溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Apache Doris Colocate Join原理是什么”,在日常操作中,相信很多人在Apache Doris Colocate Join原理是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Apache Doris Colocate Join原理是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
我們都知道 Join 的常見連接類型分為以下幾種:
INNER JOIN
OUTER JOIN
CROSS JOIN
SEMI JOIN
ANTI JOIN
Join 的常見算法實現包含以下幾種:
Nested Loop Join
Sort Merge Join
Hash Join
分布式系統實現 Join 數據分布的常見策略有:
Shuffle Join
Broadcast Join
Colocate/Local Join
Colocate/Local Join 就是指多個節點 Join 時沒有數據移動和網絡傳輸,每個節點只在本地進行 Join,能夠本地進行 Join 的前提是相同 Join Key 的數據分布在相同的節點。
相比 Shuffle Join 和 Broadcast Join,Colocate Join 在查詢時沒有數據的網絡傳輸,性能會更高。 在 Doris 的具體實現中,Colocate Join 相比 Shuffle Join 可以擁有更高的并發粒度,也可以顯著提升 Join 的性能,這一點在后面會解釋。
對于 colocate tables,在任何情況下都要保證數據的本地性。 具體包括:
數據導入時保證數據本地性
查詢調度時保證數據本地性
數據 balance 后保證數據本地性
實現中最復雜是第 3 點: 處理 colocate tables 的 balance。
Colocate Group
我們將一組具體相同 Colocate 屬性的 Table 稱為 Group,下圖中 t1 和 t2 擁有相同的 Colocate Group。
Colocate Parent Table
我們將決定一個 Group 數據分布的 Table 稱為 Parent Table,下圖中 t1 是 Colocate Parent Table.
Colocate Child Table
我們將一個 Group 中除 Parent Table 之外的 Table 稱為 Child Table,下圖中 t2 是 Colocate Child Table.

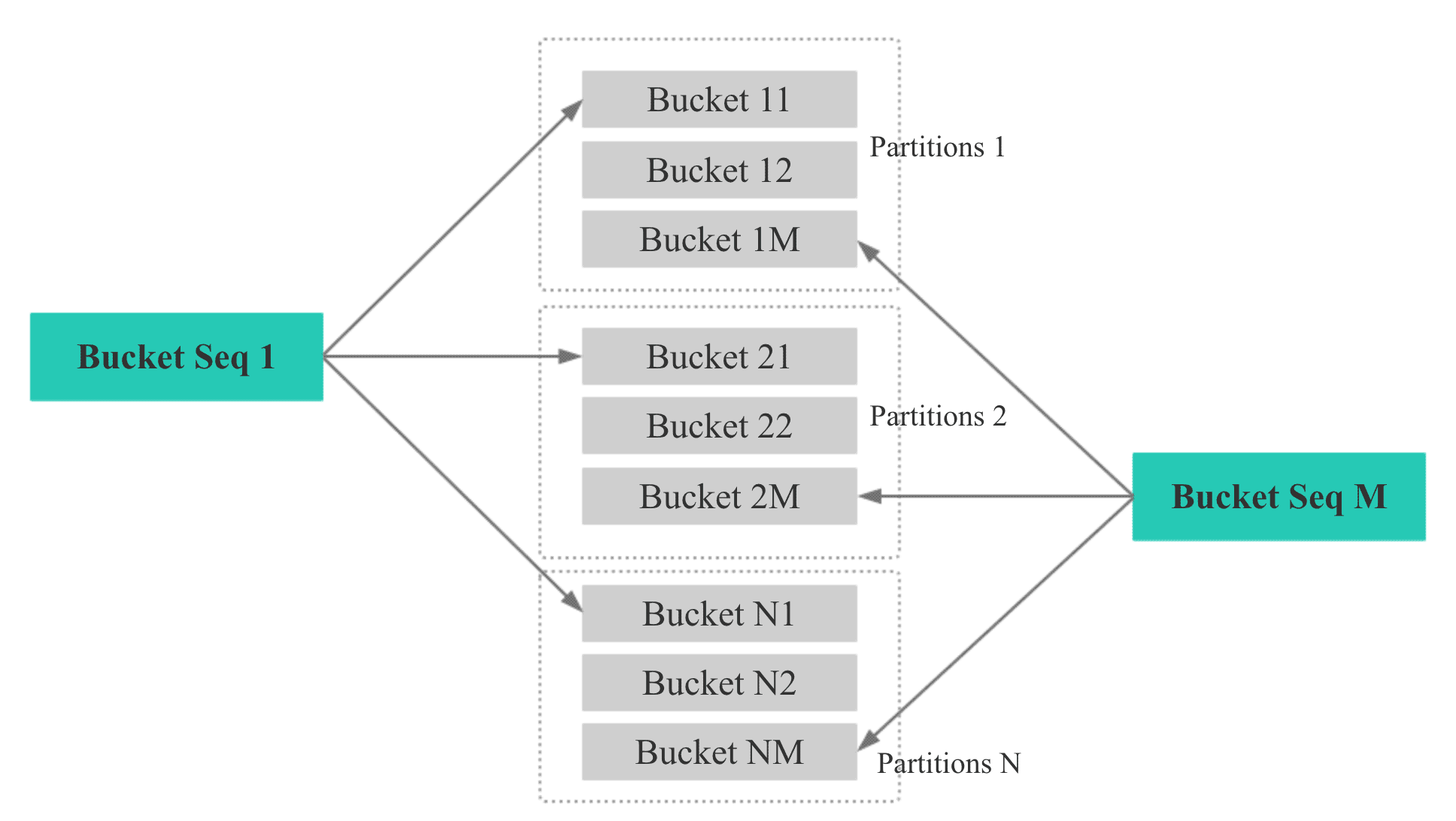
Bucket Seq
