溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Node中的進程間通信怎么實現”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Node中的進程間通信怎么實現”文章吧。
在 Linux 系統中,一切都看成文件,當進程打開現有文件時,會返回一個文件描述符。 文件描述符是操作系統為了管理已經被進程打開的文件所創建的索引,用來指向被打開的文件。 當我們的進程啟動之后,操作系統會給每一個進程分配一個 PCB 控制塊,PCB 中會有一個文件描述符表,存放當前進程所有的文件描述符,即當前進程打開的所有文件。
進程中的文件描述符是如何和系統文件對應起來的? 在內核中,系統會維護另外兩種表
打開文件表(Open file table)
i-node 表(i-node table)
文件描述符就是數組的下標,從0開始往上遞增,0/1/2 默認是我們的輸入/輸出/錯誤流的文件描述符 在 PCB 中維護的文件描述表中,可以根據文件描述符找到對應了文件指針,找到對應的打開文件表 打開文件表中維護了:文件偏移量(讀寫文件的時候會更新);對于文件的狀態標識;指向 i-node 表的指針 想要真正的操作文件,還得靠 i-node 表,能夠獲取到真實文件的相關信息
他們之間的關系
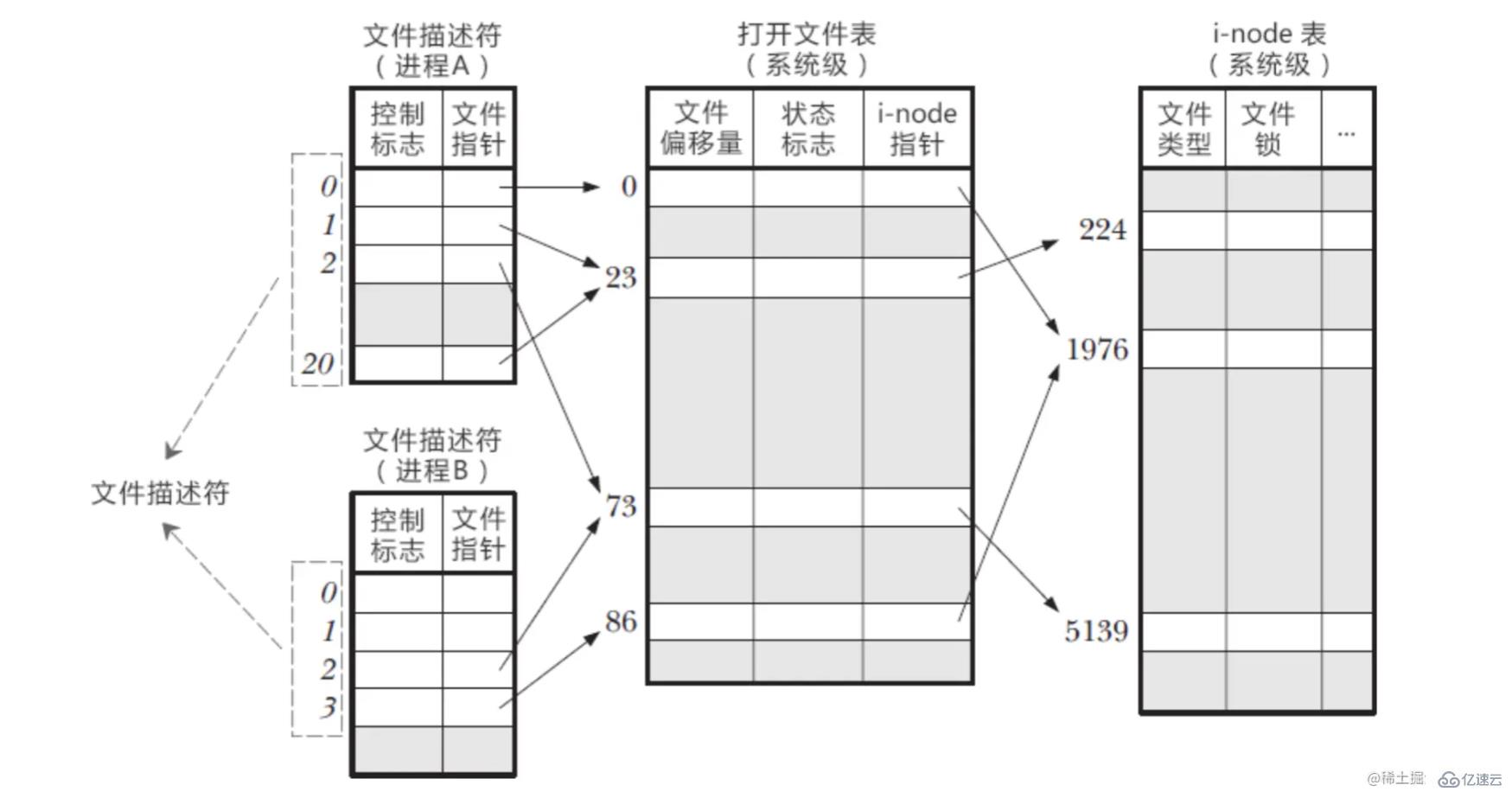
圖解
在進程 A 中,文件描述符1/20均指向了同一打開文件表項23,這可能是對同一文件多次調用了 open 函數形成的
進程 A/B 的文件描述符2都指向同一文件,這可能是調用了 fork 創建子進程,A/B 是父子關系進程
進程 A 的文件描述符0和進程 B 的文件描述符指向了不同的打開文件表項,但這些表項指向了同一個文件,這可能是 A/B 進程分別對同一文件發起了 open 調用
總結
同一進程的不同文件描述符可以指向同一個文件
不同進程可以擁有相同的文件描述符
不同進程的同一文件描述符可以指向不同的文件
不同進程的不同文件描述符可以指向同一個文件
每次讀寫進程的時候,都是從文件描述符下手,找到對應的打開文件表項,再找到對應的 i-node 表
?如何實現文件描述符重定向? 因為在文件描述符表中,能夠找到對應的文件指針,如果我們改變了文件指針,是不是后續的兩個表內容就發生了改變 例如:文件描述符1指向的顯示器,那么將文件描述符1指向 log.txt 文件,那么文件描述符 1 也就和 log.txt 對應起來了
> 是輸出重定向符號,< 是輸入重定向符號,它們是文件描述符操作符 > 和 < 通過修改文件描述符改變了文件指針的指向,來能夠實現重定向的功能
我們使用cat hello.txt時,默認會將結果輸出到顯示器上,使用 > 來重定向。cat hello.txt 1 > log.txt以輸出的方式打開文件 log.txt,并綁定到文件描述符1上

dup 函數是用來打開一個新的文件描述符,指向和 oldfd 同一個文件,共享文件偏移量和文件狀態
