溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
MySQL的歷史可以追溯到1979年,一個名為Monty Widenius的程序員在為TcX的小公司打工,并且用BASIC設計了一個報表工具,使其可以在4MHz主頻和16KB內存的計算機上運行。當時,這只是一個很底層的且僅面向報表的存儲引擎,名叫Unireg。【MySQL早期叫Unireg】早期輕量級,后來發展到巨無霸(淘寶、faceboock)MySQL AB是由MySQL創始人和主要開發人創辦的公司。MySQL AB最初是由David Axmark、Allan Larsson和Michael“Monty”Widenius在瑞典創辦的。
SQL標準:ANSI SQL
SQL-86, SQL-89, SQL-92, SQL-99, SQL-03
SQL主要分成四部分:
(1)數據定義。(SQL DDL)用于定義SQL模式、基本表、視圖和索引的創建和撤消操作。
(2)數據操縱。(SQL DML)數據操縱分成數據查詢和數據更新兩類。數據更新又分成插入、刪除、和修改三種操作。
(3)數據控制。包括對基本表和視圖的授權,完整性規則的描述,事務控制等內容。
(4)嵌入式SQL的使用規定。涉及到SQL語句嵌入在宿主語言程序中使用的規則。
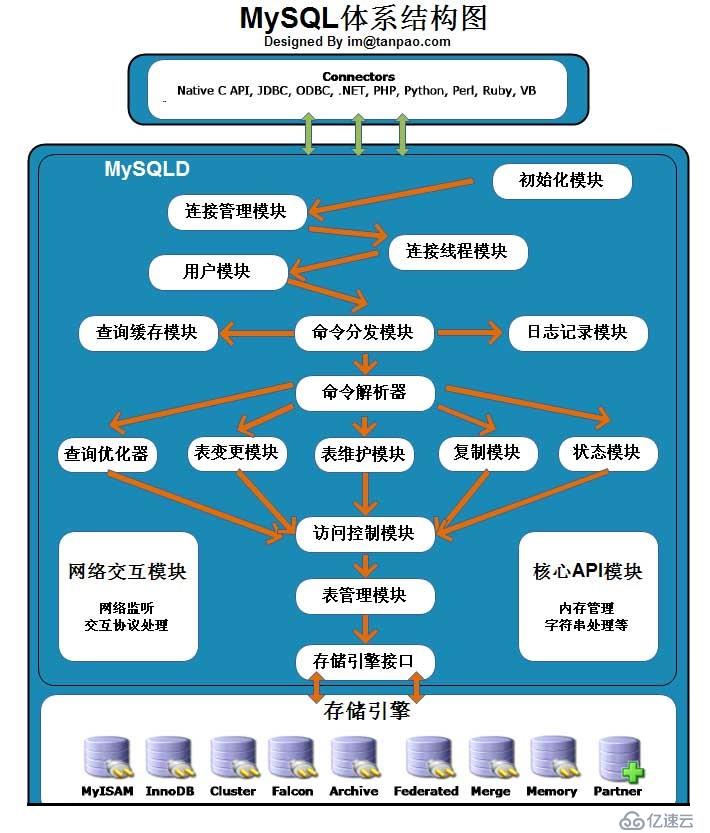
啟動3306端口 (連接池認證成功進入,不成功退出;(Check Memory -Caches)查詢緩存,直接查找該sql語句的執行結果,如果命中直接返回,否則繼續生成查詢計劃、解析sql語句;經優化,查找buffers cache里面的語句,嘗試加載buffers cache語句,如果buffers cache里沒有語句,則通過特定引擎與io設備進行交互。)
查詢的執行路徑: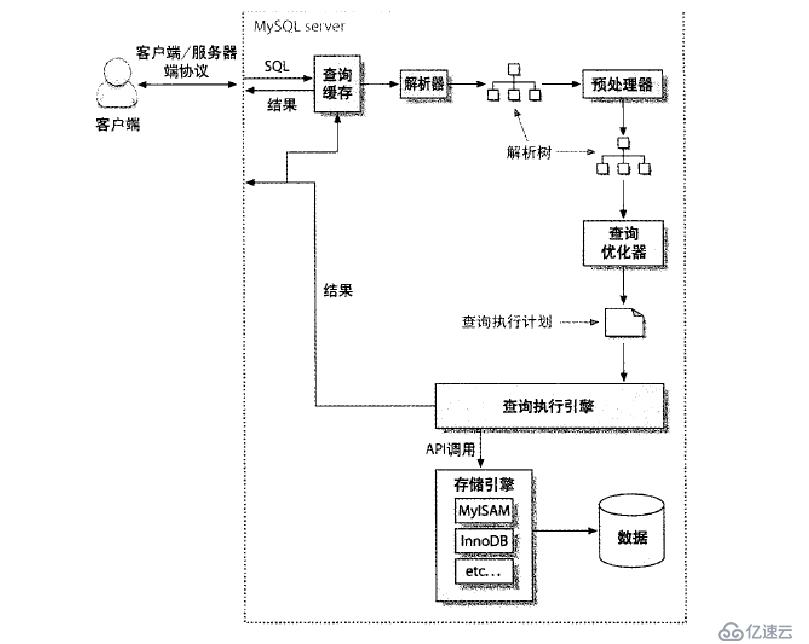
日常的學習和工作中我確認深深感受到數據結構和算法的重要性,很多東西,如果你愿意稍稍往深處挖一點,那么撲面而來的一定是各種數據結構和算法知識。
經典的BTREE索引數據結構如下圖: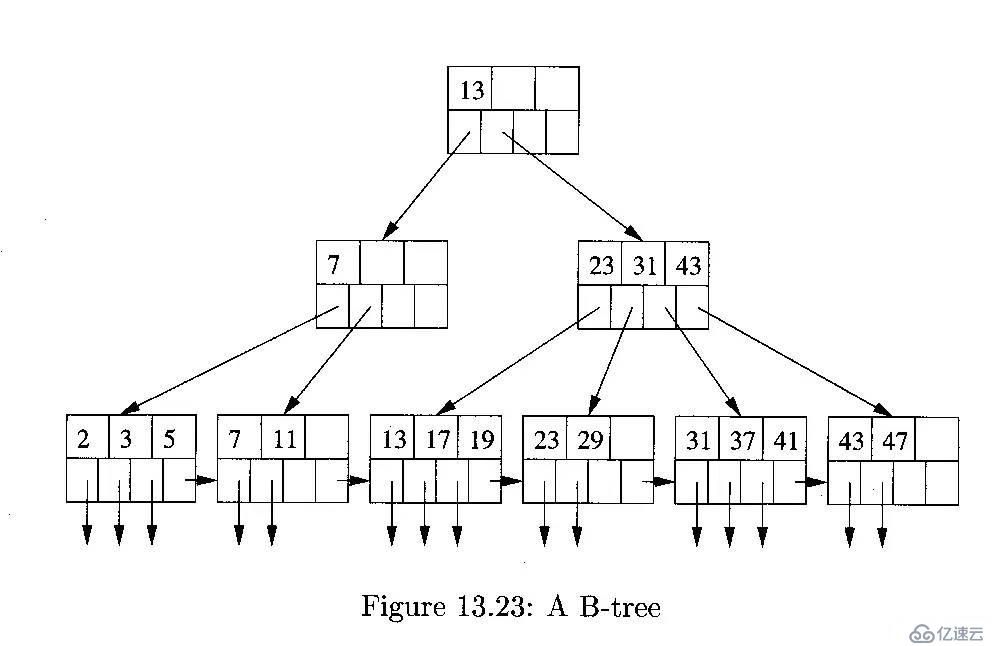
B-Tree 索引是 MySQL 數據庫中使用最為頻繁的索引類型,除了 Archive 存儲引擎之外的其他所有的存儲引擎都支持 B-Tree 索引。不僅僅在 MySQL 中是如此,實際上在其他的很多數據庫管理系統中B-Tree 索引也同樣是作為最主要的索引類型,這主要是因為B-Tree 索引的存儲結構在數據庫的數據檢索中有非常優異的表現。
一般來說, MySQL 中的 B-Tree 索引的物理文件大多都是以 Balance Tree 的結構來存儲的,也就是所有實際需要的數據都存放于 Tree 的 Leaf Node ,而且到任何一個 Leaf Node 的最短路徑的長度都是完全相同的,所以我們大家都稱之為 B-Tree 索引當然,可能各種數據庫(或 MySQL 的各種存儲引擎)在存放自己的 B-Tree 索引的時候會對存儲結構稍作改造。如 Innodb 存儲引擎的 B-Tree 索引實際使用的存儲結構實際上是 B+Tree ,也就是在 B-Tree 數據結構的基礎上做了很小的改造,在每一個Leaf Node 上面出了存放索引鍵的相關信息之外,還存儲了指向與該 Leaf Node 相鄰的后一個 LeafNode 的指針信息,這主要是為了加快檢索多個相鄰 Leaf Node 的效率考慮。
