溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
?????? Ceph塊設備,以前稱為 RADOS 塊設備,為客戶機提供可靠的、分布式的和高性能的塊存儲磁盤。?
RADOS 塊設備利用 librbd 庫并以順序的形式在 Ceph 集群中的多個 osd 上存儲數據塊。RBD是由 Ceph 的 RADOS 層支持的,因此每個塊設備都分布在多個 Ceph 節點上,提供了高性能和優異的可靠性。RBD 有 linux 內核的本地支持。
?????? 任何普通的 linux 主機都可以充當 Ceph 的客戶機。客戶端通過網絡與 Ceph 存儲集群交互以存儲或檢索用戶數據。Ceph RBD 支持已經添加到 Linux主線內核中,從 2.6.34和以后的版本開始。
192.168.3.158為客戶端做如下操作
[root@localhost?~]#?cat?/etc/hosts …… 192.168.3.165?ceph265 192.168.3.166?ceph266 192.168.3.167?ceph267 192.168.3.158?ceph258 [root@localhost?~]#?hostnamectl?set-hostname?ceph258
#?wget?-O?/etc/yum.repos.d/ceph.repo?https://raw.githubusercontent.com/aishangwei/ceph-demo/master/ceph-deploy/ceph.repo
#?mkdir?-p?/etc/ceph
#?yum?-y?install?epel-release #?yum?-y?install?ceph #?cat?/etc/ceph/ceph.client.rbd.keyring
# 創建 ceph 塊客戶端用戶名和認證密鑰
[ceph@ceph265?my-cluster]$?ceph?auth?get-or-create?client.rbd?mon?'allow?r'?osd?'allow?class-read?object_prefix?rbd_children,?allow?rwx?pool=rbd'?|?tee?./ceph.client.rbd.keyring [client.rbd] ???key?=?AQBLBwRepKVJABAALyRx67z6efeI4xogPqHkyw== ??注:?client.rbd?為客戶端名 ?????mon?之后的全為授權配置
拷貝配置文件及密鑰到客戶機
[ceph@ceph265?my-cluster]$?scp?ceph.client.rbd.keyring?root@192.168.3.158:/etc/ceph [ceph@ceph265?my-cluster]$?scp?ceph.conf?root@192.168.3.158:/etc/ceph
# 檢查是否符合塊設備環境要求
uname?-r modprobe?rbd
#安裝 ceph 客戶端
#?wget?-O?/etc/yum.repos.d/ceph.repo?https://raw.githubusercontent.com/aishangwei/ceph-demo/master/ceph-deploy/ceph.repo
查看密鑰文件
[root@ceph258?~]#?cat?/etc/ceph/ceph.client.rbd.keyring? [client.rdb] ???key?=?AQBLBwRepKVJABAALyRx67z6efeI4xogPqHkyw== [root@ceph258?~]#?ceph?-s?--name?client.rbd

在服務器192.168.3.165執行如下命令
(1) 創建塊設備
? ? ? 默認創建塊設備,會直接創建在 rbd 池中,但使用 deploy 安裝后,該 rbd 池并沒有創建。
# 創建池和塊
$?ceph?osd?lspools????#?查看集群存儲池 $?ceph?osd?pool?create?rbd?50 ???pool?'rbd'?created???#?50?為?place?group?數量,由于我們后續測試,也需要更多的?pg,所以這里設置為50
確定pg_num取值是強制性的,因為不能自動計算。下面是幾個常用的值:
? ? ?少于5個OSD時可把pg_num設置為128
? ? ?OSD數量在5到10個時,可把pg_num設置為512
? ? ?OSD數量在10到50個時,可把pg_num設置為4096
? ? ?OSD數量大于50時,你得理解權衡方法、以及如何自己計算pg_num取值

(2)客戶端創建 塊設備
創建一個容量為 5105M 的 rbd 塊設備
[root@ceph258?~]#?rbd?create?rbd2?--size?5105?--name?client.rbd

192.168.3.158 客戶端查看 rbd2 塊設備
[root@ceph258?~]#?rbd?ls?--name?client.rbd ?rbd2 [root@ceph258?~]#?rbd?ls?-p?rbd?--name?client.rbd ?rbd2 [root@ceph258?~]#?rbd?list?--name?client.rbd ?rbd2

