溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么用Python讀取千萬級數據自動寫入MySQL數據庫”,在日常操作中,相信很多人在怎么用Python讀取千萬級數據自動寫入MySQL數據庫問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么用Python讀取千萬級數據自動寫入MySQL數據庫”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
使用 navicat 工具的導入向導功能。支持多種文件格式,可以根據文件的字段自動建表,也可以在已有表中插入數據,非常快捷方便。
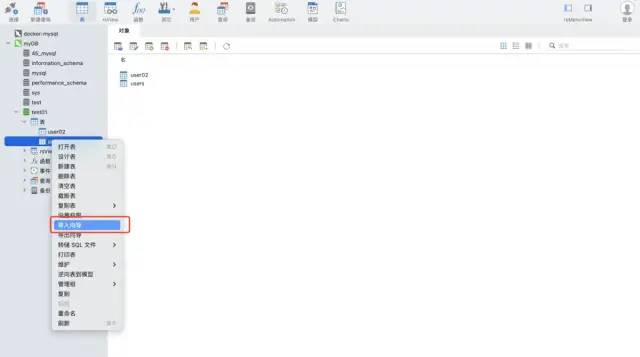
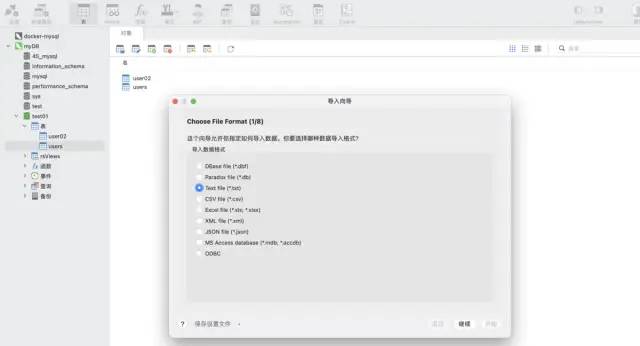
測試數據:csv 格式 ,大約 1200萬行
import pandas as pd
data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv')
data.shape打印結果:

方式一:python ? pymysql 庫
安裝 pymysql 命令:
pip install pymysql
代碼實現:
import pymysql
# 數據庫連接信息
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='wangyuqing',
db='test01',
port = 3306,
charset="utf8")
# 分塊處理
big_size = 100000
# 分塊遍歷寫入到 mysql
with pd.read_csv('./tianchi_mobile_recommend_train_user.csv',chunksize=big_size) as reader:
for df in reader:
datas = []
print('處理:',len(df))
# print(df)
for i ,j in df.iterrows():
data = (j['user_id'],j['item_id'],j['behavior_type'],
j['item_category'],j['time'])
datas.append(data)
_values = ",".join(['%s', ] * 5)
sql = """insert into users(user_id,item_id,behavior_type
,item_category,time) values(%s)""" % _values
cursor = conn.cursor()
cursor.executemany(sql,datas)
conn.commit()
# 關閉服務
conn.close()
cursor.close()
print('存入成功!')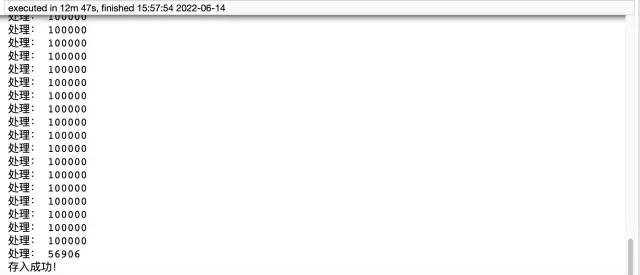
方式二:pandas ? sqlalchemy:pandas需要引入sqlalchemy來支持sql,在sqlalchemy的支持下,它可以實現所有常見數據庫類型的查詢、更新等操作。
代碼實現:
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:wangyuqing@localhost:3306/test01')
data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv')
data.to_sql('user02',engine,chunksize=100000,index=None)
print('存入成功!')pymysql 方法用時12分47秒,耗時還是比較長的,代碼量大,而 pandas 僅需五行代碼就實現了這個需求,只用了4分鐘左右。最后補充下,方式一需要提前建表,方式二則不需要。所以推薦大家使用第二種方式,既方便又效率高。如果還覺得速度慢的小伙伴,可以考慮加入多進程、多線程。
最全的三種將數據存入到 MySQL 數據庫方法:
直接存,利用 navicat 的導入向導功能
Python pymysql
Pandas sqlalchemy
到此,關于“怎么用Python讀取千萬級數據自動寫入MySQL數據庫”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