B+樹是一個平衡的多叉樹,從根節點到每個葉子節點的高度差值不超過1,而且同層級的節點間有指針相互鏈接。
在B+樹上的常規檢索,從根節點到葉子節點的搜索效率基本相當,不會出現大幅波動,而且基于索引的順序掃描時,也可以利用雙向指針快速左右移動,效率非常高。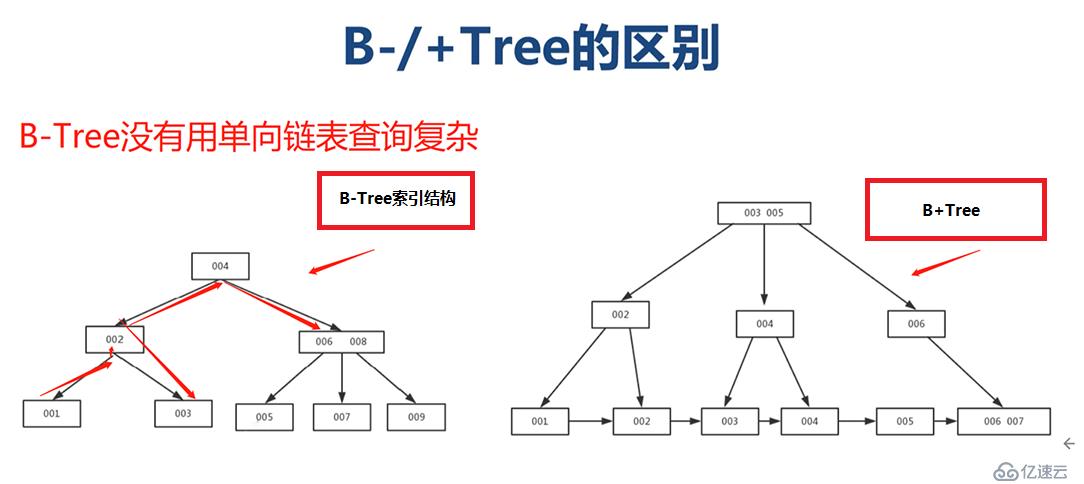
因此,B+樹索引被廣泛應用于數據庫、文件系統等場景。順便說一下,xfs文件系統比ext3/ext4效率高很多的原因之一就是,它的文件及目錄索引結構全部采用B+樹索引,而ext3/ext4的文件目錄結構則采用Linked list, hashed B-tree、Extents/Bitmap等索引數據結構,因此在高I/O壓力下,其IOPS能力不如xfs。
Lex & Yacc 是用來生成詞法分析器和語法分析器的工具,它們的出現簡化了編譯器的編寫。Lex & Yacc 分別是由貝爾實驗室的 Mike Lesk 和 Stephen C. Johnson 在 1975 年發布。
MySQL事務:
事務:一組原子性的SQL查詢,或者說一個獨立工作單元。
事務日志:
ACID測試:
A:atomicity,原子性;整個事務中的所有操作要么全部成功執行,要么全部失敗后回滾;
C:consistency, 一致性;數據庫總是從一個一致性狀態轉換為另一個一致性狀態;
I:Isolation,隔離性;一個事務所做出的操作在提交之前,是不能為其它所見;隔離有多種隔離級別;
D:durability: 持久性;一旦事務提交,其所做的修改會永久保存于數據庫中;
事務:
啟動事務:START TRANSACTION
結束事務:
(1) COMMIT:提交
(2) ROLLBACK: 回滾
注意:只有事務型存儲引擎方能支持此類操作;
建議:顯式請求和提交事務,而不要使用“自動提交”功能;
autocommit={1|0}
事務支持savepoint
SAVEPOINT identifier
ROLLBACK [WORK] TO [SAVEPOINT] identifier
RELEASE SAVEPOINT identifier
事務隔離級別:
READ UNCOMMITTED (讀未提交)【臟讀、不可重復讀、幻讀】
READ COMMITTED (讀提交)【不可重復讀、幻讀】
REPEATABLE READ (可重讀)【幻讀】【默認[InnoDB]MySQL存儲引擎使用的隔離級別"可重讀"】
SERIALIZABLE (可串行化)【加鎖讀】
可能存在問題:
臟讀;
不可重復讀;
幻讀;
加鎖讀;MySQL用戶和權限管理:
權限類別:
庫級別
表級別
字段級別
管理類
程序類
管理類:
CREATE TEMPORARY TABLES
CREATE USER
FILE
SUPER
SHOW DATABASES
RELOAD
SHUTDOWN
REPLICATION SLAVE
REPLICATION CLIENT
LOCK TABLES
PROCESS
程序類:
FUNCTION
PROCEDURE
TRIGGER
CREATE, ALTER, DROP, EXCUTE
庫和表級別:TABLE or DATABASE
ALTER
CREATE
CREATE VIEW
DROP
INDEX
SHOW VIEW
GRANT OPTION:能夠把自己獲得的權限贈經其他用戶一個副本;
數據操作:
SELECT
INSERT
DELETE
UPDATE
字段級別:
SELECT(col1,col2,...)
