溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Python Counting Bloom Filter怎么實現”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Python Counting Bloom Filter怎么實現”文章吧。
標準的 Bloom Filter 是一種比較簡單的數據結構,只支持插入和查找兩種操作。在所要表達的集合是靜態集合的時候,標準 Bloom Filter 可以很好地工作,但是如果要表達的集合經常變動,標準Bloom Filter的弊端就顯現出來了,因為它不支持刪除操作。這就引出來了本文要談的 Counting Bloom Filter,后文簡寫為 CBF。
BF 為什么不能刪除元素?我們可以舉一個例子來說明。
比如要刪除集合中的成員 dantezhao,那么就會先用 k 個哈希函數對其計算,因為 dantezhao 已經是集合成員,那么在位數組的對應位置一定是 1,我們如要要刪除這個成員 dantezhao,就需要把計算出來的所有位置上的 1 置為 0,即將 5 和 16 兩位置為 0 即可。
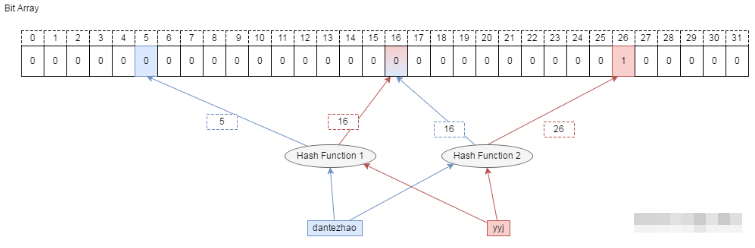
問題來了!現在,先假設 yyj 本身是屬于集合的元素,如果需要查詢 yyj 是否在集合中,通過哈希函數計算后,我們會去判斷第 16 和 第 26 位是否為 1, 這時候就得到了第 16 位為 0 的結果,即 yyj 不屬于集合。 顯然這里是誤判的。
Counting Bloom Filter 的出現,解決了上述問題,它將標準 Bloom Filter 位數組的每一位擴展為一個小的計數器(Counter),在插入元素時給對應的 k (k 為哈希函數個數)個 Counter 的值分別加 1,刪除元素時給對應的 k 個 Counter 的值分別減 1。Counting Bloom Filter 通過多占用幾倍的存儲空間的代價, 給 Bloom Filter 增加了刪除操作。基本原理是不是很簡單?看下圖就能明白它和 Bloom Filter 的區別在哪。
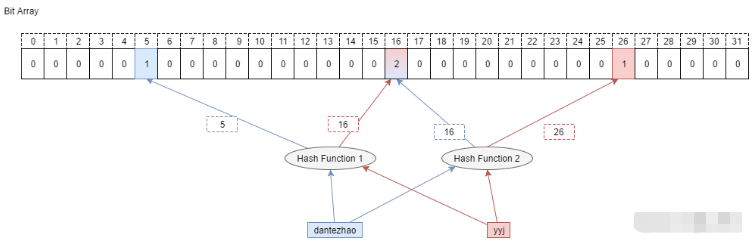
CBF 和 BF 的一個主要的不同就是 CBF 用一個 Counter 取代了 BF 中的一位,那么 Counter 到底取多大才比較合適呢?這里就要考慮到空間利用率的問題了,從使用的角度來看,當然是越大越好,因為 Counter 越大就能表示越多的信息。但是越大的 Counter 就意味著更多的資源占用,而且在很多時候會造成極大的空間浪費。
因此,我們在選擇 Counter 的時候,可以看 Counter 取值的范圍多小就可以滿足需求。
根據論文中描述,某一個 Counter 的值大于或等于 i 的概率可以通過如下公式描述,其中 n 為集合的大小,m 為 Counter 的數量,k 為 哈希函數的個數。

k 的最佳取值為 k = m/n * ln2,將其帶入公式后可得。
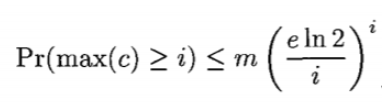
如果每個 Counter 分配 4 位,那么當 Counter 的值達到 16 時就會溢出。這個概率如下,這個值足夠小,因此對于大多數應用程序來說,4位就足夠了。

還是實現一個簡單的程序來熟悉 CBF 的原理,這里和 BF 的區別有兩個:
一個是我們沒有用 bitarray 提供的位數組,而是使用了 bytearray 提供的一個 byte數組,因此每一個 Counter 的取值范圍在 0~255。
另一個是多了一個 remove 方法來刪除集合中的元素。
代碼很簡單,只是為了理解概念,實際中使用的庫會有很大差別。
import mmh4
class CountingBloomFilter:
def __init__(self, size, hash_num):
self.size = size
self.hash_num = hash_num
self.byte_array = bytearray(size)
def add(self, s):
for seed in range(self.hash_num):
result = mmh4.hash(s, seed) % self.size
if self.bit_array[result] < 256:
self.bit_array[result] += 1
def lookup(self, s):
for seed in range(self.hash_num):
result = mmh4.hash(s, seed) % self.size
if self.bit_array[result] == 0:
return "Nope"
return "Probably"
def remove(self, s):
for seed in range(self.hash_num):
result = mmh4.hash(s, seed) % self.size
if self.bit_array[result] > 0:
self.bit_array[result] -= 1
cbf = CountingBloomFilter(500000, 7)
cbf.add("dantezhao")
cbf.add("yyj")
cbf.remove("dantezhao")
print (cbf.lookup("dantezhao"))
print (cbf.lookup("yyj"))以上就是關于“Python Counting Bloom Filter怎么實現”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