查看 rbd2塊設備信息
[root@ceph258?~]#?rbd?--image?rbd2?info?--name?client.rbd

# 映射到客戶端,應該會報錯
[root@ceph258?~]#?rbd?map?--image?rbd2?--name?client.rbd

layering:分層支持
? ? ? ? - exclusive-lock:排它鎖定支持對
? ? ? ? - object-map:對象映射支持(需要排它鎖定(exclusive-lock))
? ? ? ? - deep-flatten:快照平支持(snapshot flatten support)
? ? ? ? - fast-diff:在client-node1上使用krbd(內核rbd)客戶機進行快速diff計算(需要對象映射),我們將無法在CentOS內核3.10上映射塊設備映像,因為該內核不支持對象映射(object-map)、深平(deep-flatten)和快速dif(fast-dif)(在內核4.9中引入了支持)。為了解決這個問題,我們將禁用不支持的特性,有幾個選項可以做到這一點:
1)動態禁用
rbd?feature?disable?rbdl?exclusive-lock?object-map?deep-flatten?fast-diff--name?client.rbd
2)創建RBD鏡像時,只啟用分層特性。
rbd?create?rbd2?--size?10240?--image-feature?layering--name?client.rbd
3)ceph配置文件中禁用
rbd_default_features=1
# 我們這里動態禁用
[root@ceph258?~]#?rbd?feature?disable?rbd2?exclusive-lock?object-map?fast-diff?deep-flatten?--name?client.rbd

對 rbd2 進行映射
[root@ceph258?~]#?rbd?map?--image?rbd2?--name?client.rbd

查看本機已經映射的 rbd 鏡像
[root@ceph258?~]#?rbd?showmapped?--name?client.rbd

查看磁盤 rbd0 大小

格式化 rbd0

創建掛載目錄并進行掛載
[root@ceph258?~]#?mkdir?/mnt/ceph-disk1 [root@ceph258?~]#?mount?/dev/rbd0?/mnt/ceph-disk1/

# 寫入數據測試
[root@ceph258?~]#?dd?if=/dev/zero?of=/mnt/ceph-disk1/file1?count=100?bs=1M


# 做成服務,開機自動掛載
[root@ceph203-]#?wget?-O?/usr/local/bin/rbd-mount?https://raw.githubusercontent.com/aishangwei/ceph-demo/master/client/rbd-mount
# vim /usr/local/bin/rbd-mount

[root@ceph258?~]#?chmod?+x?/usr/local/bin/rbd-mount [root@ceph258~?]#?wget?-O?/etc/systemd/system/rbd-mount.service?https://raw.githubusercontent.com/aishangwei/ceph-demo/master/client/rbd-mount.service [root@ceph258?~]#?systemctl?daemon-reload [root@ceph258?~]#?systemctl?enable?rbd-mount.service Created?symlink?from?/etc/systemd/system/multi-user.target.wants/rbd-mount.service?to?/etc/systemd/system/rbd-mount.service.

卸載手動掛載的目錄,進行服務自動掛載測試
[root@ceph258?~]#?umount?/mnt/ceph-disk1/ [root@ceph258?~]#?systemctl?status?rbd-mount

Ceph: RBD 在線擴容容量
Ceph管理端的操作
查詢 pool 總容量及已經分配容量
[root@ceph265?~]#?ceph?df

查看已經存在的 pool
[root@ceph265?~]#?ceph?osd?lspools

查看已經有的 rbd

開始對 rbd2 進行動態擴容
[root@ceph265?~]#?rbd?resize?rbd/rbd2?--size?7168

Ceph客戶端的操作
[root@ceph258?~]#?rbd?showmapped

[root@ceph258?~]#?df?-h

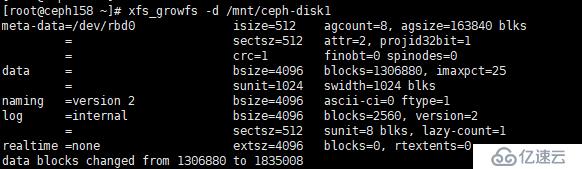
[root@ceph258?~]#?xfs_growfs?-d?/mnt/ceph-disk1