UPDATE(col1,col2,...)
INSERT(col1,col2,...)
所有有限:ALL PRIVILEGES, ALL
元數據數據庫:mysql
授權表:
db, host, user
columns_priv, tables_priv, procs_priv, proxies_priv
用戶賬號:
'USERNAME'@'HOST':
@'HOST':
主機名;
IP地址或Network;
通配符:
%, _: 172.16.%.%
創建用戶:CREATE USER
CREATE USER 'USERNAME'@'HOST' [IDENTIFIED BY 'password'];
查看用戶獲得的授權:SHOW GRANTS FOR
SHOW GRANTS FOR 'USERNAME'@'HOST'
用戶重命名:RENAME USER
RENAME USER old_user_name TO new_user_name
刪除用戶:DROP USER 'USERNAME'@'HOST'
修改密碼:
(1) SET PASSWORD FOR
(2) UPDATE mysql.user SET password=PASSWORD('your_password') WHERE clause;
(3) mysqladmin password
mysqladmin [OPTIONS] command command....
-u, -h, -p
忘記管理員密碼的解決辦法:
(1) 啟動mysqld進程時,為其使用:--skip-grant-tables --skip-networking
(2) 使用UPDATE命令修改管理員密碼
(3) 關閉mysqld進程,移除上述兩個選項,重啟mysqld;
授權:GRANT
GRANT priv_type[,...] ON [{table|function|procedure}] db.{table|routine} TO 'USERNAME'@'HOST' [IDENTIFIED BY 'password']
[REQUIRE SSL] [WITH with_option]
with_option:
GRANT OPTION
| MAX_QUERIES_PER_HOUR count
| MAX_UPDATES_PER_HOUR count
| MAX_CONNECTIONS_PER_HOUR count
| MAX_USER_CONNECTIONS count
取消授權:REVOKE
REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level FROM user [, user] ... InnoDB:
事務:事務日志
外鍵:
MVCC:
聚簇索引:
聚簇索引之外的其它索引,通常稱為輔助索引
行級鎖:間隙鎖
支持輔助索引
支持自適應hash索引
支持熱備份
MyISAM:
全文索引
壓縮:用于實現數據倉庫,能節約存儲空間并提升性能
空間索引
表級鎖
延遲更新索引
不支持事務、外鍵和行級鎖
崩潰后無法安全恢復數據
適用場景:只讀數據、較小的表、能夠容忍崩潰后的修改操作和數據丟失
ARCHIVE:
僅支持INSERT和SELECT,支持很好壓縮功能;
適用于存儲日志信息,或其它按時間序列實現的數據采集類的應用;
不支持事務,不能很好的支持索引;
CSV:
將數據存儲為CSV格式;不支持索引;僅適用于數據交換場景;
BLACKHOLE:
沒有存儲機制,任何發往此引擎的數據都會丟棄;其會記錄二進制日志,因此,常用于多級復制架構中作中轉服務器;
MEMORY:
保存數據在內存中,內存表;常用于保存中間數據,如周期性的聚合數據等;也用于實現臨時表
支持hash索引,使用表級鎖,不支持BLOB和TEXT數據類型
MRG_MYISAM:是MYISAM的一個變種,能夠將多個MyISAM表合并成一個虛表;
NDB:是MySQL CLUSTER中專用的存儲引擎
第三方的存儲引擎:
OLTP類:
XtraDB: 增強的InnoDB,由Percona提供;
編譯安裝時,下載XtraDB的源碼替換MySQL存儲引擎中的InnoDB的源碼
PBXT: MariaDB自帶此存儲引擎
支持引擎級別的復制、外鍵約束,對SSD磁盤提供適當支持;
支持事務、MVCC
TokuDB: 使用Fractal Trees索引,適用存儲大數據,擁有很好的壓縮比;已經被引入MariaDB;
列式存儲引擎:
Infobright: 目前較有名的列式引擎,適用于海量數據存儲場景,如PB級別,專為數據分析和數據倉庫設計;
InfiniDB
MonetDB
LucidDB
開源社區存儲引擎:
Aria:前身為Maria,可理解為增強版的MyISAM(支持崩潰后安全恢復,支持數據緩存)
Groona:全文索引引擎,Mroonga是基于Groona的二次開發版
OQGraph: 由Open Query研發,支持圖結構的存儲引擎
SphinxSE: 為Sphinx全文搜索服務器提供了SQL接口
Spider: 能數據切分成不同分片,比較高效透明地實現了分片(shared),并支持在分片上支持并行查詢;MySQL中定義數據字段的類型對你數據庫的優化是非常重要的。MySQL支持多種類型,大致可以分為字符型、數值型、日期時間型、內建類型。通常也可分為三類:數值、日期/時間和字符串(字符)類型。
字符型:
CHAR, BINARY:定長數據類型;【CHAR不區分字符大小寫,BINARY區分字符大小寫】
VARCHAR, VARBINARY:變長數據類型;需要結束符;
TEXT:TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT
BLOB: TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB
ENUM, SETENUM 類型因為只允許在集合中取得一個值,有點類似于單選項。SET 類型與 ENUM 類型相似但不相同。SET 類型可以從預定義的集合中取得任意數量的值。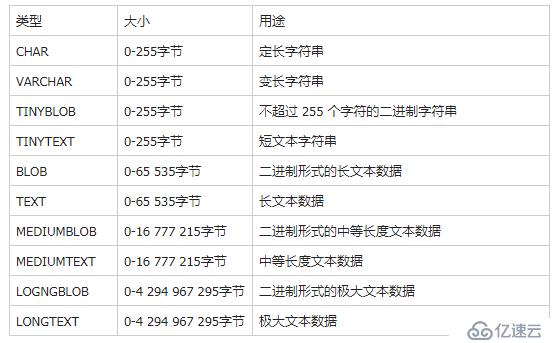
數值型:
精確數值型:
整型:TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT
十進制型:DECIMAL 【在金融領域中通常用的是十近制】
近似數值型
浮點型:
FLOAT
