溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下js正則表達式的原理是什么的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
下面是我對正則的理解:
正則就是用有限的符號,表達無限的序列,殆已!
正則表達式的語法一般如下(js),兩條斜線中間是正則主體,這部分可以有很多字符組成;i部分是修飾符,i的意思表示忽略大小寫
/^abc/i
正則定義了很多特殊意義的字符,有名詞,量詞,謂詞等,下面逐一介紹
沒有特殊意義的字符都是簡單字符,簡單字符就代表自身,絕大部分字符都是簡單字符,舉個例子
/abc/ // 匹配 abc /123/ // 匹配 123 /-_-/ // 匹配 -_- /海鏡/ // 匹配 海鏡
\是轉義字符,其后面的字符會代表不同的意思,轉義字符主要有三個作用:
第一種,是為了匹配不方便顯示的特殊字符,比如換行,tab符號等
第二種,正則中預先定義了一些代表特殊意義的字符,比如\w等
第三種,在正則中某些字符有特殊含義(比如下面說到的),轉義字符可以讓其顯示自身的含義
下面是常用轉義字符列表:
| \n | 匹配換行符 |
| \r | 匹配回車符 |
| \t | 匹配制表符,也就是tab鍵 |
| \v | 匹配垂直制表符 |
| \x20 | 20是2位16進制數字,代表對應的字符 |
| \u002B | 002B是4位16進制數字,代表對應的字符 |
| \u002B | 002B是4位16進制數字,代表對應的字符 |
| \w | 匹配任何一個字母或者數字或者下劃線 |
| \W | 匹配任何一個字母或者數字或者下劃線以外的字符 |
| \s | 匹配空白字符,如空格,tab等 |
| \S | 匹配非空白字符 |
| \d | 匹配數字字符,0~9 |
| \D | 匹配非數字字符 |
| \b | 匹配單詞的邊界 |
| \B | 匹配非單詞邊界 |
| \\ | 匹配\本身 |
有時我們需要匹配一類字符,字符集可以實現這個功能,字符集的語法用[``]分隔,下面的代碼能夠匹配a或b或c
[abc]
如果要表示字符很多,可以使用-表示一個范圍內的字符,下面兩個功能相同
[0123456789] [0-9]
在前面添加^,可表示非的意思,下面的代碼能夠匹配a``b``c之外的任意字符
[^abc]
其實正則還內置了一些字符集,在上面的轉義字符有提到,下面給出內置字符集對應的自定義字符集
. 匹配除了換行符(\n)以外的任意一個字符 = [^\n]
\w = [0-9a-zA-Z_]
\W = [^0-9a-zA-Z_]
\s = [ \t\n\v]
\S = [^ \t\n\v]
\d = [0-9]
\D = [^0-9]
如果我們有三個蘋果,我們可以說自己有個3個蘋果,也可以說有一個蘋果,一個蘋果,一個蘋果,每種語言都有量詞的概念
如果需要匹配多次某個字符,正則也提供了量詞的功能,正則中的量詞有多個,如?、+、*、{n}、{m,n}、{m,}
{n}匹配n次,比如a{2},匹配aa
{m, n}匹配m-n次,優先匹配n次,比如a{1,3},可以匹配aaa、aa、a
{m,}匹配m-∞次,優先匹配∞次,比如a{1,},可以匹配aaaa...