int main(int argc, char const *argv[])
{
int fd = open("log.txt");
int copyFd = dup(fd);
//將fd閱讀文件置于文件末尾,計算偏移量。
cout << "fd = " << fd << " 偏移量: " << lseek(fd, 0, SEEK_END) << endl;
//現在我們計算copyFd的偏移量
cout << "copyFd = " << copyFd << "偏移量:" << lseek(copyFd, 0, SEEK_CUR) << endl;
return 0;
}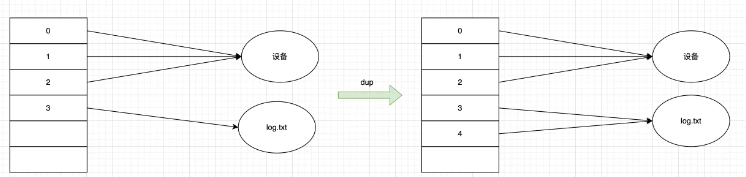
調用 dup(3) 的時候,會打開新的最小描述符,也就是4,這個4指向了3所指向的文件,操作任意一個 fd 都是修改的一個文件
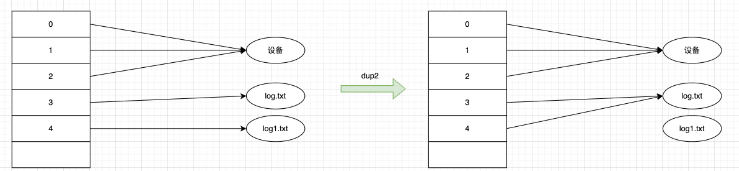
dup2 函數,把指定的 newfd 也指向 oldfd 指向的文件。執行完dup2之后,newfd 和 oldfd 同時指向同一個文件,共享文件偏移量和文件狀態
int main(int argc, char const *argv[])
{
int fd = open("log.txt");
int copyFd = dup(fd);
//將fd閱讀文件置于文件末尾,計算偏移量。
cout << "fd = " << fd << " 偏移量: " << lseek(fd, 0, SEEK_END) << endl;
//現在我們計算copyFd的偏移量
cout << "copyFd = " << copyFd << "偏移量:" << lseek(copyFd, 0, SEEK_CUR) << endl;
return 0;
}
Node 中的 IPC 通道具體實現是由 libuv 提供的。根據系統的不同實現方式不同,window 下采用命名管道實現,*nix 下采用 Domain Socket 實現。在應用層只體現為 message 事件和 send 方法。
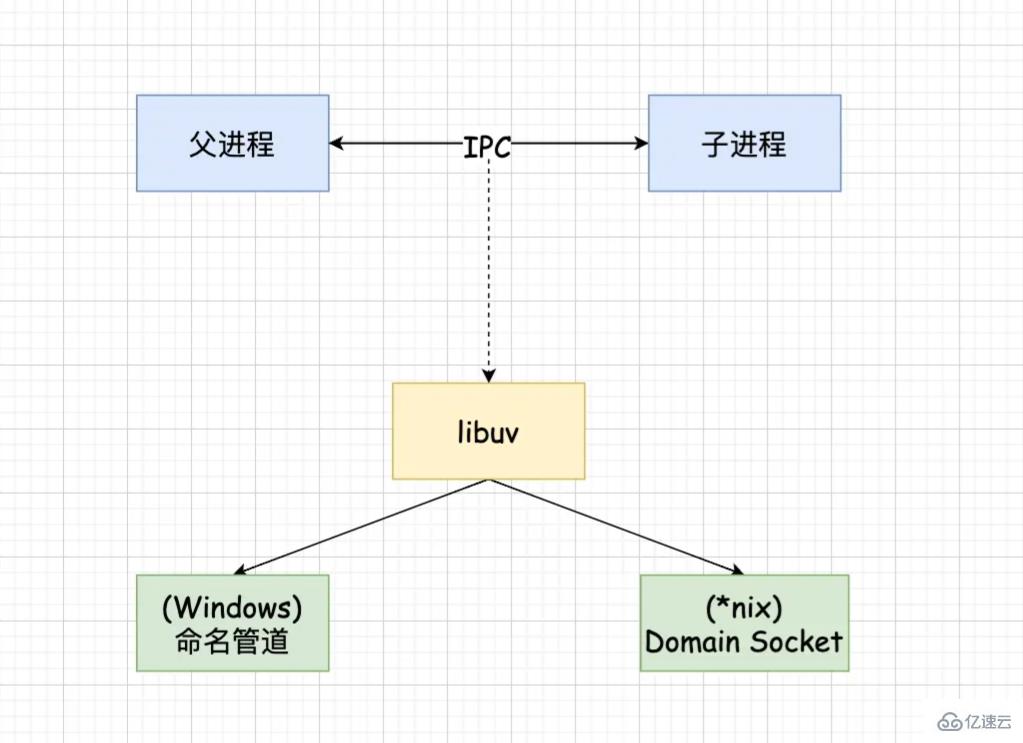
父進程在實際創建子進程之前,會創建 IPC 通道并監聽它,等到創建出真實的子進程后,通過環境變量(NODE_CHANNEL_FD)告訴子進程該 IPC 通道的文件描述符。
子進程在啟動的過程中,會根據該文件描述符去連接 IPC 通道,從而完成父子進程的連接。
建立連接之后可以自由的通信了,IPC 通道是使用命名管道或者 Domain Socket 創建的,屬于雙向通信。并且它是在系統內核中完成的進程通信
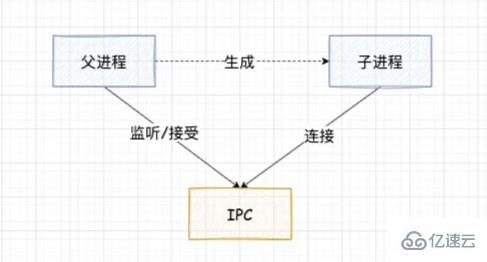
?? 只有在啟動的子進程是 Node 進程時,子進程才會根據環境變量去連接對應的 IPC 通道,對于其他類型的子進程則無法實現進程間通信,除非其他進程也按著該約定去連接這個 IPC 通道。