DOUBLE
BIT 【一般不建議使用】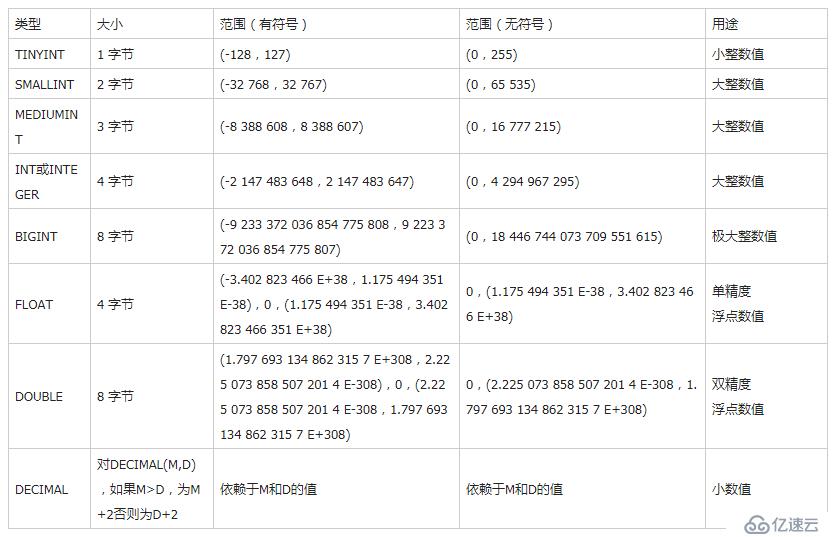
日期時間型:
DATE
TIME
DATETIME
TIMESTAMP
YEAR(2), YEAR(4)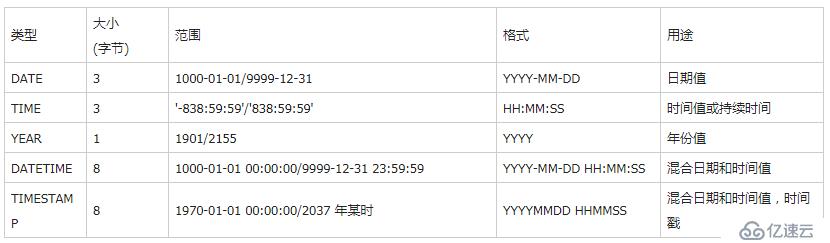
字符類型修飾符:
NOT NULL: 非空約束;
NULL:
DEFAULT 'STRING': 指明默認值;
CHARACTER SET '':使用的字符集;
COLLATION:使用的排序規則
整型數據修飾型:
NOT NULL
NULL
DEFAULT NUMBER
AUTO_INCREMENT:
UNSIGNED
PRIMARY KEY|UNIQUE KEY
NOT NULL
mysql> SELECT LAST_INSERT_ID();
日期時間型修飾符:
NOT NULL
NULL
DEFAULT
內建類型SET和ENUM的修飾符:
NOT NULL
NULL
DEFAULT常用SQL MODE有:TRADITIONAL, STRICT_TRANS_TABLES, or STRICT_ALL_TABLES。SQL_MODE可能是比較容易讓開發人員和DBA忽略的一個變量,默認為空。SQL_MODE的設置是比較有風險的一種設置,因為在這種設置下可以允許一些非法操作,比如可以將NULL插入NOT NULL的字段中,也可以插入一些非法日期,如“2019-12-33”。因此在生產環境中強烈建議開發人員將這個值設為嚴格模式,這樣有些問題可以在數據庫的設計和開發階段就能發現,而如果在生產環境下運行數據庫后發現這類問題,那么修改的代價將變得十分巨大。


sql_mode常用值如下:
ONLY_FULL_GROUP_BY:
對于GROUP BY聚合操作,如果在SELECT中的列,沒有在GROUP BY中出現,那么這個SQL是不合法的,因為列不在GROUP BY從句中
NO_AUTO_VALUE_ON_ZERO:
該值影響自增長列的插入。默認設置下,插入0或NULL代表生成下一個自增長值。如果用戶 希望插入的值為0,而該列又是自增長的,那么這個選項就有用了。
STRICT_TRANS_TABLES:
在該模式下,如果一個值不能插入到一個事務表中,則中斷當前的操作,對非事務表不做限制
NO_ZERO_IN_DATE:
在嚴格模式下,不允許日期和月份為零
NO_ZERO_DATE:
設置該值,mysql數據庫不允許插入零日期,插入零日期會拋出錯誤而不是警告。
ERROR_FOR_DIVISION_BY_ZERO:
在INSERT或UPDATE過程中,如果數據被零除,則產生錯誤而非警告。如 果未給出該模式,那么數據被零除時MySQL返回NULL
NO_AUTO_CREATE_USER:
禁止GRANT創建密碼為空的用戶
NO_ENGINE_SUBSTITUTION:
如果需要的存儲引擎被禁用或未編譯,那么拋出錯誤。不設置此值時,用默認的存儲引擎替代,并拋出一個異常
PIPES_AS_CONCAT:
將"||"視為字符串的連接操作符而非或運算符,這和Oracle數據庫是一樣的,也和字符串的拼接函數Concat相類似
ANSI_QUOTES:
啟用ANSI_QUOTES后,不能用雙引號來引用字符串,因為它被解釋為識別符
ORACLE的sql_mode設置等同:PIPES_AS_CONCAT, ANSI_QUOTES, IGNORE_SPACE, NO_KEY_OPTIONS, NO_TABLE_OPTIONS, NO_FIELD_OPTIONS, NO_AUTO_CREATE_USER.創建一個數據庫
使用 create database 語句可完成對數據庫的創建, 創建命令的格式如下:
create database 數據庫名 [其他選項];創建數據庫表
使用 create table 語句可完成對表的創建, create table 的常見形式:
create table 表名稱(列聲明);表中插入數據
insert 語句可以用來將一行或多行數據插到數據庫表中, 使用的一般形式如下:
insert [into] 表名 [(列名1, 列名2, 列名3, ...)] values (值1, 值2, 值3, ...);查詢表中的數據
select 語句常用來根據一定的查詢規則到數據庫中獲取數據, 其基本的用法為:
select 列名稱 from 表名稱 [查詢條件];按特定條件查詢:where 關鍵詞用于指定查詢條件, 用法形式為: select 列名稱 from 表名稱 where 條件;
更新表中的數據
update 語句可用來修改表中的數據, 基本的使用形式為:
update 表名稱 set 列名稱=新值 where 更新條件;刪除表中的數據
delete 語句用于刪除表中的數據, 基本用法為:
delete from 表名稱 where 刪除條件;創建后表的修改
添加列
基本形式: alter table 表名 add 列名 列數據類型 [after 插入位置];修改列
基本形式: alter table 表名 change 列名稱 列新名稱 新數據類型;刪除列
基本形式: alter table 表名 drop 列名稱;重命名表
基本形式: alter table 表名 rename 新表名;刪除整張表
基本形式: drop table 表名;刪除整個數據庫
基本形式: drop database 數據庫名;SELECT語句的執行流程:
FROM Clause --> WHERE Clause --> GROUP BY --> HAVING Clause --> ORDER BY --> SELECT --> LIMIT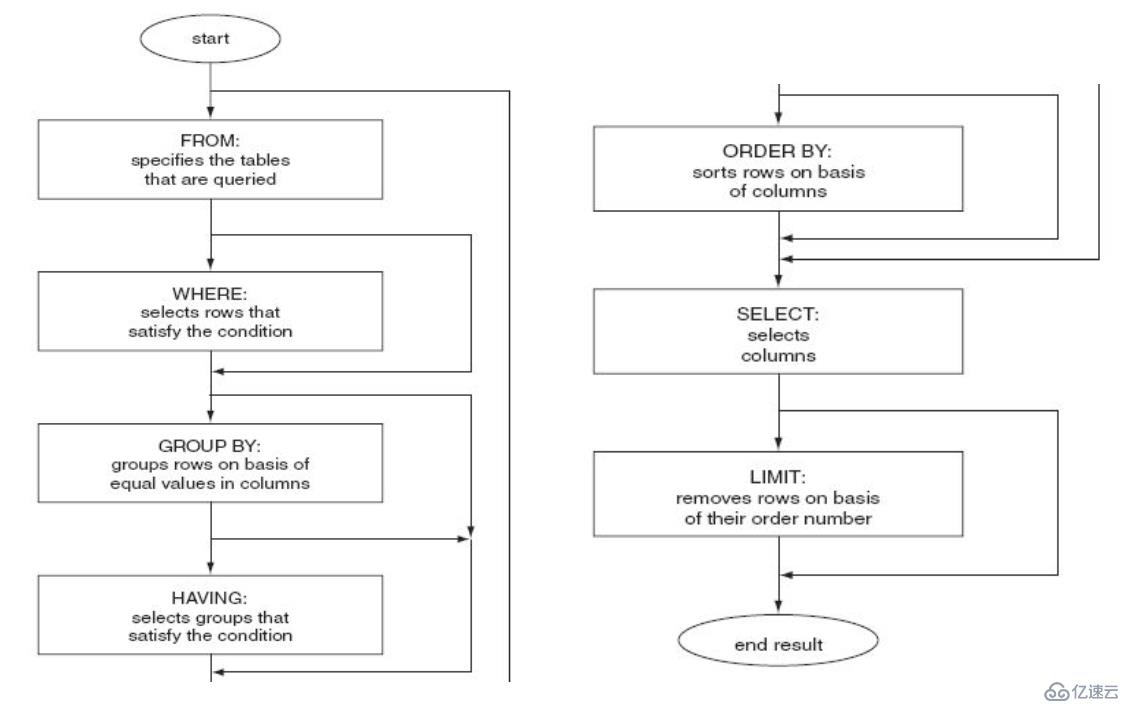
單表查詢:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[SQL_CACHE | SQL_NO_CACHE]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[FOR UPDATE | LOCK IN SHARE MODE]
DISTINCT: 數據去重;
SQL_CACHE: 顯式指定存儲查詢結果于緩存之中;
SQL_NO_CACHE: 顯式查詢結果不予緩存;
query_cache_type的值為'ON'時,查詢緩存功能打開;
