溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何使用Node.js+Cheerio進行數據抓取”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“如何使用Node.js+Cheerio進行數據抓取”文章能幫助大家解決問題。

以下是本教程需要的一些東西:
你需要安裝Node.js。如果你沒有 Node,只需確保從Node.js 下載頁面為你的系統下載它
你需要在你的機器上安裝一個文本編輯器,比如VSCode或Atom
你至少應該對 JavaScript、Node.js 和文檔對象模型 (DOM) 有基本的了解。
Cheerio 是一個在 Node.js 中解析 HTML 和 XML 的工具,在 GitHub 上非常受歡迎,擁有超過23k 的 star 。
它快速、靈活且易于使用。由于它實現了 JQuery 的一個子集,如果你已經熟悉 JQuery,那么很容易開始使用 Cheerio。
Cheerio 和 Web 瀏覽器之間的主要區別在于,cheerio 不生成視覺渲染、加載 CSS、加載外部資源或執行 JavaScript。它只是解析標記并提供用于操作生成的數據結構的 API。這就解釋了為什么它也非常快——cheerio 文檔。
如果你想使用cheerio 來抓取網頁,您需要首先使用axios或node-fetch等包來獲取標記。
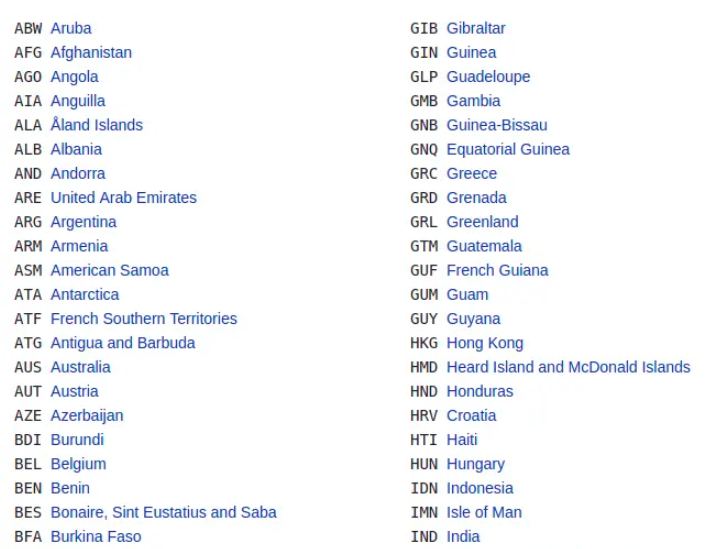
在此示例中,我們將抓取此 Wikipedia 頁面上列出的所有國家和其他司法管轄區的ISO 3166-1 alpha-3 代碼。它位于ISO 3166-1 alpha-3頁面的當前代碼部分下。
這是國家/司法管轄區列表及其相應代碼的樣子:
在此步驟中,您將通過在終端上運行以下命令為您的項目創建一個目錄。該命令將創建一個名為learn-cheerio. 如果你愿意,你可以給它一個不同的名字。
mkdir learn-cheerio
learn-cheerio成功運行上述命令后,您應該能夠看到一個名為 created 的文件夾。
在下一步中,您將在您喜歡的文本編輯器中打開剛剛創建的目錄并初始化項目。
在此步驟中,您將導航到項目目錄并初始化項目。在您喜歡的文本編輯器中打開您在上一步中創建的目錄,并通過運行以下命令來初始化項目。
npm init -y
成功運行上述命令將package.json在項目目錄的根目錄下創建一個文件。
在下一步中,您將安裝項目依賴項。
在此步驟中,您將通過運行以下命令來安裝項目依賴項。這將需要幾分鐘,所以請耐心等待。
npm i axios cheerio pretty
成功運行上述命令將在字段package.json下的文件中注冊三個依賴項。dependencies第一個依賴是axios,第二個是cheerio,第三個是pretty。
axios是一個非常流行的http 客戶端,可以在 node 和瀏覽器中運行。我們需要它,因為cheerio 是一個標記解析器。
為了讓 Cheerio 解析標記并抓取您需要的數據,我們需要axios用于從網站獲取標記。如果您愿意,可以使用另一個 HTTP 客戶端來獲取標記。它不一定是axios.