我們知道經典的通信方式是有 Socket,我們平時熟知的 Socket 是基于網絡協議的,用于兩個不同主機上的兩個進程通信,通信需要指定 IP/Host 等。 但如果我們同一臺主機上的兩個進程想要通信,如果使用 Socket 需要指定 IP/Host,經過網絡協議等,會顯得過于繁瑣。所以 Unix Domain Socket 誕生了。
UDS 的優勢:
綁定 socket 文件而不是綁定 IP/Host;不需要經過網絡協議,而是數據的拷貝
也支持 SOCK_STREAM(流套接字)和 SOCK_DGRAM(數據包套接字),但由于是在本機通過內核通信,不會丟包也不會出現發送包的次序和接收包的次序不一致的問題
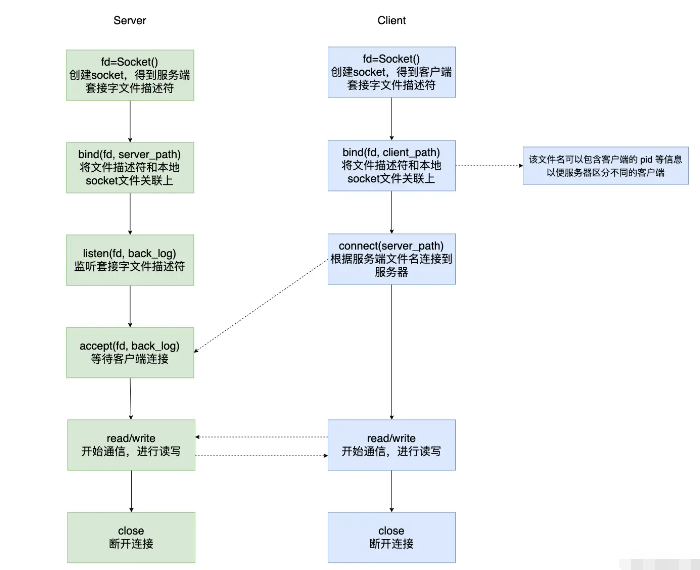
int main(int argc, char *argv[])
{
int server_fd ,ret, client_fd;
struct sockaddr_un serv, client;
socklen_t len = sizeof(client);
char buf[1024] = {0};
int recvlen;
// 創建 socket
server_fd = socket(AF_LOCAL, SOCK_STREAM, 0);
// 初始化 server 信息
serv.sun_family = AF_LOCAL;
strcpy(serv.sun_path, "server.sock");
// 綁定
ret = bind(server_fd, (struct sockaddr *)&serv, sizeof(serv));
//設置監聽,設置能夠同時和服務端連接的客戶端數量
ret = listen(server_fd, 36);
//等待客戶端連接
client_fd = accept(server_fd, (struct sockaddr *)&client, &len);
printf("=====client bind file:%s\n", client.sun_path);
while (1) {
recvlen = recv(client_fd, buf, sizeof(buf), 0);
if (recvlen == -1) {
perror("recv error");
return -1;
} else if (recvlen == 0) {
printf("client disconnet...\n");
close(client_fd);
break;
} else {
printf("recv buf %s\n", buf);
send(client_fd, buf, recvlen, 0);
}
}
close(client_fd);
close(server_fd);
return 0;
}int main(int argc, char *argv[])
{
int client_fd ,ret;