如下圖,如果一個表有 N 個 Partition, 則每個 Partition 的第 M 個 bucket 的 Bucket Seq 是 M。
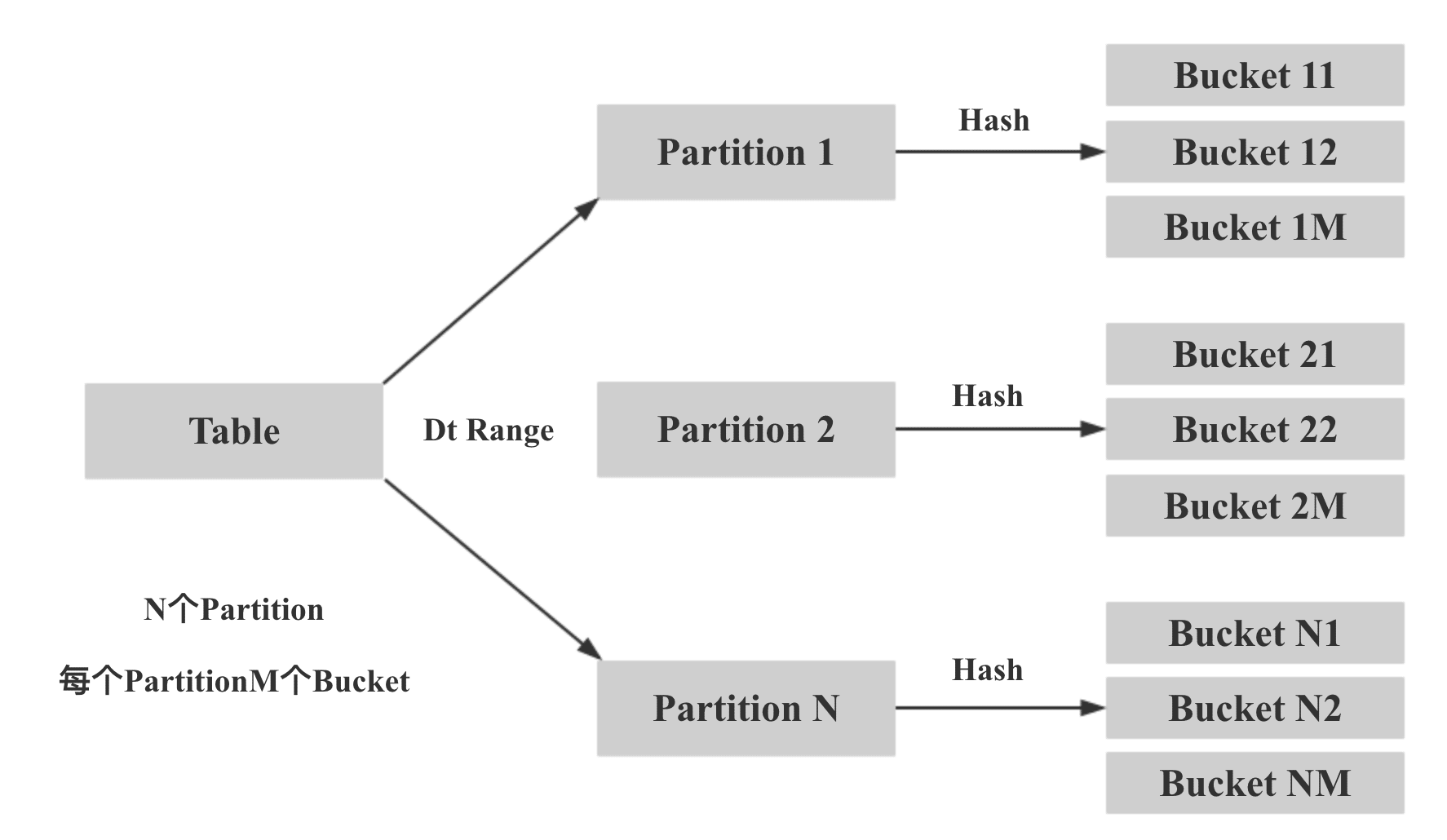
Doris 的分區方式如下所示,先根據分區字段 Range 分區,再根據指定的 Distributed Key Hash 分桶:
所以我們在數據導入時保證本地性的核心思想就是兩次映射,對于 colocate tables,我們保證相同 Distributed Key 的數據映射到相同的 Bucket Seq,再保證相同 Bucket Seq 的 buckets 映射到相同的 BE。

具體來說,第一步:我們計算 Distributed Key 的 hash 值,并對 bucket num 取模,保證相同 Distributed Key 的數據映射到相同的 Bucket Seq。
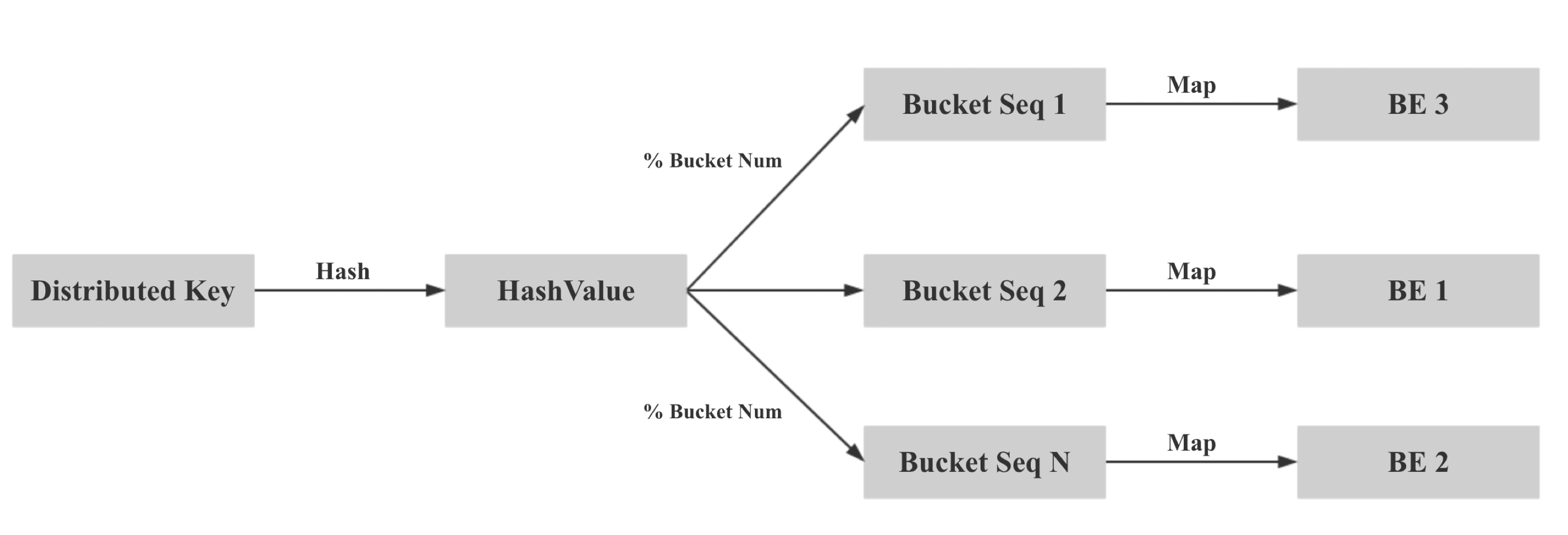
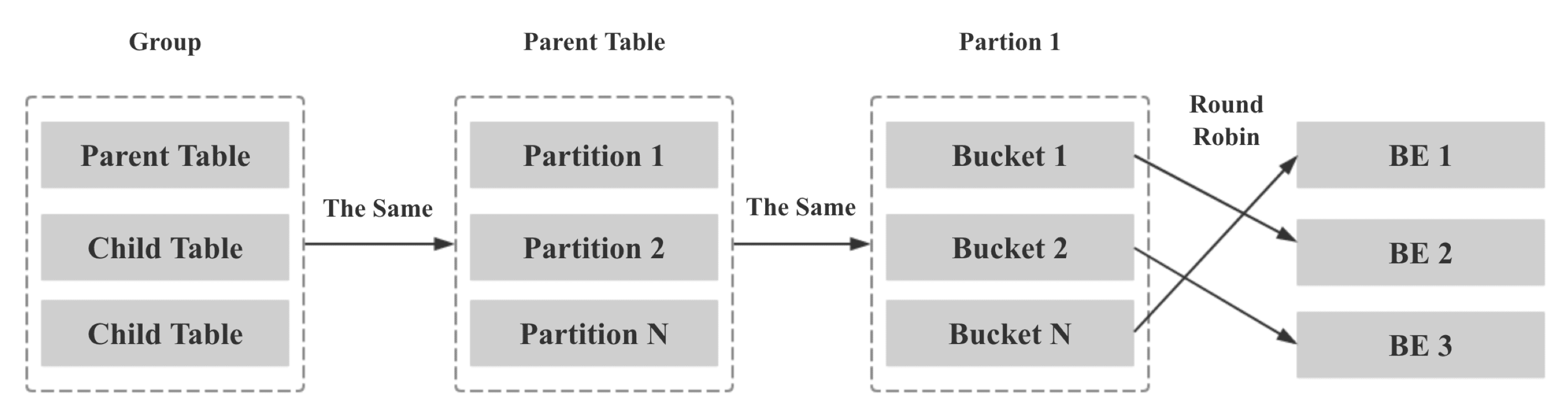
第二步:將同一個 Colocate Group 下所有相同 Bucket Seq 的 Bucket 映射到相同的 BE,方法如下:
Group 中所有 Table 的 Bucket Seq 和 BE 節點的映射關系和 Parent Table 一致