? ? ? ?輸入ceph-deploy mon create-initial命令獲取密鑰key,會在當前目錄(如我的是~/etc/ceph/)下生成幾個key,但報錯如下。意思是:就是配置失敗的兩個結點的配置文件的內容于當前節點不一致,提示使用--overwrite-conf參數去覆蓋不一致的配置文件。
#?ceph-deploy?mon?create-initial
...
[ceph3][DEBUG?]?remote?hostname:?ceph3
[ceph3][DEBUG?]?write?cluster?configuration?to?/etc/ceph/{cluster}.conf
[ceph_deploy.mon][ERROR?]?RuntimeError:?config?file?/etc/ceph/ceph.conf?exists?with?different?content;?use?--overwrite-conf?to?overwrite
[ceph_deploy][ERROR?]?GenericError:?Failed?to?create?2?monitors
...輸入命令如下(此處我共配置了三個結點ceph2~3):
#?ceph-deploy?--overwrite-conf?mon?create?ceph{3,1,2}
...
[ceph3][DEBUG?]?remote?hostname:?ceph3
[ceph3][DEBUG?]?write?cluster?configuration?to?/etc/ceph/{cluster}.conf
[ceph3][DEBUG?]?create?the?mon?path?if?it?does?not?exist
[ceph3][DEBUG?]?checking?for?done?path:?/var/lib/ceph/mon/ceph-ceph3/done
...之后配置成功,可繼續進行初始化磁盤操作。
[root@ceph2?ceph]#?ceph?-s cluster: id:?8e2248e4-3bb0-4b62-ba93-f597b1a3bd40 health:?HEALTH_WARN too?few?PGs?per?OSD?(21?<?min?30) services: mon:?3?daemons,?quorum?ceph3,ceph2,ceph4 ……
? ? ? ?從上面集群狀態信息可查,每個osd上的pg數量=21<最小的數目30個。pgs為32,因為我之前設置的是2副本的配置,所以當有3個osd的時候,每個osd上均分了32÷3*2=21個pgs,也就是出現了如上的錯誤 小于最小配置30個。
? ? ? ?集群這種狀態如果進行數據的存儲和操作,會發現集群卡死,無法響應io,同時會導致大面積的osd down。
解決辦法:
? ? ? 增加pg數
? ? ? 因為我的一個pool有8個pgs,所以我需要增加兩個pool才能滿足osd上的pg數量=48÷3*2=32>最小的數目30。
[root@ceph2?ceph]#?ceph?osd?pool?create?mytest?8 pool?'mytest'?created [root@ceph2?ceph]#?ceph?osd?pool?create?mytest1?8 pool?'mytest1'?created [root@ceph2?ceph]#?ceph?-s cluster: id:?8e2248e4-3bb0-4b62-ba93-f597b1a3bd40 health:?HEALTH_OK services: mon:?3?daemons,?quorum?ceph3,ceph2,ceph4 mgr:?ceph3(active),?standbys:?ceph2,?ceph4 osd:?3?osds:?3?up,?3?in rgw:?1?daemon?active data: pools:?6?pools,?48?pgs objects:?219?objects,?1.1?KiB usage:?3.0?GiB?used,?245?GiB?/?248?GiB?avail pgs:?48?active+clean
集群健康狀態顯示正常。
如果此時,查看集群狀態是HEALTH_WARN application not enabled on 1 pool(s):
[root@ceph2?ceph]#?ceph?-s cluster: id:?13430f9a-ce0d-4d17-a215-272890f47f28 health:?HEALTH_WARN application?not?enabled?on?1?pool(s) [root@ceph2?ceph]#?ceph?health?detail HEALTH_WARN?application?not?enabled?on?1?pool(s) POOL_APP_NOT_ENABLED?application?not?enabled?on?1?pool(s) application?not?enabled?on?pool?'mytest' use?'ceph?osd?pool?application?enable?<pool-name>?<app-name>',?where?<app-name>?is?'cephfs',?'rbd',?'rgw',?or?freeform?for?custom?applications.
運行ceph health detail命令發現是新加入的存儲池mytest沒有被應用程序標記,因為之前添加的是RGW實例,所以此處依提示將mytest被rgw標記即可:
[root@ceph2?ceph]#?ceph?osd?pool?application?enable?mytest?rgw enabled?application?'rgw'?on?pool?'mytest'
再次查看集群狀態發現恢復正常
[root@ceph2?ceph]#?ceph?health HEALTH_OK