SELECT的結果符合緩存條件即會緩存,否則,不予緩存;
顯式指定SQL_NO_CACHE,不予緩存;
query_cache_type的值為'DEMAND'時,查詢緩存功能按需進行;
顯式指定SQL_CACHE的SELECT語句才會緩存;其它均不予緩存;
字段顯示可以使用別名:
col1 AS alias1, col2 AS alias2, ...
WHERE子句:指明過濾條件以實現“選擇”的功能:
過濾條件:布爾型表達式;
算術操作符:+, -, *, /, %
比較操作符:=, !=, <>, <=>, >, >=, <, <=
BETWEEN min_num AND max_num
IN (element1, element2, ...)
IS NULL
IS NOT NULL
LIKE:
%: 任意長度的任意字符;
_:任意單個字符;
RLIKE:
REGEXP:匹配字符串可用正則表達式書寫模式;
邏輯操作符:
NOT
AND
OR
XOR
GROUP:根據指定的條件把查詢結果進行“分組”以用于做“聚合”運算:
avg(), max(), min(), count(), sum()
HAVING: 對分組聚合運算后的結果指定過濾條件;
ORDER BY: 根據指定的字段對查詢結果進行排序;
升序:ASC
降序:DESC
LIMIT [[offset,]row_count]:對查詢的結果進行輸出行數數量限制;
對查詢結果中的數據請求施加“鎖”:
FOR UPDATE: 寫鎖,排他鎖;
LOCK IN SHARE MODE: 讀鎖,共享鎖多表查詢:
交叉連接:笛卡爾乘積;
內連接:
等值連接:讓表之間的字段以“等值”建立連接關系;
不等值連接
自然連接
自連接
外連接:
左外連接:
FROM tb1 LEFT JOIN tb2 ON tb1.col=tb2.col
右外連接
FROM tb1 RIGHT JOIN tb2 ON tb1.col=tb2.col
子查詢:在查詢語句嵌套著查詢語句
基于某語句的查詢結果再次進行的查詢
用在WHERE子句中的子查詢:
(1) 用于比較表達式中的子查詢;子查詢僅能返回單個值;
SELECT Name,Age FROM students WHERE Age>(SELECT avg(Age) FROM students);
(2) 用于IN中的子查詢:子查詢應該單鍵查詢并返回一個或多個值從構成列表;
SELECT Name,Age FROM students WHERE Age IN (SELECT Age FROM teachers);
(3) 用于EXISTS;
用于FROM子句中的子查詢;
使用格式:SELECT tb_alias.col1,... FROM (SELECT clause) AS tb_alias WHERE Clause;
示例:
SELECT s.aage,s.ClassID FROM (SELECT avg(Age) AS aage,ClassID FROM students WHERE ClassID IS NOT NULL GROUP BY ClassID) AS s WHERE s.aage>30;數據庫設計盡量遵循第三范式(3NF)的要求。即某個表只包括其本身基本的屬性,當不是它們本身所具有的屬性時需進行分解。表之間的關系通過外鍵相連接。它具有以下特點:有一組表專門存放通過鍵連接起來的關聯數據。
對于因效率等原因,無法遵循第三范式的,應該在設計文檔中明示原因,并說明如何保持數據的一致性。
1 命名規范
(1) 數據庫名、表名、字段名必須使用小寫字母,并采用下劃線”_”分割。
(2) 數據庫名、表名、字段名禁止超過32個字符,須見名知意,建議使用名詞不是動詞。
(3) 數據庫名、表名、字段名禁止使用MySQL保留字。
(4) 臨時庫名、表名必須以tmp為前綴,并以日期為后綴。
(5) 備份庫名、表名必須以bak為前綴,并以日期為后綴。
2 基礎規范
(1) 使用INNODB存儲引擎
(2) 表字符集使用UTF8
(3) 所有表都需要添加注釋
(4) 單表數據量建議控制在5000W以內
(5) 數據庫表建議不存儲圖、文件等大數據
(6) 禁止在線上做數據庫壓力測試操作
(7) 所有字段須定義為not null,根據業務可指定default值
3 庫表設計
(1) 庫名格式為 組織機構_xxx[_xxx],比如以toon基礎為例,其中“toon_”為前綴,xxx為實際數據庫名稱,使用各模塊的項目名稱字段設計。
(2) 表名中含有單詞全部采用單數形式,多個單詞之間使用”_”分割
(3) 同業務模塊表,建議在表名前增加模塊縮寫。
示例:客戶表:cust_customer
客戶聯系方式:cust_contact
(4) 分表命名規則:原表明_數字,示例:cust_customer _01
(5) 所有表添加注釋。
(6) 所有表必須要顯式指定主鍵。
(7) 單表控制字段數量,30個字段的上限。
(8) 單表數據量建議控制在2000W~5000W以內
簡單字段類型建議 5000W以內,比如int,tinyint,bigint等
復雜字段類型建議 2000W 以內,比如varchar(n>2048),text等
(9) 關聯表命名規則:表a_表b,如果存在模塊縮寫,根據實際的業務需要保留一個模塊縮寫
示例:
房客關系表: prt_property_customer
4 字段設計
類型 字節 有/無符號 最小值 最大值
TINYINT 1 有 -128 127
無 0 255
SMALLINT 2 有 -32768 32767
無 0 65535
MEDIUMINT 3 有 -8388608 8388607
無 0 16777215
INT 4 有 -2147483648 2147483647
無 0 4294967295
BIGINT 8 有 -9223372036854775808 9223372036854775807
無 0 18446744073709551615
(1) 越小越好的原則,選擇合適的數據類型,數據類型所占用字節數越小越好;數值類型取值參考下表:
如主鍵取值上限不超過42億,建議不用BIGINT
(2) 越簡單越好的原則,字段能用數值型的不要用字符型。
(3) 盡量避免使用 text/blob數據類型, 若確實需要,根據訪問, 更新頻次, 看是否有必要從 主表拆分出來。
(4) 使用TINYINT代替ENUM、SET。
