溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么使用Python3讀取文件”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么使用Python3讀取文件”吧!
基本用法
先來看一下fileinput的基本功能:
fileinput.filename():返回當前被讀取的文件名。
—>在第一行被讀取之前,返回 None。
fileinput.fileno():返回以整數表示的當前文件“文件描述符”。
—>當未打開文件時(處在第一行和文件之間),返回 -1。
fileinput.lineno():返回已被讀取的累計行號。
—>在第一行被讀取之前,返回 0。在最后一個文件的最后一行被讀取之后,返回該行的行號。
fileinput.filelineno():返回當前文件中的行號。
—>在第一行被讀取之前,返回 0。
—>在最后一個文件的最后一行被讀取之后,返回此文件中該行的行號。
進階用法
fileinput.isfirstline():如果剛讀取的行是其所在文件的第一行則返回 True,否則返回 False。
fileinput.isstdin():如果最后讀取的行來自 sys.stdin 則返回 True,否則返回 False。
fileinput.nextfile():關閉當前文件以使下次迭代將從下一個文件(如果存在)讀取第一行;不是從該文件讀取的行將不會被計入累計行數。直到下一個文件的第一行被讀取之后文件名才會改變。
—>在第一行被讀取之前,此函數將不會生效;它不能被用來跳過第一個文件。
—>在最后一個文件的最后一行被讀取之后,此函數將不再生效。
fileinput.close():關閉序列。
代碼示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
import fileinput
'當 Python 腳本沒有傳入任何參數時,fileinput 默認會以 stdin 作為輸入源'
for line in fileinput.input():
print(f'{line}')運行結果
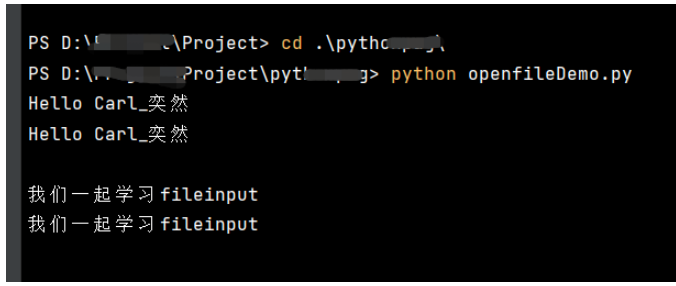
你輸入的內容,程序都會讀取并再輸出。
俗稱:復讀機
代碼示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
import fileinput
'files 輸入打開文件的名稱即可'
with fileinput.input(files=('output.txt',)) as file:
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行:{line}',end='')運行結果
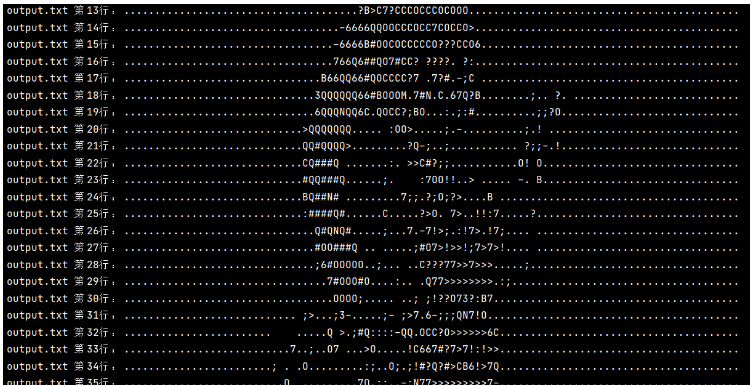
解析:
fileinput 有且僅有這兩種讀取模式:‘r’,‘rb’;
fileinput.input() 默認使用 mode=‘r’ 的模式讀取文件,如果你的文件是二進制的,可以使用mode=‘rb’ 模式。
多文件序號連續排序
調用方法
fileinput.lineno()方法
代碼示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
import fileinput
'files 輸入打開文件的名稱即可'
with fileinput.input(files=('output.txt','input.txt')) as file:
for line in file:
#fileinput.lineno() 把兩個文件的整合陳一個文件對象file,需要排序輸出