Parent Table 中所有 Partition 的 Bucket Seq 和 BE 節點的映射關系和第一個 Partition 一致
Parent Table 第一個 Partition 的 Bucket Seq 和 BE 節點的映射關系利用原生的 Round Robin 算法決定
對 HashJoinFragment,由于 Join 的多張表有了數據本地性保證,所以可以去掉 Exchange Node,避免網絡傳輸,將 ScanNode 直接設置為 Hash Join Node 的 Child。

查詢調度的目標: 一個 Colocate join 中所有 ScanNode 中所有 Bucket Seq 相同的 Buckets 被調度到同一個 BE。
查詢調度的策略:第一個 ScanNode 的 Buckets 隨機選擇 BE,其余的 ScanNode 和第一個 ScanNode 保持一致。
目前,Doris 的 Hash Join 是 Server 粒度的:
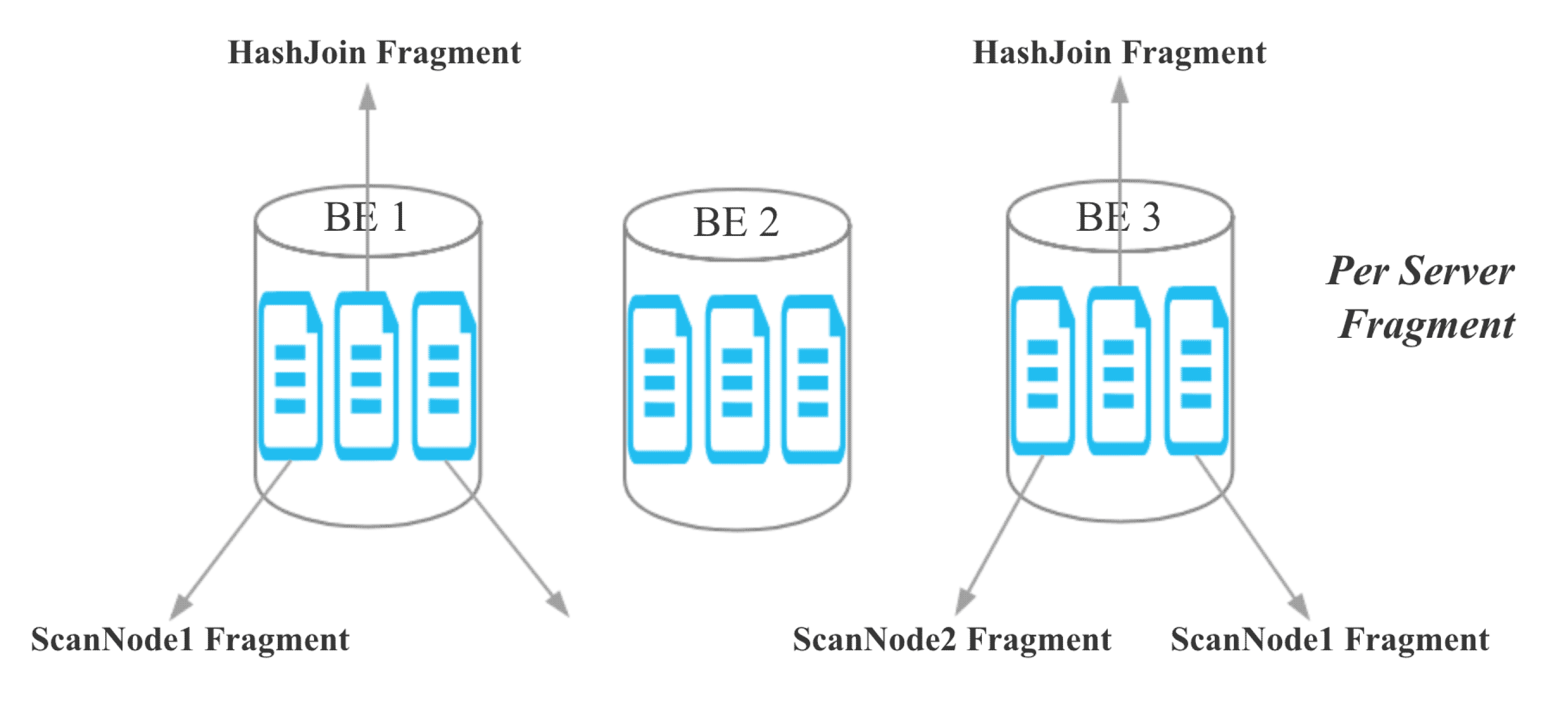
對于 colocate join,由于同一個 Colocate Group 下相同 Bucket Seq 的 Bucket 分布在相同的 BE,所以我們將 Join 的粒度從 Server 粒度降至 Bucket Seq 粒度:
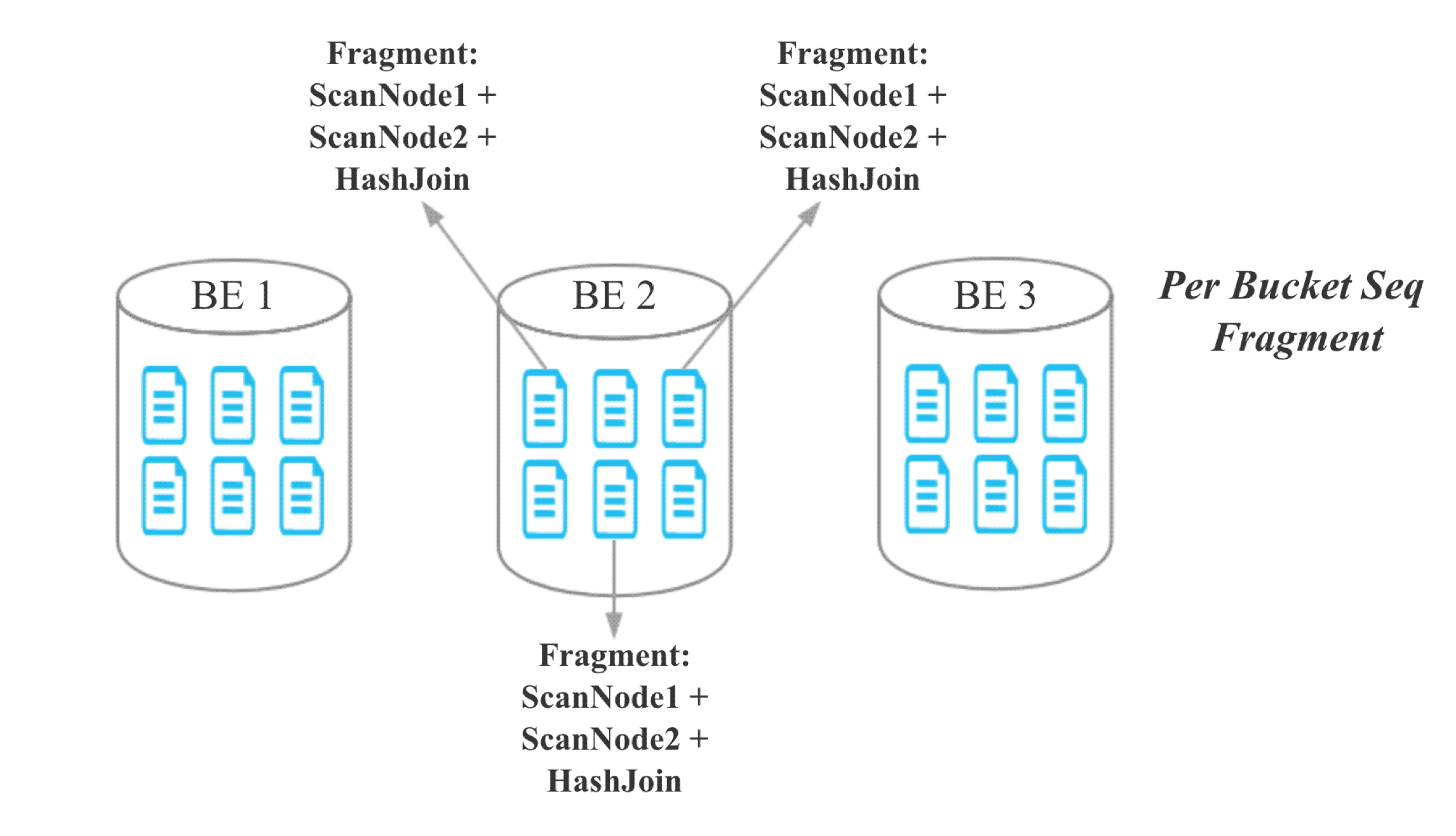