(5) 字符串類型,比較小并且固定比如MD5值等選擇CHAR,否則選擇VARCHAR。
使用盡可能小的VARCHAR字段,VARCHAR(N)中的N表示的是字符數而非字節數,一個漢字占用三個字節,一個字母占用一個字節。
(6) 字段須指定NOT NULL。
(7) 常用字段類型推薦
id主鍵:bigint或int,視數據增長范圍選擇,自增;
phone:varchar(15);
email:varchar(254);
郵編:varchar(11);
枚舉型數據:tinyint;
url:varchar(2083);
img:varchar(2083);
IP:varchar(45)或轉整型存儲;
Money:DECIMAL(19,4);
Longitude:DECIMAL(9,6);
Latitude:DECIMAL(8,6)。
5 索引設計
(1) 非唯一索引必須按照“idx_字段名稱_字段名稱[_字段名]”進行命名。
(2) 唯一索引必須按照“uniq_字段名稱_字段名稱[_字段名]”進行命名。
(3) 控制索引數量,單表索引數量不超過5個,單個索引字段不超過5個。
(4) 索引盡量健在區分度性高的列上,不在低區分度列上建立索引,例如性別。
(5) 不要在頻繁更新的列上建索引,不在索引列進行數學運算和函數運算。
(6) 合理創建聯合索引(避免冗余),(a,b,c) 相當于 (a) 、(a,b) 、(a,b,c)
(7) 重要的SQL必須被索引,UPDATE、DELETE語句的WHERE條件列,ORDER BY、GROUP BY、DISTINCT的字段,多表JOIN的字段
(8) 不使用%前綴的查詢,如like “%ab”;不使用負向查詢,如not in/like(推薦考慮用全文檢索sphinx)。
6 SQL設計
(1) sql語句盡可能簡單,大的sql根據業務拆分成小的sql語句(充分利用QUERY CACHE和充分利用多核CPU)。
(2) limit分頁注意效率。limit越大,效率越低。可以改寫limit,比如例子改寫:select id from t limit 10000, 10; => select id from t where id > 10000 limit10。
(3) 減少與數據庫的交互次數,盡量使用批量sql語句。
(4) 注意使用性能分析的工具
Sql explain / showprofile / mysqlsla
(5) 建議SQL關鍵字全部是大寫,每個詞只允許有一個空格
(6) SQL語句不可以出現類型隱式轉換,比如 select id from 表 where id='1'
(7) IN條件里面的數據數量要少,使用exist代替in,exist在一些場景查詢會比in快
在兩個都可以使用的情況下,建議通過執行計劃來做取舍。
(8) 禁止在數據庫中跑大查詢
(9) 能不用NOT IN就不用NOT IN。
(10) 在SQL語句中,不建議使用模糊前綴匹配操作,比如like
(11) 關于分頁查詢:程序里建議合理使用分頁來提高效率limit,offset較大要配合子查詢使用
(12) 使用預編譯語句,只傳參數,比傳遞SQL語句更高效;一次解析,多次使用;降低SQL注入概率
7 行為規范
(1) 數據庫設計須有DBA參與,表結構變更必須通知DBA;
(2) 批量導入、導出或者批量更新數據,必須DBA進行審核,執行;
(3) 建議對同一個表的多次alter操作合并為一次操作;
(4) 不要在MySQL數據庫中存放業務邏輯;
(5) 建議禁止存儲過程、函數、觸發器的使用。1、刪除所有匿名用戶
mysql> DROP USER ''@'localhost';
mysql> DROP USER ''@'www.xxx.com';
用戶帳號由兩部分組成:username@host
host還可以使用通配符:
%: 任意長度的任意字符
_: 匹配任意單個字符
2、給所有的root用戶設定密碼:
第一種方式:
mysql> SET PASSWORD FOR username@host = PASSWORD('your_passwrod');
第二種方式:
mysql> UPDATE user SET password = PASSWORD('your_password') WHERE user = 'root';
mysql> FLUSH PRIVILEGES;
第三種方式:
# mysqladmin -uUserName -hHost password 'new_password' -p
# mysqladmin -uUserName -hHost -p flush-privileges創建新用戶# 創建用戶和設置密碼
CREATE USER '新用戶'@'localhost' IDENTIFIED BY '新密碼';
對用戶授權
GRANT ALL PRIVILEGES ON . TO '新用戶'@‘localhost' WITH GRANT OPTION;
連入MySQL服務器
mysql client <--mysql protocol--> mysqld
mysqld接收連接請求:
本地通信:客戶端與服務器端位于同一主機,而且還要基于127.0.0.1(localhost)地址或lo接口進行通信;
Linux OR Unix: Unix Sock, /tmp/mysql.sock, /var/lib/mysql/mysql.sock
Windows: memory, pipe
遠程通信:客戶端與服務器位于不同的主機,或在同一主機便使用非回環地址通信
TCP socket
客戶端工具:mysql, mysqladmin, mysqldump, mysqlcheck
[client]
通行的選項:
-u, --user=
-h, --host=
-p, --password=
--protocol={tcp|socket|memory|pipe}
--port=
--socket= 例如:/tmp/mysql.sock
【注意格式-u和-p后沒有空格是連在一起的,如果密碼想要不顯示可以這樣:mysql -uroot -p 回車輸入密碼】
mysql監聽的端口: 3306/tcp
非客戶端類的管理工具:myisamchk, myisampack
mysql工作模式:
交互式模式
mysql>
腳本模式
mysql < /path/to/mysql_script.sql
mysql交互式模式:
客戶端命令
mysql> help
mysql> \?