?匹配0次或1次,優先匹配1次,相當于{0,1}
+匹配1-n次,優先匹配n次,相當于{1,}
*匹配0-n次,優先匹配n次,相當于{0,}
正則默認和人心一樣是貪婪的,也就是常說的貪婪模式,凡是表示范圍的量詞,都優先匹配上限而不是下限
a{1, 3} // 匹配字符串'aaa'的話,會匹配aaa而不是a有時候這不是我們想要的結果,可以在量詞后面加上?,就可以開啟非貪婪模式
a{1, 3}? // 匹配字符串'aaa'的話,會匹配a而不是aaa有時我們會有邊界的匹配要求,比如以xxx開頭,以xxx結尾
^在[]外表示匹配開頭的意思
^abc // 可以匹配abc,但是不能匹配aabc
$表示匹配結尾的意思
abc$ // 可以匹配abc,但是不能匹配abcc
上面提到的\b表示單詞的邊界
abc\b // 可以匹配 abc ,但是不能匹配 abcc
有時我們想匹配x或者y,如果x和y是單個字符,可以使用字符集,[abc]可以匹配a或b或c,如果x和y是多個字符,字符集就無能為力了,此時就要用到分組
正則中用|來表示分組,a|b表示匹配a或者b的意思
123|456|789 // 匹配 123 或 456 或 789
分組是正則中非常強大的一個功能,可以讓上面提到的量詞作用于一組字符,而非單個字符,分組的語法是圓括號包裹(xxx)
(abc){2} // 匹配abcabc分組不能放在[]中,分組中還可以使用選擇表達式
(123|456){2} // 匹配 123123、456456、123456、456123和分組相關的概念還有一個捕獲分組和非捕獲分組,分組默認都是捕獲的,在分組的(后面添加?:可以讓分組變為非捕獲分組,非捕獲分組可以提高性能和簡化邏輯
'123'.match(/(?:123)/) // 返回 ['123'] '123'.match(/(123)/) // 返回 ['123', '123']
和分組相關的另一個概念是引用,比如在匹配html標簽時,通常希望<xxx></xxx>后面的xxx能夠和前面保持一致
引用的語法是\數字,數字代表引用前面第幾個捕獲分組,注意非捕獲分組不能被引用
<([a-z]+)><\/\1> // 可以匹配 `<span></span>` 或 `<div></div>`等
如果你想匹配xxx前不能是yyy,或者xxx后不能是yyy,那就要用到預搜索
js只支持正向預搜索,也就是xxx后面必須是yyy,或者xxx后面不能是yyy
1(?=2) // 可以匹配12,不能匹配22 1(?!2) // 可有匹配22,不能匹配12
默認正則是區分大小寫,這可能并不是我們想要的,正則提供了修飾符的功能,修復的語法如下
/xxx/gi // 最后面的g和i就是兩個修飾符
g正則遇到第一個匹配的字符就會結束,加上全局修復符,可以讓其匹配到結束
i正則默認是區分大小寫的,i可以忽略大小寫
m正則默認情況下,^和只能匹配字符串的開始和結尾,m修飾符可以讓和只能匹配字符串的開始和結尾,m修飾符可以讓^和只能匹配字符串的開始和結尾,m修飾符可以讓和匹配行首和行尾,不理解就看例子
/jing$/ // 能夠匹配 'yanhaijing,不能匹配 'yanhaijing\n' /jing$/m // 能夠匹配 'yanhaijing, 能夠匹配 'yanhaijing\n' /^jing/ // 能夠匹配 'jing',不能匹配 '\njing' /^jing/m // 能夠匹配 'jing',能夠匹配 '\njing'
有時我們會遇到特別復雜的正則,有時候可能不太直觀,下面推薦一個圖形化展示的工具,我們把涉及到的語法羅列一下
/^[a-z]*[^\d]{1,10}?(aaa|bbb)(?:ccc)$/可以看到工具能夠更快的幫我們理清頭緒
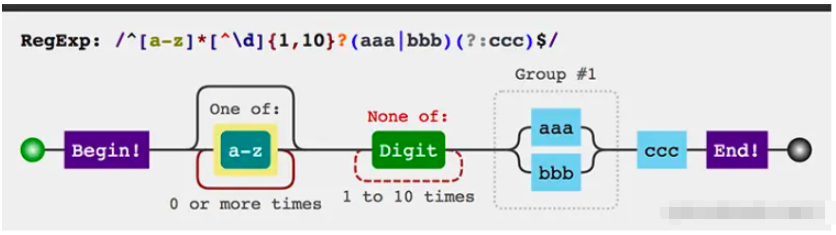
在js中創建正則有兩種辦法,字面量和new,和創建其他類型變量一樣
var reg = /abc/g // 字面量
var reg = new RegExp('abc', 'g') // new方式,意思和上面一樣js中用到正則的地方有兩個入口,正則的api和字符串的api,RegExp#test等于RegExp.prototype.test
RegExp#test
RegExp#exec
String#search
String#match
String#split
String#replace
每個正則實例都有test方法,test的參數是字符串,返回值是布爾值,表示當前正則是否能匹配指定的字符串
/abc/.test('abc') // true
/abc/.test('abd') // falseexec使用方法和test一樣,只是返回值并不是布爾值,而是返回匹配的結果
匹配成功返回一個數組,數組第一項是匹配結果,后面一次是捕獲的分組
/abc(d)/.exec('abcd') // ["abcd", "d", index: 0, input: "abcd"]此數組還有另外兩個參數,input是輸入的字符串,index表示匹配成功的序列在輸入字符串中的索引位置
如果有全局參數(g),第二次匹配時將從上次匹配結束時繼續
var r1 = /ab/
r1.exec('ababab') // ['ab', index: 0]
r1.exec('ababab') // ['ab', index: 0]
var r2 = /ab/g