? ? ? ?以下以刪除mytest存儲池為例,運行ceph osd pool rm mytest命令報錯,顯示需要在原命令的pool名字后再寫一遍該pool名字并最后加上--yes-i-really-really-mean-it參數
[root@ceph2?ceph]#?ceph?osd?pool?rm?mytest Error?EPERM:?WARNING:?this?will?*PERMANENTLY?DESTROY*?all?data?stored?in?pool?mytest.?If?you?are?*ABSOLUTELY?CERTAIN*?that?is?what?you?want,?pass?the?pool?name?*twice*,?followed?by?--yes-i-really-really-mean-it.
? ? ? ? 按照提示要求復寫pool名字后加上提示參數如下,繼續報錯:
[root@ceph2?ceph]#?ceph?osd?pool?rm?mytest?mytest?--yes-i-really-really-mean-it Error?EPERM:?pool?deletion?is?disabled;?you?must?first?set?the? mon_allow_pool_delete?config?option?to?true?before?you?can?destroy?a?pool
? ? ? ?錯誤信息顯示,刪除存儲池操作被禁止,應該在刪除前現在ceph.conf配置文件中增加mon_allow_pool_delete選項并設置為true。所以分別登錄到每一個節點并修改每一個節點的配置文件。操作如下:
[root@ceph2?ceph]#?vi?ceph.conf? [root@ceph2?ceph]#?systemctl?restart?ceph-mon.target
? ? ? ?在ceph.conf配置文件底部加入如下參數并設置為true,保存退出后使用systemctl restart ceph-mon.target命令重啟服務。
? ? ? [mon]
? ? ? mon allow pool delete = true
其余節點操作同理。
[root@ceph3?ceph]#?vi?ceph.conf? [root@ceph3?ceph]#?systemctl?restart?ceph-mon.target [root@ceph4?ceph]#?vi?ceph.conf? [root@ceph4?ceph]#?systemctl?restart?ceph-mon.target
再次刪除,即成功刪除mytest存儲池。
[root@ceph2?ceph]#?ceph?osd?pool?rm?mytest?mytest?--yes-i-really-really-mean-it pool?'mytest'?removed
筆者將ceph集群中的三個節點分別關機并重啟后,查看ceph集群狀態如下:
[root@ceph2?~]#?ceph?-s
cluster:
id:?13430f9a-ce0d-4d17-a215-272890f47f28
health:?HEALTH_WARN
1?MDSs?report?slow?metadata?IOs
324/702?objects?misplaced?(46.154%)
Reduced?data?availability:?126?pgs?inactive
Degraded?data?redundancy:?144/702?objects?degraded?(20.513%),?3?pgs?degraded,?126?pgs?undersized
services:
mon:?3?daemons,?quorum?ceph3,ceph2,ceph4
mgr:?ceph2(active),?standbys:?ceph3,?ceph4
mds:?cephfs-1/1/1?up?{0=ceph2=up:creating}
osd:?3?osds:?3?up,?3?in;?162?remapped?pgs
data:
pools:?8?pools,?288?pgs
objects:?234?objects,?2.8?KiB
usage:?3.0?GiB?used,?245?GiB?/?248?GiB?avail
pgs:?43.750%?pgs?not?active
144/702?objects?degraded?(20.513%)
324/702?objects?misplaced?(46.154%)
162?active+clean+remapped
123?undersized+peered
3?undersized+degraded+peered查看
[root@ceph2?~]#?ceph?health?detail HEALTH_WARN?1?MDSs?report?slow?metadata?IOs;?324/702?objects?misplaced?(46.154%);?Reduced?data?availability:?126?pgs?inactive;?Degraded?data?redundancy:?144/702?objects?degraded?(20.513%),?3?pgs?degraded,?126?pgs?undersized MDS_SLOW_METADATA_IO?1?MDSs?report?slow?metadata?IOs mdsceph2(mds.0):?9?slow?metadata?IOs?are?blocked?>?30?secs,?oldest?blocked?for?42075?secs OBJECT_MISPLACED?324/702?objects?misplaced?(46.154%) PG_AVAILABILITY?Reduced?data?availability:?126?pgs?inactive pg?8.28?is?stuck?inactive?for?42240.369934,?current?state?undersized+peered,?last?acting?