\c
\g
\G
\q
\!
\s
\. /path/to/mysql_script.sql
服務器端命令:需要命令結束符,默認為分號(;)
mysql> help contents
mysql> help Keryword
mysql命令行選項:
--compress
--database=, -D
-H, --html:輸出結果為html格式的文檔
-X, --xml: 輸出格式為xml
--sate-updates: 拒絕使用無where子句的update或delete命令;
mysql命令提示符:
mysql> 等待輸入命令
->
'>
">
`>
/*>
mysql的快捷鍵:
Ctrl + w: 刪除光標之前的單詞
Ctrl + u: 刪除光標之前至命令行首的所有內容
Ctrl + y: 粘貼使用Ctrl+w或Ctrl+u刪除的內容
Ctrl + a: 移動光標至行首
Ctrl + e: 移動光標至行尾MySQL優化需要在三個不同層次上協調進行:MySQL級別、OS級別和硬件級別。MySQL級別的優化包括表優化、查詢優化和MySQL服務器配置優化等,而MySQL的各種數據結構又最終作用于OS直至硬件設備,因此還需要了解每種結構對OS級別的資源的需要并最終導致的CPU和I/O操作等,并在此基礎上將CPU及I/O操作需要盡量降低以提升其效率。
數據庫層面的優化著眼點:
1、是否正確設定了表結構的相關屬性,尤其是每個字段的字段類型是否為最佳。
2、是否為高效進行查詢創建了合適的索引。
3、是否為每張表選用了合適的存儲引擎,并有效利用了選用的存儲引擎本身的優勢和特性。
4、是否基于存儲引擎為表選用了合適的行格式(row format)。
5、是否使用了合適的鎖策略,如在并發操作場景中使用共享鎖,而對較高優先級的需求使用獨占鎖等。
6、是否為InnoDB的緩沖池、MyISAM的鍵緩存以及MySQL查詢緩存設定了合適大小的內存空間,以便能夠存儲頻繁訪問的數據且又不會引起頁面換出。1、是否為實際的工作負載選定了合適的CPU,如對于CPU密集型的應用場景要使用更快速度的CPU甚至更多數量的CPU,為有著更多查詢的場景使用更多的CPU等。因為MySQL尚不能高效的運行于多CPU,并且其對CPU數量的支持也有著限制。一般來說,較新的版本可以支持16至24顆CPU甚至更多。
2、是否有著合適大小的物理內存,并通過合理的配置平衡內存和磁盤資源,降低甚至避免磁盤I/O。緩存可以有效地延遲寫入、優化寫入,但并能消除寫入,并綜合考慮存儲空間的可擴展性等,為業務選擇合理的外部存儲設備也是非常重要的工作。
3、是否選擇了合適的網絡設備并正確地配置了網絡對整體系統系統也有著重大影響。延遲和帶寬是網絡連接的限制性因素,而常見的網絡問題如丟包等,即是很小的丟包率也會贊成性能的顯著下降。而更重要的還有按需調整系統中關于網絡方面的設置,以高效處理大量的連接和小查詢。
4、是否基于操作系統選擇了適用的文件系統。同時,關閉文件系統的某些特性如訪問時間和預讀行為,并選擇合理的磁盤調度器通常都會給性能提升帶來幫助。
5、MySQL為響應每個用戶連接使用一個單獨的線程,再加內部使用的線程、特殊目的線程以及其它任何由存儲引擎創建的線程等,MySQL需要對這些大量線程進行有效管理。Linux系統上的NPTL線程庫更為輕量級也更有效率。MySQL 5.5引入了線程池插件,但其效用尚不明朗。跟阿里云數據庫大佬電話溝通 and Google解決方案 and 問群里大佬,總結如下(都是精華):
1.數據庫設計和表創建時就要考慮性能
2.sql的編寫需要注意優化
3.分區 【MySQL在5.1版引入的分區是一種簡單的水平拆分,用戶需要在建表的時候加上分區參數,對應用是透明的無需修改代碼】
4.分表 【分表就是把一張大表,按照如上過程都優化了,還是查詢卡死,那就把這個表分成多張表,把一次查詢分成多次查詢,然后把結果組合返回給用戶。】
5.分庫 【把一個數據庫分成多個,建議做個讀寫分離就行了,真正的做分庫也會帶來大量的開發成本,得不償失!不推薦使用。】
第一優化sql和索引;
第二加緩存,memcached,redis;
第三以上都做了后,還是慢,就做主從復制或主主復制,讀寫分離,可以在應用層做,效率高,也可以用三方工具,第三方工具推薦360的atlas,其它的要么效率不高,要么沒人維護;
第四如果以上都做了還是慢,不要想著去做切分,mysql自帶分區表,先試試這個,對你的應用是透明的,無需更改代碼,但是sql語句是需要針對分區表做優化的,sql條件中要帶上分區條件的列,從而使查詢定位到少量的分區上,否則就會掃描全部分區;
第五如果以上都做了,那就先做垂直拆分,其實就是根據你模塊的耦合度,將一個大的系統分為多個小的系統,也就是分布式系統;
第六才是水平切分,針對數據量大的表,這一步最麻煩,最能考驗技術水平,要選擇一個合理的sharding key,為了有好的查詢效率,表結構也要改動,做一定的冗余,應用也要改,sql中盡量帶sharding key,將數據定位到限定的表上去查,而不是掃描全部的表;?