r2.exec('ababab') // ['ab', index: 0]
r2.exec('ababab') // ['ab', index: 2]
r2.exec('ababab') // ['ab', index: 4]這一特性可以被用于循環匹配,比如統計字符串中abc的次數
var reg = /abc/g
var str = 'abcabcabcabcabc'
var num = 0;
var match = null;
while((match = reg.exec(str)) !== null) {
num++
}
console.log(num) // 5如果匹配失敗則返回null
/abc(d)/.exec('abc') // nullsearch方法返回匹配成功位置的索引,參數是字符串或正則,結果是索引
'abc'.search(/abc/) // 0 'abc'.search(/c/) // 2
如果匹配失敗則返回-1
'abc'.search(/d/) // -1 'abc'.search(/d/) !== -1 // false 轉換為布爾值
match方法也會返回匹配的結果,匹配結果和exec類似
'abc'.match(/abc/) // ['abc', index: 0, input: abc] 'abc'.match(/abd/) // null
如果有全局參數(g),match會返回所有的結果,并且沒有index和input屬性
'abcabcabc'.match(/abc/g) // ['abc', 'abc', 'abc']
字符串的split方法,可以用指定符號分隔字符串,并返回數據
'a,b,c'.split(',') // [a, b, c]其參數也可以使一個正則,如果分隔符有多個時,就必須使用正則
'a,b.c'.split(/,|\./) // [a, b, c]
字符串的replace方法,可以將字符串的匹配字符,替換成另外的指定字符
'abc'.replace('a', 'b') // 'bbc'其第一個參數可以是正則表達式,如果想全局替換需添加全局參數
'abc'.replace(/[abc]/, 'y') // ybc 'abc'.replace(/[abc]/g, 'y') // yyy 全局替換
在第二個參數中,也可以引用前面匹配的結果
'abc'.replace(/a/, '$&b') // abbc $& 引用前面的匹配字符 'abc'.replace(/(a)b/, '$1a') // aac &n 引用前面匹配字符的分組 'abc'.replace(/b/, '$\'') // aac $` 引用匹配字符前面的字符 'abc'.replace(/b/, "$'") // acc $' 引用匹配字符后面的字符
replace的第二個參數也可以是函數,其第一個參數是匹配內容,后面的參數是匹配的分組
'abc'.replace(/\w/g, function (match, $1, $2) {
return match + '-'
})
// a-b-c-RegExp是一個全局函數,可以用來創建動態正則,其自身也有一些屬性
$_
$n
input
length
lastMatch
來個例子
/a(b)/.exec('abc') // ["ab", "b", index: 0, input: "abc"]
RegExp.$_ // abc 上一次匹配的字符串
RegExp.$1 // b 上一次匹配的捕獲分組
RegExp.input // abc 上一次匹配的字符串
RegExp.lastMatch // ab 上一次匹配成功的字符
RegExp.length // 2 上一次匹配的數組長度正則表達式的實例上也有一些屬性
flags
ignoreCase
global
multiline
source
lastIndex
還是看例子
var r = /abc/igm; r.flags // igm r.ignoreCase // true r.global // true r.multiline // true r.source // abc
lastIndex比較有意思,表示上次匹配成功的是的索引
var r = /abc/igm;
r.exec('abcabcabc')
r.lastIndex // 3
r.exec('abcabcabc')
r.lastIndex // 6可以更改lastIndex讓其重新開始
var r = /abc/igm;
r.exec('abcabcabc') // ["abc", index: 0]
r.exec('abcabcabc') // ["abc", index: 3]
r.lastIndex = 0
r.exec('abcabcabc') // ["abc", index: 0]來幾個常用的例子
/(?:0\d{2,3}-)?\d{7}/ // 電話號 010-xxx xxx
/^1[378]\d{9}$/ // 手機號 13xxx 17xxx 18xxx
/^[0-9a-zA-Z_]+@[0-9a-zA-Z]+\.[z-z]+$/ // 郵箱去除字符串前后空白
str = str.replace(/^\s*|\s*$/g, '')
以上就是“js正則表達式的原理是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