對于 colocate join,我們需要維護以下幾個核心元數據:

代碼中,colocate group id 就是 colocate parent table id
group2BackendsPerBucketSeq 代表每個 colocate group 中每個 bucket seq 映射到哪些 BE
為了支持 balance,以及保證元數據的一致性,這些元數據都需要持久化
Join 的 tables 是 colocate able
The colocate group 是 stable 狀態,沒有 balancing
Join 的 Key 包含分桶的 Distributed Key
核心思路:
新增一個 daemon 線程專門處理 colocate table 的 balance,并讓正常的 balance 線程不處理 colocate table 的 balance。
何時 balance:
有 BE 節點新增,刪除,down 掉時。
balance 的粒度:
正常 balance 的粒度是 bucket,但是對于 colocate table,我們必須保證同一個 colocate group 下所有 bucket 的數據本地性,所以我們 balance 的單位是 colocate group。
balance 對查詢的影響:
當一個 colocate group 正在 balance 時,colocate join 會退化為原始的 shuffle join 或 broadcast join。
balance 流程:
為需要復制或遷移的 Bucket 選擇目標 BE
標記 colocate group 的轉態為 balancing
對于需要復制或遷移的 Bucket,發起 Clone Job,Clone Job 會從 Bucket 的現有副本復制一個新副本目標 BE
更新 backendsPerBucketSeq(維護 Bucket Seq 到 BE 映射關系的元數據)
當一個 colocate group 下的所有 Clone Job 都完成時,標記 colocate group 的轉態為 stable
刪除冗余的副本
當有 BE 節點刪除或長時間掛掉時,選擇目標 BE 的策略:
和正常 balance 時的選擇策略相同,考慮集群的整體負載,盡量選擇負載較低的 BE。
當有 BE 節點新增時,選擇目標 BE 的策略:
對于當前 colocate group,計算每個新增 BE 需要增加的 bucket seqs 個數:假如我們有 3 個 BE,8 個 bucket,每個 bucket 是 3 副本,則每個 BE 負責 8 個 bucket 副本,我們新增 1 個 BE 后,可以計算出每個 BE 負責的平均 bucket 副本數應該是 3 * 8 / 4 = 6,每個新增 BE 需要增加的 bucket seqs 個數為 6 / 1 = 6.
