溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
筆者找依賴的jar包,找的好辛苦。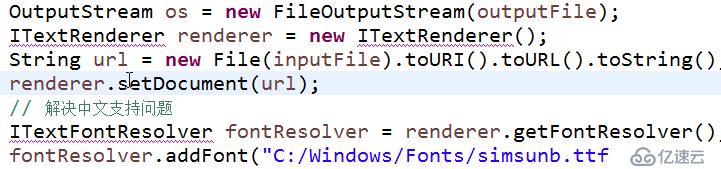
ITextRenderer、
ITextFontResolver這兩個類依賴的jar包到底是哪個,還有怎么下載?苦苦糾結了3個小時。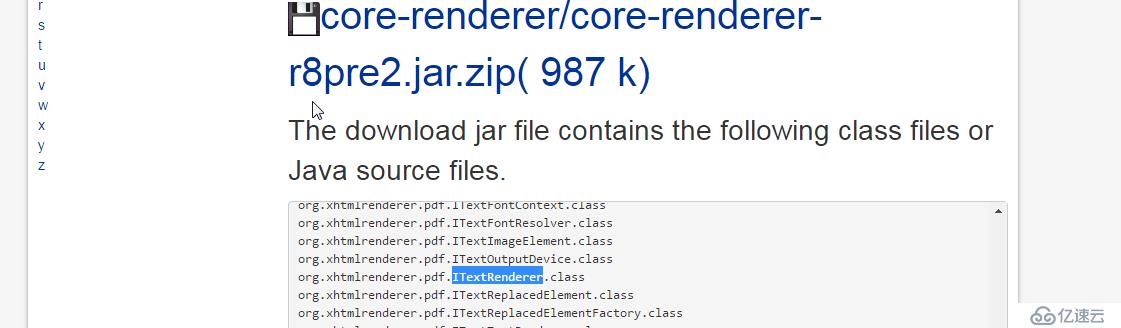
終于找到你了!
記錄個網址:
http://www.java2s.com/Code/Jar/c/Downloadcorerendererr8pre2jar.htm
上測試代碼:
/*
* html轉圖片
*/
public static boolean convertHtmlToPdf(String inputFile,
String outputFile, String imagePath)
throws Exception {
OutputStream os = new FileOutputStream(outputFile);
ITextRenderer renderer = new ITextRenderer();
String url = new File(inputFile).toURI().toURL().toString();
renderer.setDocument(url);
// 解決中文支持問題
ITextFontResolver fontResolver = renderer.getFontResolver();
fontResolver.addFont("C:/Windows/Fonts/simsunb.ttf", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
//解決圖片的相對路徑問題
renderer.getSharedContext().setBaseURL("file:/" + imagePath);//D:/test
renderer.layout();
renderer.createPDF(os);
os.flush();
os.close();
return true;
}調用+走你!
這里筆者結合上一篇poi將word轉html,結合使用。
/**doc
轉html
*/
String tagPath = "D:\red_ant_file\20180915\image\";
String sourcePath = "D:\red_ant_file\20180915\RedAnt的實驗作業.doc";
String outPath = "D:\red_ant_file\20180915\123.html";
try {
AllServiceIsHere.docToHtml(tagPath, sourcePath, outPath);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
String pdfPath = "D:\\red_ant_file\\20180915\\456.pdf";
try {
AllServiceIsHere.convertHtmlToPdf(outPath , pdfPath, tagPath);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}【注意】
(值得注意的地方是IText 根據html生成pdf文件的時候,會驗證html文件是否標準,例如通過poi轉換的出來的html文件的一些標簽會缺少標簽閉合 ” / “ :
否則,你會遇到
Can't load the XML resource (using TRaX transformer). org.xml.sax.SAXParseException; lineNumber: 23; columnNumber: 3; 元素類型 "meta" 必須由匹配的結束標記 "</meta>" 終止。
筆者嘗試,使用第三方 jar 包Jsoup, 直接調用 parse方法,筆者認為html就標準啦!
這個坑,讓筆者苦惱了,1個小時。
為此,筆者不得不重寫,word轉html代碼:
再次記錄個網址:下載第三方 jar 包Jsoup使用
https://jsoup.org/download
上重寫word轉html代碼:
// word 轉 html
public static void convert2Html(String fileName, String outPutFile) throws Exception {
HWPFDocument wordDocument = new HWPFDocument(new FileInputStream(fileName));// WordToHtmlUtils.loadDoc(new
// 兼容2007 以上版本
WordToHtmlConverter wordToHtmlConverter = new WordToHtmlConverter(
DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument());
wordToHtmlConverter.setPicturesManager(new PicturesManager() {
public String savePicture(byte[] content, PictureType pictureType, String suggestedName, float widthInches,
float heightInches) {
return "test/" + suggestedName;
}
});
wordToHtmlConverter.processDocument(wordDocument);
// save pictures
List pics = wordDocument.getPicturesTable().getAllPictures();
if (pics != null) {
for (int i = 0; i < pics.size(); i++) {
Picture pic = (Picture) pics.get(i);
System.out.println();
try {
pic.writeImageContent(new FileOutputStream("D:/test/" + pic.suggestFullFileName()));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
Document htmlDocument = wordToHtmlConverter.getDocument();
ByteArrayOutputStream out = new ByteArrayOutputStream();
DOMSource domSource = new DOMSource(htmlDocument);
StreamResult streamResult = new StreamResult(out);
TransformerFactory tf = TransformerFactory.newInstance();
Transformer serializer = tf.newTransformer();
serializer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
serializer.setOutputProperty(OutputKeys.INDENT, "yes");
serializer.setOutputProperty(OutputKeys.METHOD, "HTML");
serializer.transform(domSource, streamResult);
out.close();
writeFile(new String(out.toByteArray()), outPutFile);
}
//輸出html文件
public static void writeFile(String content, String path) {
FileOutputStream fos = null;
BufferedWriter bw = null;
org.jsoup.nodes.Document doc = Jsoup.parse(content);
content=doc.html();
try {
File file = new File(path);
fos = new FileOutputStream(file);
bw = new BufferedWriter(new OutputStreamWriter(fos,"UTF-8"));
bw.write(content);
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace();
} catch (IOException ioe) {
ioe.printStackTrace();
} finally {
try {
if (bw != null)
bw.close();
if (fos != null)
fos.close();
} catch (IOException ie) {
}
}
}準備個文件,測試一下。
String source = "D:\\red_ant_file\\20180915\\1303\\RedAnt的實驗作業.doc";
String out = "D:\\red_ant_file\\20180915\\1303\\789.html";
try {
AllServiceIsHere.convert2Html(source, out);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}word轉html,規范化代碼后的轉換結果。
接下來,html轉pdf
雖然筆者,最終調試出來了。使用這種方法轉pdf。
但是使用中,會遇到各種各樣的奇葩坑!因此筆者在這里不推薦使用這種方法。
原因就是,html的規則也在變化之中,寫法也在變化之中。html轉pdf會在后續報各種各樣的標簽錯誤。
筆者之所以粘出,這些代碼。完全是因為,筆者對自己的嘗試,有個明確的結果。亦或是,再優化這些代碼,找到合適的解決辦法。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