struct sockaddr_un serv, client;
socklen_t len = sizeof(client);
char buf[1024] = {0};
int recvlen;
//創建socket
client_fd = socket(AF_LOCAL, SOCK_STREAM, 0);
//給客戶端綁定一個套接字文件
client.sun_family = AF_LOCAL;
strcpy(client.sun_path, "client.sock");
ret = bind(client_fd, (struct sockaddr *)&client, sizeof(client));
//初始化server信息
serv.sun_family = AF_LOCAL;
strcpy(serv.sun_path, "server.sock");
//連接
connect(client_fd, (struct sockaddr *)&serv, sizeof(serv));
while (1) {
fgets(buf, sizeof(buf), stdin);
send(client_fd, buf, strlen(buf)+1, 0);
recv(client_fd, buf, sizeof(buf), 0);
printf("recv buf %s\n", buf);
}
close(client_fd);
return 0;
}命名管道是可以在同一臺計算機的不同進程之間,或者跨越一個網絡的不同計算機的不同進程之間的可靠的單向或者雙向的數據通信。 創建命名管道的進程被稱為管道服務端(Pipe Server),連接到這個管道的進程稱為管道客戶端(Pipe Client)。
命名管道的命名規范:\server\pipe[\path]\name
其中 server 指定一個服務器的名字,本機適用 \. 表示,\192.10.10.1 表示網絡上的服務器
\pipe 是一個不可變化的字串,用于指定該文件屬于 NPFS(Named Pipe File System)
[\path]\name 是唯一命名管道名稱的標識
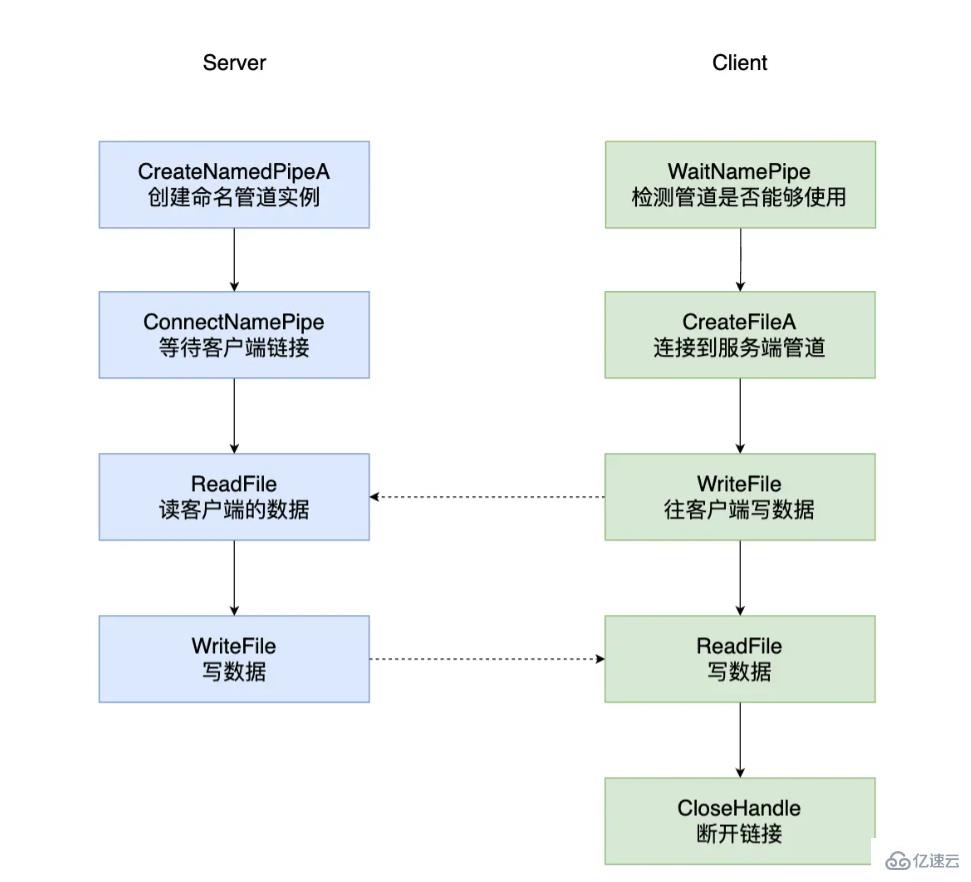
void ServerTest()
{
HANDLE serverNamePipe;
char pipeName[MAX_PATH] = {0};
char szReadBuf[MAX_BUFFER] = {0};
char szWriteBuf[MAX_BUFFER] = {0};
DWORD dwNumRead = 0;
DWORD dwNumWrite = 0;
strcpy(pipeName, "\\\\.\\pipe\\shuangxuPipeTest");
// 創建管道實例
serverNamePipe = CreateNamedPipeA(pipeName,
PIPE_ACCESS_DUPLEX|FILE_FLAG_WRITE_THROUGH,