對于每個 bucket seqs, 隨機選擇從哪個舊的 BE 遷移副本到新增的 BE。
測試數據:
Table A,B,C 都有 10 天數據,1 天一個 partitions,每個 partition 有 570 萬數據。
測試集群:
4 臺低配物理機,每個 BE 24CPU,96MEM
測試 SQL:
SQL1:
select count(*) FROM A t1 INNER JOIN [shuffle] B t5 ON ((t1.dt = t5.dt) AND (t1.id = t5.id)) INNER JOIN [shuffle] C t6 ON ((t1.dt = t6.dt) AND (t1.id = t6.id)) where t1.dt in (xxx days);
SQL2:
select t1.dt, t1.id, t1.name, t1.second_id,t1.second_name, t5.id, t5.weight_time,t5.list, t6.ord_id, t6._id FROM A t1 INNER JOIN B t5 ON ((t1.dt = t5.dt) AND (t1.id = t5.id)) INNER JOIN C t6 ON ((t1.dt = t6.dt) AND (t1.id = t6.id)) where t1.dt in (xxx days) limit 10000;
Test Result for SQL1:
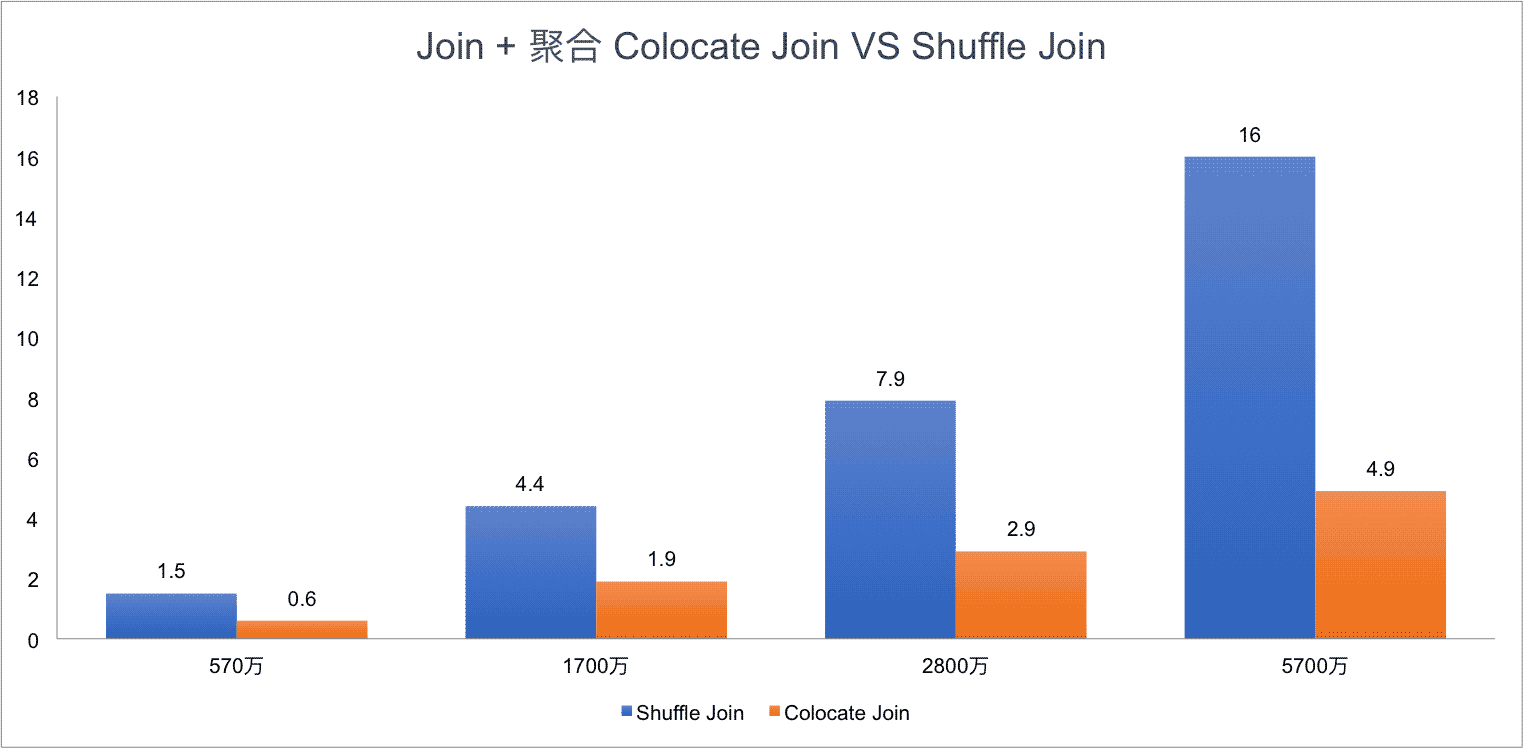
Test Result for SQL2:

可以看到,Colocate Join 相比 Shuffle Join 有明顯的性能提升,而且隨著集群規模越大,Join 的數據量越多,Colocate Join 的優勢會更明顯。
社區最新代碼已經支持 Colocate Join,只不過默認是關閉的,只需要在 FE 配置中設置 disable_colocate_join 為 false,即可開啟 Colocate Join 功能。
具體使用時只需要在建表時增加 colocate_with 這個屬性即可,colocate_with 的值可以設置成同一組 colocate 表中的任意一個,不過需要保證 colocate_with 屬性中的表要先建立。
假如需要對 table t1 和 t2 進行 Colocate Join,可以按以下語句建表:
CREATE TABLE `t1` ( `id` int(11) COMMENT "", `value` varchar(8) COMMENT "" ) ENGINE=OLAP DUPLICATE KEY(`id`) DISTRIBUTED BY HASH(`id`) BUCKETS 10 PROPERTIES ( "colocate_with" = "t1" ); CREATE TABLE `t2` ( `id` int(11) COMMENT "", `value` varchar(8) COMMENT "" ) ENGINE=OLAP DUPLICATE KEY(`id`) DISTRIBUTED BY HASH(`id`) BUCKETS 10 PROPERTIES ( "colocate_with" = "t1" );
Colocate Table 必須是 OLAP 類型的表
colocate_with 屬性相同表的 BUCKET 數必須一樣
colocate_with 屬性相同表的 副本數必須一樣 (這個限制之后可能會去掉,但對用戶應該沒有實際影響)
colocate_with 屬性相同表的 DISTRIBUTED Columns 的數據類型必須一樣
Colocate Join 十分適合幾張表按照相同字段分桶,并高頻根據相同字段 Join 的場景,比如電商的不少應用都按照商家 Id 分桶,并高頻按照商家 Id 進行 Join。
一句話總結,凡是不能進行 Colocate Join 的場景都會自動退化為原始的 Shuffle Join 或者 Broadcast Join。
Q1: 支持多張表進行 Colocate Join 嗎?
A: 支持
Q2: 支持 Colocate 表和正常表 Join 嗎?
A: 支持
Q3: Colocate 表支持用非分桶的 Key 進行 Join 嗎?
A: 支持:不符合 Colocate Join 條件的 Join 會使用 Shuffle Join 或 Broadcast Join
Q4: 如何確定 Join 是按照 Colocate Join 執行的?
A: explain 的結果中 Hash Join 的孩子節點如果直接是 OlapScanNode, 沒有 Exchange Node,就說明是 Colocate Join
Q5: 如何修改 colocate_with 屬性?
A: ALTER TABLE example_db.my_table set ("colocate_with"="target_table");
Q6: 如何禁用 colocate join?
A: set disable_colocate_join = true; 就可以禁用 Colocate Join,查詢時就會使用 Shuffle Join 或 Broadcast Join
到此,關于“Apache Doris Colocate Join原理是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