pretty是用于美化標記的 npm 包,以便在終端上打印時可讀。
在下一部分中,您將檢查將從中抓取數據的標記。
在從網頁中抓取數據之前,了解頁面的 HTML 結構非常重要。
在此步驟中,您將檢查要從中抓取數據的網頁的 HTML 結構。
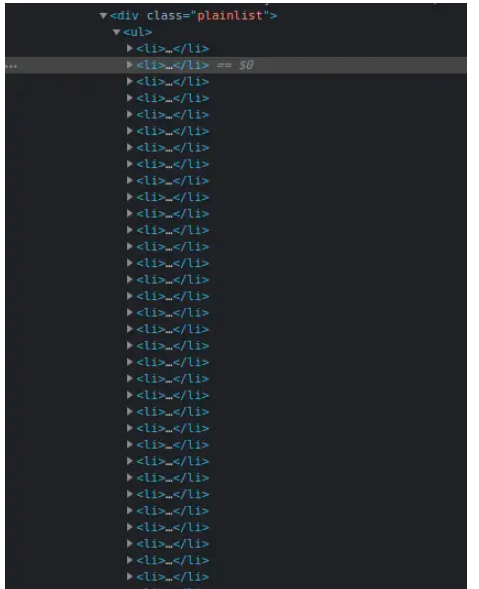
導航到Wikipedia 上的ISO 3166-1 alpha-3 代碼頁面。在“當前代碼”部分下,有一個國家列表及其相應的代碼。CTRL + SHIFT + I您可以通過按chrome 上的組合鍵或右鍵單擊然后選擇“檢查”選項來打開 DevTools 。
這是我在 chrome DevTools 中的列表:
在下一節中,您將編寫用于抓取網頁的代碼。
在本節中,你將編寫用于抓取我們感興趣的數據的代碼。首先運行以下將創建app.js文件的命令。
touch app.js
成功運行上述命令將app.js在項目目錄的根目錄下創建一個文件。
像任何其他 Node 包一樣,在開始使用它們之前,你必須首先require axios、cheerio和。你可以通過在剛剛創建pretty的文件頂部添加下面的代碼來做到這一點。app.js
const axios = require("axios");
const cheerio = require("cheerio");
const pretty = require("pretty");在我們編寫用于抓取數據的代碼之前,我們需要學習cheerio. 我們將解析下面的標記并嘗試操作生成的數據結構。這將幫助我們學習 Cheerio 語法及其最常用的方法。
下面的標記是ul包含我們元素的li元素。
const markup = ` <ul class="fruits"> <li class="fruits__mango"> Mango </li> <li class="fruits__apple"> Apple </li> </ul> `;
將上述變量聲明添加到app.js文件中
cheerio你可以使用該cheerio.load方法加載標記。該方法將標記作為參數。它還需要另外兩個可選參數。如果你有興趣,可以在文檔中閱讀有關它們的更多信息。
下面,我們傳遞第一個也是唯一需要的參數,并將返回值存儲在$變量中。我們使用該變量是因為cheerio 與Jquery$的相似性。如果你愿意,可以使用不同的變量名。
將以下代碼添加到你的app.js文件中:
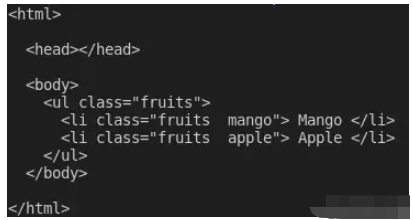
const $ = cheerio.load(markup); console.log(pretty($.html()));
如果你現在通過在終端上app.js運行命令來執行文件中的代碼node app.js,你應該能夠在終端上看到標記。這是我在終端上看到的:
Cheerio 支持大多數常見的 CSS 選擇器,例如class、id和element選擇器等。在下面的代碼中,我們選擇帶有類的元素fruits__mango,然后將所選元素記錄到控制臺。將以下代碼添加到你的app.js文件中。
const mango = $(".fruits__mango");
console.log(mango.html()); // Mango如果你使用命令執行,上述代碼行將Mango在終端上記錄文本。app.js``node app.js
您還可以選擇一個元素并獲取特定屬性,例如class、id或所有屬性及其對應值。
將以下代碼添加到你的app.js文件中:
const apple = $(".fruits__apple");
console.log(apple.attr("class")); //fruits__apple上面的代碼將登錄fruits__apple終端。fruits__apple是所選元素的類。
Cheerio 提供了.each循環遍歷多個選定元素的方法。
下面,我們選擇所有元素并使用該方法li循環遍歷它們。.each我們在終端上記錄每個列表項的文本內容。
將以下代碼添加到你的app.js文件中。
const listItems = $("li");
console.log(listItems.length); // 2
listItems.each(function (idx, el) {
console.log($(el).text());
});
// Mango
// Apple上面的代碼會記錄2,也就是列表項的長度,執行完代碼后會在終端上顯示文字Mango和。Apple``app.js
Cheerio 提供了一種將元素附加或附加到標記的方法。
該append方法會將作為參數傳遞的元素添加到所選元素的最后一個子元素之后。另一方面,prepend將在選定元素的第一個子元素之前添加傳遞的元素。
將以下代碼添加到你的app.js文件中:
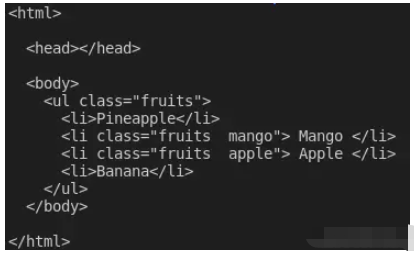