優化相關參數:
查詢mysql跑在哪顆cpu上一個進程只能跑在一個CPU上
查詢緩存流程圖: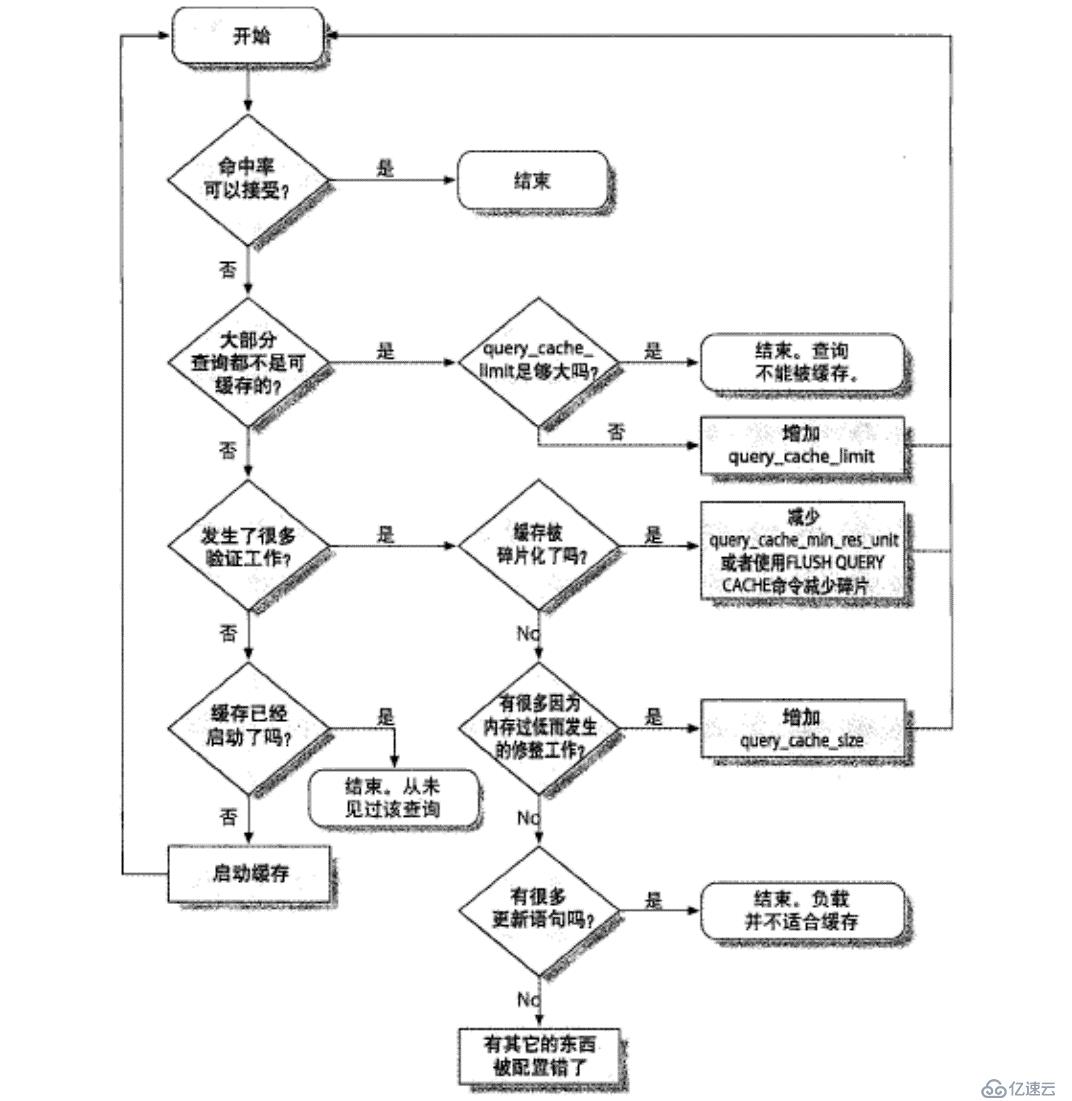
開啟緩存
mysql > show variables like '%query%'; 查詢緩存
set global query_cache_size =16777216; 改查詢緩存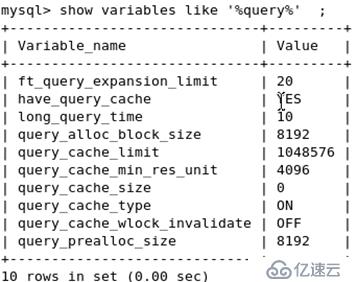
慢速查詢日志
打開表動作緩存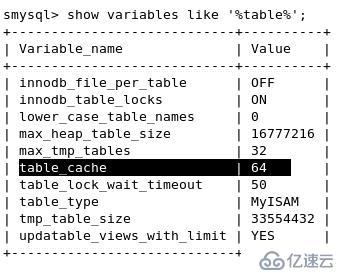
連接數調整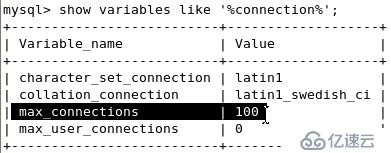
緩存innidb表空間 【默認8M 理論越大越好 設置整體內存80%】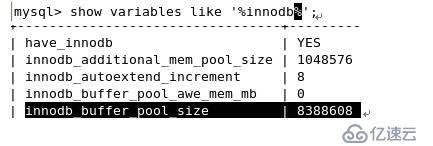
連接超時時間 【當網絡通信情況不好或后端機負載大時,這個數值往大調,不然會造成很多前端機連不上】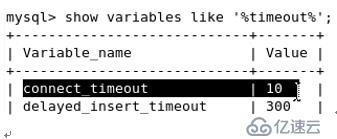
查看innodb事務日志方式 【這個值對IO影響特別大,決定innodb事務日志往磁盤寫的方式數值只有0 1 2 (建議改成2)】
查詢相關的狀態變量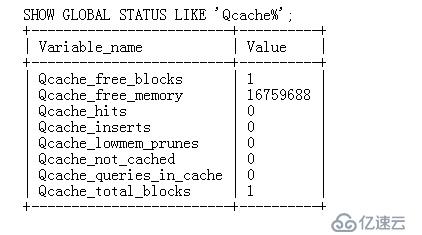
緩存命中率的評估:Qcache_hits/(Qcache_hits+Com_select)
數據分析離不開SQL工具,SQL的使用能力是數據分析的一項基礎能力,這就是學習SQL最核心的原因,只要你有從事數據分析的想法,就必須踏踏實實去學習。《大數據時代》是我看的第一本關于網絡趨勢的書,它從宏觀層面把握這個時代,從“大數據”這一時代特征著手,講述了大數據對我們生活,工作,乃至思維的變革。具體包括:大數據的概念,它的價值,它帶來的轉變及轉變的方式,它的負面影響,這個時代的一系列規范等。在今天大數據盛行的時代,NoSQL:redis, mongodb, hbase, NewSQL:TiDB、關系型數據庫MySQL都在每個業務層次發揮著重要的作用。不管是大數據還是小數據,掌握一套數據管理系統是必要的,當下的MySQL在開源界還是比較流行的,就連一些國企也開始在去IOE,所以還是有深入學習的必要,本著以溫故而知新的目的,把MySQL相關知識循序漸進的梳理成新篇章。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





