636416/3489660928 = 37.8%
lz4:1566949376/3489660928 = 45%
循環插入10w條記錄
原表:918275 ms
zlib:878540 ms
lz4:875259 ms
循環查詢10w條記錄
原表:332519 ms
zlib:373387 ms
lz4:343501 ms
以上就是“MySQL中如何進行大文本存儲壓縮”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