PIPE_TYPE_BYTE|PIPE_READMODE_BYTE|PIPE_WAIT,
PIPE_UNLIMITED_INSTANCES, 0, 0, 0, NULL);
WriteLog("創建管道成功...");
// 等待客戶端連接
BOOL bRt= ConnectNamedPipe(serverNamePipe, NULL );
WriteLog( "收到客戶端的連接成功...");
// 接收數據
memset( szReadBuf, 0, MAX_BUFFER );
bRt = ReadFile(serverNamePipe, szReadBuf, MAX_BUFFER-1, &dwNumRead, NULL );
// 業務邏輯處理 (只為測試用返回原來的數據)
WriteLog( "收到客戶數據:[%s]", szReadBuf);
// 發送數據
if( !WriteFile(serverNamePipe, szWriteBuf, dwNumRead, &dwNumWrite, NULL ) )
{
WriteLog("向客戶寫入數據失敗:[%#x]", GetLastError());
return ;
}
WriteLog("寫入數據成功...");
}void ClientTest()
{
char pipeName[MAX_PATH] = {0};
HANDLE clientNamePipe;
DWORD dwRet;
char szReadBuf[MAX_BUFFER] = {0};
char szWriteBuf[MAX_BUFFER] = {0};
DWORD dwNumRead = 0;
DWORD dwNumWrite = 0;
strcpy(pipeName, "\\\\.\\pipe\\shuangxuPipeTest");
// 檢測管道是否可用
if(!WaitNamedPipeA(pipeName, 10000)){
WriteLog("管道[%s]無法打開", pipeName);
return ;
}
// 連接管道
clientNamePipe = CreateFileA(pipeName,
GENERIC_READ|GENERIC_WRITE,
0,
NULL,
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL,
NULL);
WriteLog("管道連接成功...");
scanf( "%s", szWritebuf );
// 發送數據
if( !WriteFile(clientNamePipe, szWriteBuf, strlen(szWriteBuf), &dwNumWrite, NULL)){
WriteLog("發送數據失敗,GetLastError=[%#x]", GetLastError());
return ;
}
printf("發送數據成功:%s\n", szWritebuf );
// 接收數據