[0] pg?8.2a?is?stuck?inactive?for?45566.934835,?current?state?undersized+peered,?last?acting?[0] pg?8.2d?is?stuck?inactive?for?42240.371314,?current?state?undersized+peered,?last?acting?[0] pg?8.2f?is?stuck?inactive?for?45566.913284,?current?state?undersized+peered,?last?acting?[0] pg?8.32?is?stuck?inactive?for?42240.354304,?current?state?undersized+peered,?last?acting?[0] .... pg?8.28?is?stuck?undersized?for?42065.616897,?current?state?undersized+peered,?last?acting?[0] pg?8.2a?is?stuck?undersized?for?42065.613246,?current?state?undersized+peered,?last?acting?[0] pg?8.2d?is?stuck?undersized?for?42065.951760,?current?state?undersized+peered,?last?acting?[0] pg?8.2f?is?stuck?undersized?for?42065.610464,?current?state?undersized+peered,?last?acting?[0] pg?8.32?is?stuck?undersized?for?42065.959081,?current?state?undersized+peered,?last?acting?[0] ....
可見在數據修復中, 出現了inactive和undersized的值, 則是不正常的現象
解決方法:
①處理inactive的pg:
重啟一下osd服務即可
[root@ceph2?~]#?systemctl?restart?ceph-osd.target
繼續查看集群狀態發現,inactive值的pg已經恢復正常,此時還剩undersized的pg。
[root@ceph2?~]#?ceph?-s
cluster:
id:?13430f9a-ce0d-4d17-a215-272890f47f28
health:?HEALTH_WARN
1?filesystem?is?degraded
241/723?objects?misplaced?(33.333%)
Degraded?data?redundancy:?59?pgs?undersized
services:
mon:?3?daemons,?quorum?ceph3,ceph2,ceph4
mgr:?ceph2(active),?standbys:?ceph3,?ceph4
mds:?cephfs-1/1/1?up?{0=ceph2=up:rejoin}
osd:?3?osds:?3?up,?3?in;?229?remapped?pgs
rgw:?1?daemon?active
data:
pools:?8?pools,?288?pgs
objects:?241?objects,?3.4?KiB
usage:?3.0?GiB?used,?245?GiB?/?248?GiB?avail
pgs:?241/723?objects?misplaced?(33.333%)
224?active+clean+remapped
59?active+undersized
5?active+clean
io:
client:?1.2?KiB/s?rd,?1?op/s?rd,?0?op/s?wr②處理undersized的pg:
學會出問題先查看健康狀態細節,仔細分析發現雖然設定的備份數量是3,但是PG 12.x卻只有兩個拷貝,分別存放在OSD 0~2的某兩個上。
[root@ceph2?~]#?ceph?health?detail? HEALTH_WARN?241/723?objects?misplaced?(33.333%);?Degraded?data?redundancy:?59?pgs?undersized OBJECT_MISPLACED?241/723?objects?misplaced?(33.333%) PG_DEGRADED?Degraded?data?redundancy:?59?pgs?undersized pg?12.8?is?stuck?undersized?for?1910.001993,?current?state?active+undersized,?last?acting?[2,0] pg?12.9?is?stuck?undersized?for?1909.989334,?current?state?active+undersized,?last?acting?[2,0] pg?12.a?is?stuck?undersized?for?1909.995807,?current?state?active+undersized,?last?acting?[0,2] pg?12.b?is?stuck?undersized?for?1910.009596,?current?state?active+undersized,?last?acting?[1,0] pg?12.c?is?stuck?undersized?for?1910.010185,?current?state?active+undersized,?last?acting?[0,2] pg?12.d?is?stuck?undersized?for?1910.001526,?current?state?active+undersized,?last?acting?[1,0] pg?12.e?is?stuck?undersized?for?1909.984982,?current?state?active+undersized,?last?acting?[2,0] pg?12.f?is?stuck?undersized?for?1910.010640,?current?state?active+undersized,?last?acting?[2,0]