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
# fileinput.filelineno()兩個文件單獨讀取,需要單獨排序
print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')運行結果
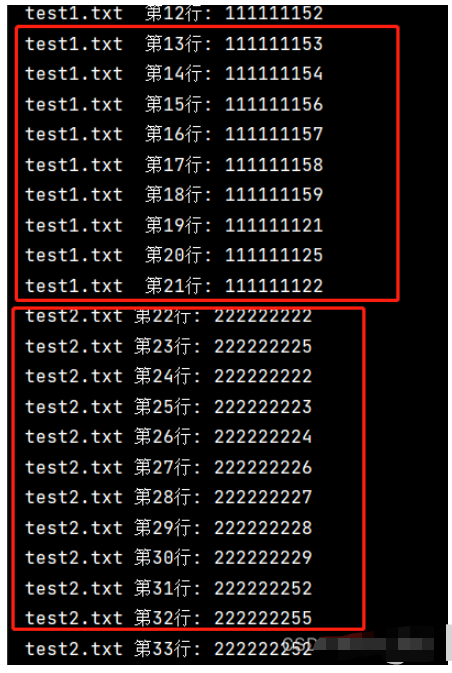
多文件序號單獨排序
調用方法
fileinput.filelineno()方法
代碼示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
import fileinput
'files 輸入打開文件的名稱即可'
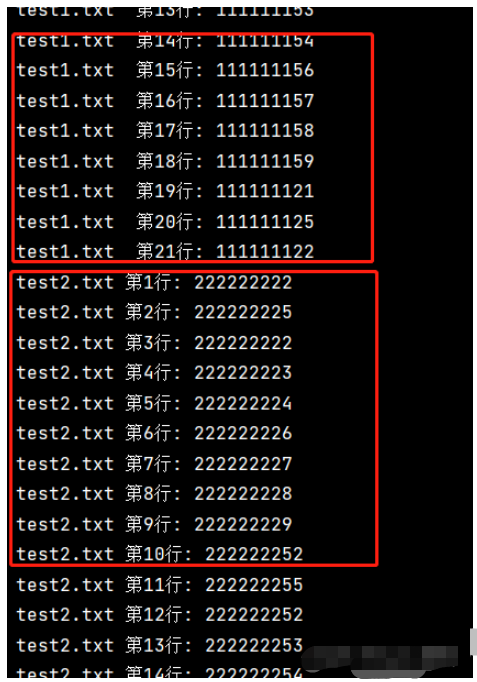
with fileinput.input(files=('test1.txt','test2.txt')) as file:
for line in file:
# fileinput.filelineno()兩個文件單獨讀取,需要單獨排序
print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')運行結果
與glob配合用法
在顏值的時代,上面的輸出樣式,已經無法滿足我們的需要了,
于是乎,我們就想到了glob。
代碼示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
import fileinput
import glob
#glob 匹配te開頭的txt文件
for line in fileinput.input(glob.glob("te*.txt")):
if fileinput.isfirstline():
#輸出讀取文件
print('='*10,f'讀取文件{fileinput.filename()}','='*10)
#fileinput.filelineno()方法讀取
print(str(fileinput.filelineno())+ ':'+line.upper(),end='')運行結果
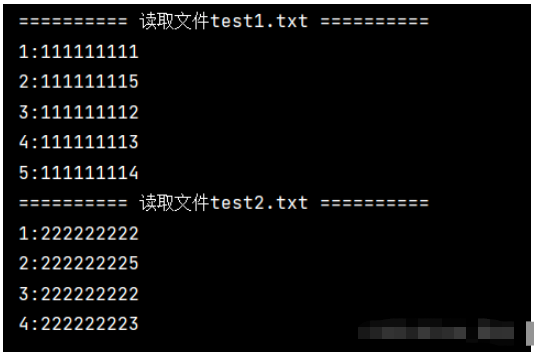
就這顏值,哪個小姐姐能不喜歡呢。
調用方法
fileinput.input 的backup 參數,可以指定備份的后綴名,比如 .bak
代碼示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
import fileinput
#觸發backup的動作,源文件內容被修改,對源文件進行backup
with fileinput.input(files=("test1.txt",), backup=".bak",inplace=1) as file:
for line in file:
print(line.rstrip().replace('111111', '222222'))
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')運行結果

解析
上面的例子, 用到了 inplace參數,表示是否將標準輸出的結果寫回文件,默認不取代
代碼示例:
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
import fileinput
#觸發backup的動作,源文件內容被修改,對源文件進行backup
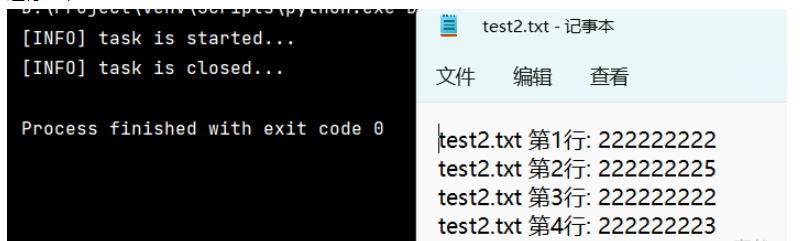
with fileinput.input(files=("test2.txt",), inplace=True) as file:
print("[INFO] task is started...")