if( !ReadFile(clientNamePipe, szReadBuf, MAX_BUFFER-1, &dwNumRead, NULL)){
WriteLog("接收數據失敗,GetLastError=[%#x]", GetLastError() );
return ;
}
WriteLog( "接收到服務器返回:%s", szReadBuf );
// 關閉管道
CloseHandle(clientNamePipe);
}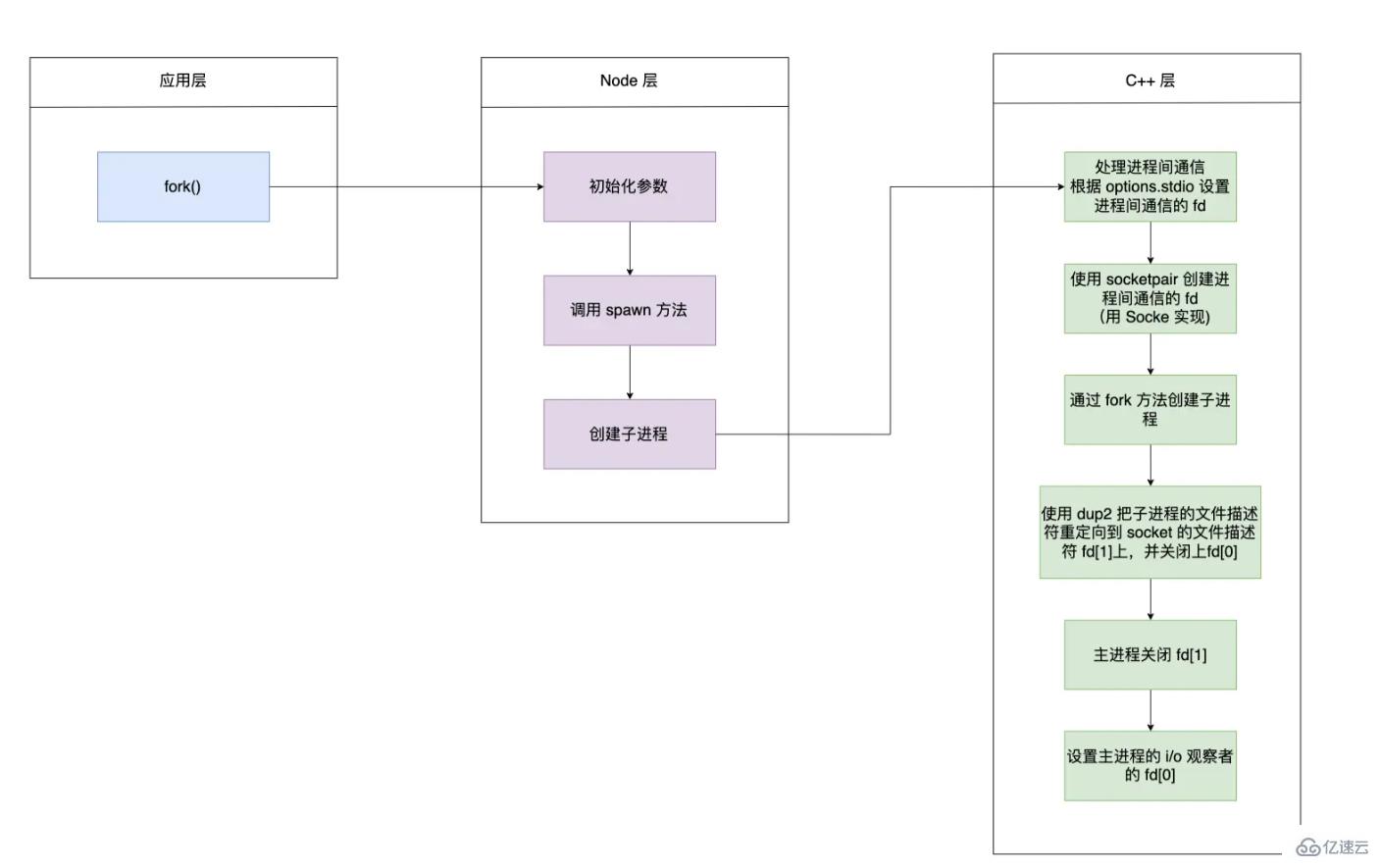
對于創建子進程、創建管道、重定向管道均是在 c++ 層實現的
int main(int argc,char *argv[]){
pid_t pid = fork();
if (pid < 0) {
// 錯誤
} else if(pid == 0) {
// 子進程
} else {
// 父進程
}
}使用 socketpair 創建管道,其創建出來的管道是全雙工的,返回的文件描述符中的任何一個都可讀和可寫
int main ()
{
int fd[2];
int r = socketpair(AF_UNIX, SOCK_STREAM, 0, fd);
if (fork()){ /* 父進程 */
int val = 0;
close(fd[1]);
while (1){
sleep(1);
++val;
printf("發送數據: %d\n", val);
write(fd[0], &val, sizeof(val));
read(fd[0], &val, sizeof(val));
printf("接收數據: %d\n", val);
}
} else { /*子進程*/
int val;
close(fd[0]);
while(1){
read(fd[1], &val, sizeof(val));
++val;
write(fd[1], &val, sizeof(val));
}
}
}當我們使用 socketpair 創建了管道之后,父進程關閉了 fd[1],子進程關閉了 fd[0]。子進程可以通過 fd[1] 讀寫數據;同理主進程通過 fd[0]讀寫數據完成通信。
對應代碼:https://github.com/nodejs/node/blob/main/deps/uv/src/unix/process.c#L344
fork 函數開啟一個子進程的流程
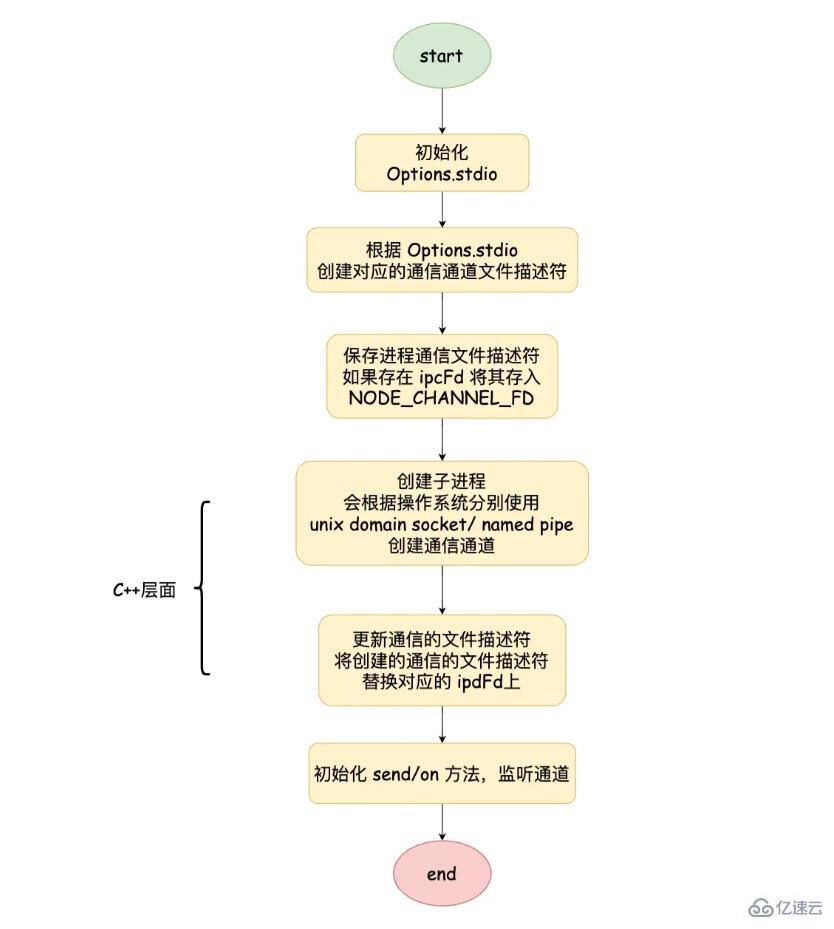
初始化參數中的 options.stdio,并且調用 spawn 函數
function spawn(file, args, options) {
const child = new ChildProcess();
child.spawn(options);
}創建 ChildProcess 實例,創建子進程也是調用 C++ 層 this._handle.spawn 方法
function ChildProcess() {
// C++層定義