進一步查看集群osd狀態樹,發現ceph3和cepn3宕機再恢復后,osd.1 和osd.2進程已不在ceph3和cepn3上。
[root@ceph2?~]#?ceph?osd?tree ID?CLASS?WEIGHT?TYPE?NAME?STATUS?REWEIGHT?PRI-AFF? -1?0.24239?root?default -9?0.16159?host?centos7evcloud 1?hdd?0.08080?osd.1?up?1.00000?1.00000? 2?hdd?0.08080?osd.2?up?1.00000?1.00000? -3?0.08080?host?ceph2 0?hdd?0.08080?osd.0?up?1.00000?1.00000? -5?0?host?ceph3 -7?0?host?ceph4
分別查看osd.1 和osd.2服務狀態。
解決方法:
分別進入到ceph3和ceph4節點中重啟osd.1 和osd.2服務,將這兩個服務重新映射到ceph3和ceph4節點中。
[root@ceph2?~]#?ssh?ceph3 [root@ceph3?~]#?systemctl?restart?ceph-osd@1.service [root@ceph3?~]#?ssh?ceph4 [root@ceph4?~]#?systemctl?restart?ceph-osd@2.service
最后查看集群osd狀態樹發現這兩個服務重新映射到ceph3和ceph4節點中。
[root@ceph4?~]#?ceph?osd?tree ID?CLASS?WEIGHT?TYPE?NAME?STATUS?REWEIGHT?PRI-AFF? -1?0.24239?root?default -9?0?host?centos7evcloud -3?0.08080?host?ceph2 0?hdd?0.08080?osd.0?up?1.00000?1.00000? -5?0.08080?host?ceph3 1?hdd?0.08080?osd.1?up?1.00000?1.00000? -7?0.08080?host?ceph4 2?hdd?0.08080?osd.2?up?1.00000?1.00000
集群狀態也顯示了久違的HEALTH_OK。
[root@ceph4?~]#?ceph?-s
cluster:
id:?13430f9a-ce0d-4d17-a215-272890f47f28
health:?HEALTH_OK
services:
mon:?3?daemons,?quorum?ceph3,ceph2,ceph4
mgr:?ceph2(active),?standbys:?ceph3,?ceph4
mds:?cephfs-1/1/1?up?{0=ceph2=up:active}
osd:?3?osds:?3?up,?3?in
rgw:?1?daemon?active
data:
pools:?8?pools,?288?pgs
objects:?241?objects,?3.6?KiB
usage:?3.1?GiB?used,?245?GiB?/?248?GiB?avail
pgs:?288?active+clean掛載命令如下:
mount?-t?ceph?10.0.86.246:6789,10.0.86.221:6789,10.0.86.253:6789:/?/mnt/mycephfs/?-o?name=admin,secret=AQBAI/JbROMoMRAAbgRshBRLLq953AVowLgJPw==
卸載CephFS后再掛載時報錯:mount error(2): No such file or directory
說明:首先檢查/mnt/mycephfs/目錄是否存在并可訪問,我的是存在的但依然報錯No such file or directory。但是我重啟了一下osd服務意外好了,可以正常掛載CephFS。
[root@ceph2?~]#?systemctl?restart?ceph-osd.target [root@ceph2?~]#?mount?-t?ceph?10.0.86.246:6789,10.0.86.221:6789,10.0.86.253:6789:/?/mnt/mycephfs/?-o?name=admin,secret=AQBAI/JbROMoMRAAbgRshBRLLq953AVowLgJPw==
可見掛載成功~!
[root@ceph2?~]#?df?-h Filesystem?Size?Used?Avail?Use%?Mounted?on /dev/vda2?48G?7.5G?41G?16%?/ devtmpfs?1.9G?0?1.9G?0%?/dev tmpfs?2.0G?8.0K?2.0G?1%?/dev/shm tmpfs?2.0G?17M?2.0G?1%?/run tmpfs?2.0G?0?2.0G?0%?/sys/fs/cgroup tmpfs?2.0G?24K?2.0G?1%?/var/lib/ceph/osd/ceph-0 tmpfs?396M?0?396M?0%?/run/user/0 10.0.86.246:6789,10.0.86.221:6789,10.0.86.253:6789:/?249G?3.1G?246G?2%?/mnt/mycephfs
參考鏈接
https://blog.csdn.net/SL_World/article/details/84584366
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