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
print("[INFO] task is closed...")運行結果
注
通過運行結果,可以看到:
- 在 for 循環體內的 print 內容會寫回到原文件中了。
- 而在 for 循環體外的 print 則沒有變化。
openhook含義解析
在 fileinput.input() 中有一個 openhook 的參數,它支持用戶傳入自定義的對象讀取方法;
-如果沒有傳入任何勾子,fileinput 默認使用的是 open 函數;
方法介紹
fileinput 內置了兩種勾子
1、fileinput.hook_compressed(filename, mode)
使用 gzip 和 bz2 模塊透明地打開 gzip 和 bzip2 壓縮的文件(通過擴展名 ‘.gz’ 和 ‘.bz2’ 來識別);
如果文件擴展名不是 ‘.gz’ 或 ‘.bz2’,文件會以正常方式打開(即使用 open() 并且不帶任何解壓操作);
使用示例: fi = fileinput.FileInput(openhook=fileinput.hook_compressed)
2、fileinput.hook_encoded(encoding, errors=None)
返回一個通過 open() 打開每個文件的鉤子,使用給定的 encoding 和 errors 來讀取文件。
使用示例: fi = fileinput.FileInput(openhook=fileinput.hook_encoded(“utf-8”, “surrogateescape”))
示例實戰
假如我想要使用 fileinput 來讀取網絡上的文件,思路:
先使用 requests 下載文件到本地
再使用 open 去讀取它;
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
def online_open(url, mode):
import requests
r = requests.get(url)
filename = url.split("/")[-1]
with open(filename,'w') as f1:
f1.write(r.content.decode("utf-8"))
f2 = open(filename,'r')
return f2直接將這個函數傳給 openhook 即可:
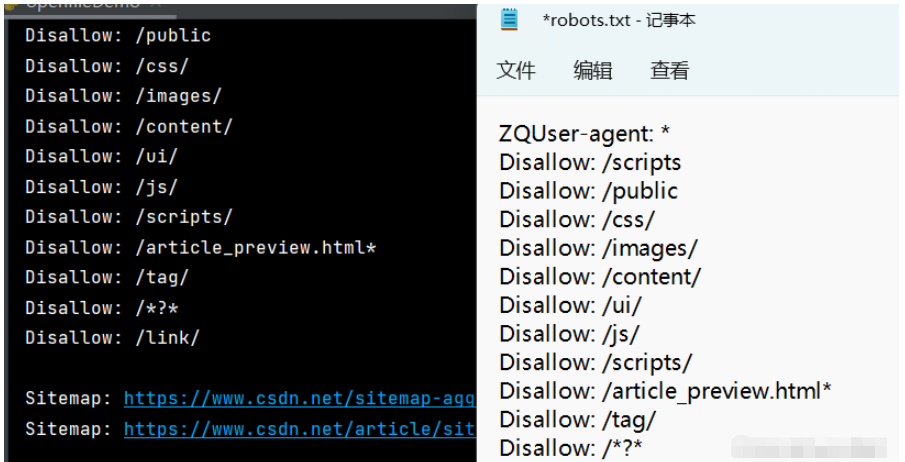
# -*- coding:utf-8 -*- # @Time : 2022-07-23 # @Author : carl_DJ import fileinput file_url = 'https://www.csdn.net/robots.txt' with fileinput.input(files=(file_url,), openhook=online_open) as file: for line in file: print(line, end="")
代碼整合:
# -*- coding:utf-8 -*-
# @Time : 2022-07-23
# @Author : carl_DJ
def online_open(url, mode):
import requests
r = requests.get(url)
filename = url.split("/")[-1]
with open(filename,'w') as f1:
f1.write(r.content.decode("utf-8"))
f2 = open(filename,'r')
return f2
import fileinput
file_url = 'https://www.csdn.net/robots.txt'
with fileinput.input(files=(file_url,), openhook=online_open) as file:
for line in file:
print(line, end="")運行結果
到此,相信大家對“怎么使用Python3讀取文件”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