this._handle = new Process();
}通過 child.spawn 調用到 ChildProcess.prototype.spawn 方法中。其中 getValidStdio 方法會根據 options.stdio 創建和 C++ 交互的 Pipe 對象,并獲得對應的文件描述符,將文件描述符寫入到環境變量 NODE_CHANNEL_FD 中,調用 C++ 層創建子進程,在調用 setupChannel 方法
ChildProcess.prototype.spawn = function(options) {
// 預處理進程間通信的數據結構
stdio = getValidStdio(stdio, false);
const ipc = stdio.ipc;
const ipcFd = stdio.ipcFd;
//將文件描述符寫入環境變量中
if (ipc !== undefined) {
ArrayPrototypePush(options.envPairs, `NODE_CHANNEL_FD=${ipcFd}`);
}
// 創建進程
const err = this._handle.spawn(options);
// 添加send方法和監聽IPC中數據
if (ipc !== undefined) setupChannel(this, ipc, serialization);
}子進程啟動時,會根據環境變量中是否存在 NODE_CHANNEL_FD 判斷是否調用 _forkChild 方法,創建一個 Pipe 對象, 同時調用 open 方法打開對應的文件描述符,在調用setupChannel
function _forkChild(fd, serializationMode) {
const p = new Pipe(PipeConstants.IPC);
p.open(fd);
p.unref();
const control = setupChannel(process, p, serializationMode);
}setupChannel 主要是完成了處理接收的消息、發送消息、處理文件描述符傳遞等
function setipChannel(){
channel.onread = function(arrayBuffer){
//...
}
target.on('internalMessage', function(message, handle){
//...
})
target.send = function(message, handle, options, callback){
//...
}
target._send = function(message, handle, options, callback){
//...
}
function handleMessage(message, handle, internal){
//...
}
}target.send: process.send 方法,這里 target 就是進程對象本身.