const ul = $("ul");
ul.append("<li>Banana</li>");
ul.prepend("<li>Pineapple</li>");
console.log(pretty($.html()));在向標記添加和添加元素之后,這是我登錄$.html()終端時看到的內容:
這些是 Cheerio 的基礎知識,可以幫助你開始網絡抓取。
要從 Wikipedia 抓取我們在本文開頭描述的數據,請將以下代碼復制并粘貼到app.js文件中:
// Loading the dependencies. We don't need pretty
// because we shall not log html to the terminal
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
// URL of the page we want to scrape
const url = "https://en.wikipedia.org/wiki/ISO_3166-1_alpha-3";
// Async function which scrapes the data
async function scrapeData() {
try {
// Fetch HTML of the page we want to scrape
const { data } = await axios.get(url);
// Load HTML we fetched in the previous line
const $ = cheerio.load(data);
// Select all the list items in plainlist class
const listItems = $(".plainlist ul li");
// Stores data for all countries
const countries = [];
// Use .each method to loop through the li we selected
listItems.each((idx, el) => {
// Object holding data for each country/jurisdiction
const country = { name: "", iso3: "" };
// Select the text content of a and span elements
// Store the textcontent in the above object
country.name = $(el).children("a").text();
country.iso3 = $(el).children("span").text();
// Populate countries array with country data
countries.push(country);
});
// Logs countries array to the console
console.dir(countries);
// Write countries array in countries.json file
fs.writeFile("coutries.json", JSON.stringify(countries, null, 2), (err) => {
if (err) {
console.error(err);
return;
}
console.log("Successfully written data to file");
});
} catch (err) {
console.error(err);
}
}
// Invoke the above function
scrapeData();通過閱讀代碼,你了解正在發生的事情嗎?如果沒有,我現在將詳細介紹。我還對每一行代碼進行了注釋,以幫助你理解。
在上面的代碼中,我們需要文件頂部的所有依賴項,app.js然后我們聲明了scrapeData函數。在函數內部,使用axios. 然后將我們需要抓取的頁面的獲取 HTML 加載到cheerio.
國家/地區列表及其對應iso3代碼嵌套在一個div具有 . 類的元素中plainlist。li元素被選中,然后我們使用該方法循環遍歷它們.each。每個國家的數據都被抓取并存儲在一個數組中。
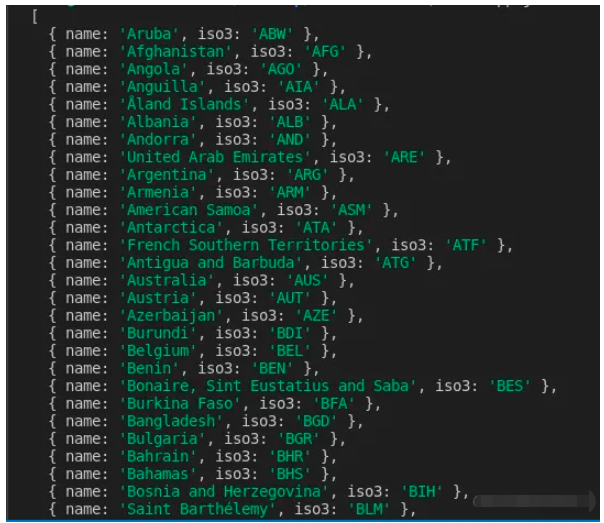
使用命令運行上述代碼后node app.js,將抓取的數據寫入countries.json文件并打印在終端上。這是我在終端上看到的部分內容:
關于“如何使用Node.js+Cheerio進行數據抓取”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