target._send: 執行具體 send 邏輯的函數, 當參數 handle 不存在時, 表示普通的消息傳遞;若存在,包裝為內部對象,表明是一個 internalMessage 事件觸發。調用使用JSON.stringify 序列化對象, 使用channel.writeUtf8String 寫入文件描述符中
channel.onread: 獲取到數據時觸發, 跟 channel.writeUtf8String 相對應。通過 JSON.parse 反序列化 message 之后, 調用 handleMessage 進而觸發對應事件
handleMessage: 用來判斷是觸發 message 事件還是 internalMessage 事件
target.on('internalMessage'): 針對內部對象做特殊處理,在調用 message 事件
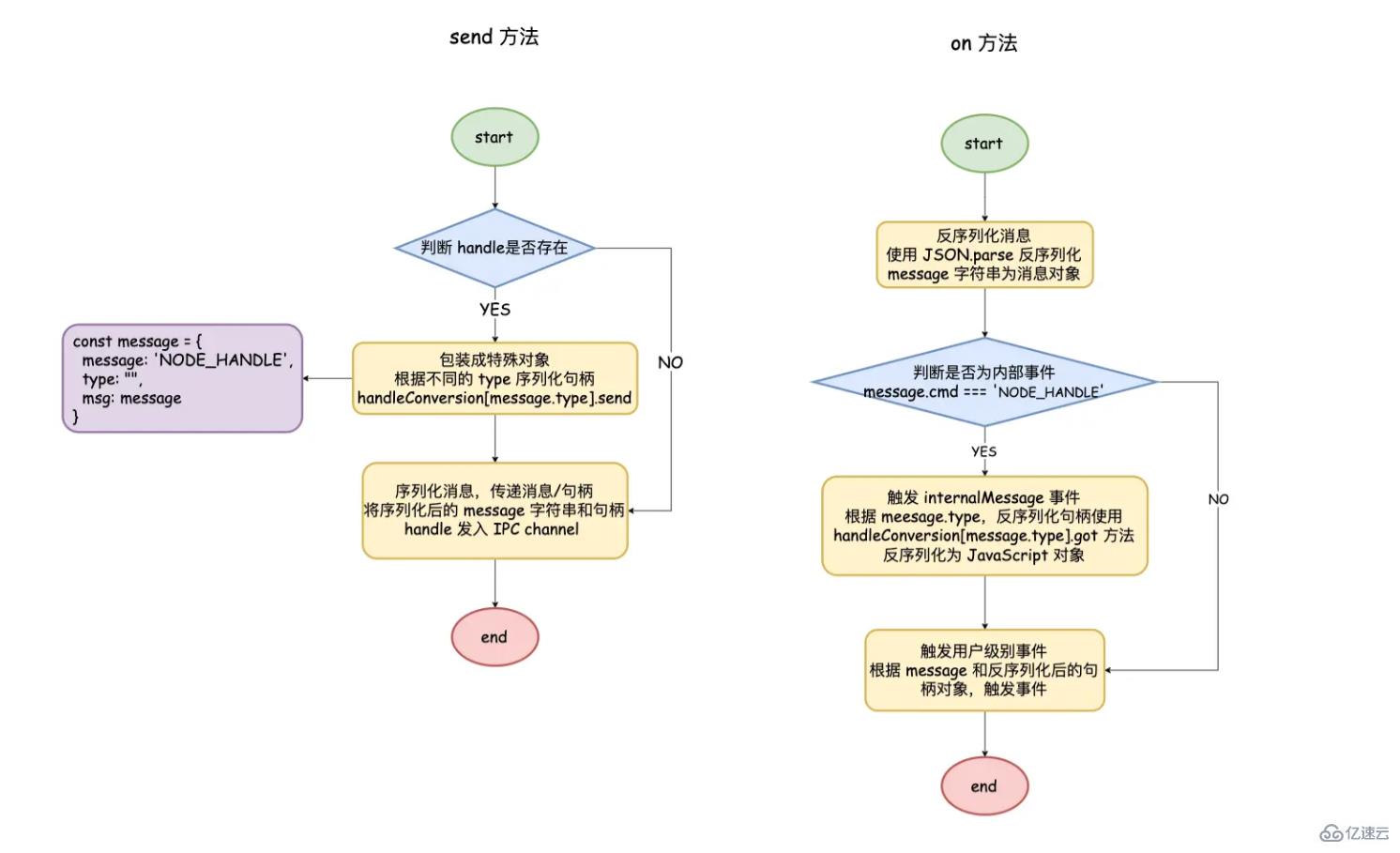
進程間消息傳遞
父進程通過 child.send 發送消息 和 server/socket 句柄對象
普通消息直接 JSON.stringify 序列化;對于句柄對象來說,需要先包裝成為內部對象
message = {
cmd: 'NODE_HANDLE',
type: null,
msg: message
};通過 handleConversion.[message.type].send 的方法取出句柄對象對應的 C++ 層面的 TCP 對象,在采用JSON.stringify 序列化
const handleConversion = {
'net.Server': {
simultaneousAccepts: true,
send(message, server, options) {
return server._handle;
},
got(message, handle, emit) {
const server = new net.Server();
server.listen(handle, () => {
emit(server);
});
}
}
//....
}最后將序列化后的內部對象和 TCP 對象寫入到 IPC 通道中
子進程在接收到消息之后,使用 JSON.parse 反序列化消息,如果為內部對象觸發 internalMessage 事件
檢查是否帶有 TCP 對象,通過 handleConversion.[message.type].got 得到和父進程一樣的句柄對象
最后發觸發 message 事件傳遞處理好的消息和句柄對象,子進程通過 process.on 接收
以上就是關于“Node中的進程間通信怎么實現”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





