溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“SQLite3基本使用方法有哪些”,內容詳細,步驟清晰,細節處理妥當,希望這篇“SQLite3基本使用方法有哪些”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
.open filename --打開文件 -- 注解 .show --顯示SQLite 命令提示符的默認設置 .q --退出 .databases --顯示數據庫(注:顯示打開的數據庫) .help --幫助 .dump --導入導出數據庫 .tables --查看表
| 存儲類型 | 描述 |
| NULL | 空值 |
| int | 整形 |
| text | 一個文本字符串 |
| blob | 一個blob數據 |
| integer | 一個帶符號的整數,根據值的大小存儲在1、2 、3、4、6或8字節中 |
| real | 值是一個浮點值,存儲為8字節的浮點數 |
| ...... | ...... |
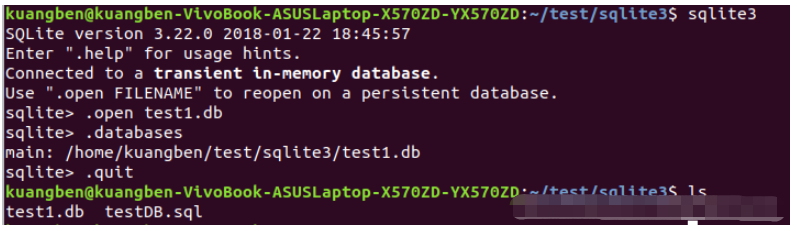
.open test.db --沒有就創建 sqlite3 DatabaseName.db

上面的命令將在當前目錄下創建一個文件 testDB.db。該文件將被 SQLite 引擎用作數據庫。如果您已經注意到 sqlite3 命令在成功創建數據庫文件之后,將提供一個 sqlite> 提示符。
.databases 命令用于檢查它是否在數據庫列表中。
.open 操作
sqlite3 test.db .dump > filename --導出 sqlite3 test.db < filename --導入

上面的轉換流整個 testDB.db 數據庫的內容到 SQLite 的語句中,并將其轉儲到 ASCII 文本文件 testDB.sql 中。您可以通過簡單的方式從生成的 testDB.sql 恢復,如下所示 我刪掉testDB.db后:

--注意,在打開數據庫時才能操作 CREATE TABLE database_name.table_name( column1 datatype PRIMARY KEY(one or more columns), column2 datatype, column3 datatype, ..... columnN datatype, );
CREATE TABLE 是告訴數據庫系統創建一個新表的關鍵字。CREATE TABLE 語句后跟著表的唯一的名稱或標識。您也可以選擇指定帶有 table_name 的 database_name。
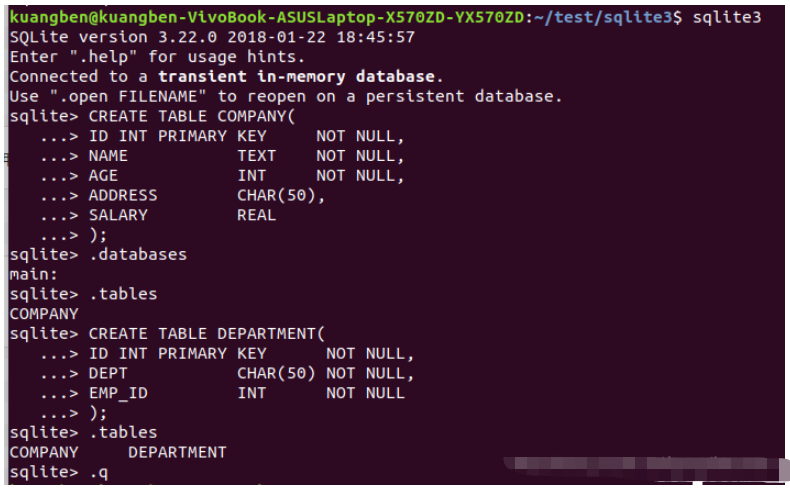
如上圖所示,我們創建了COMPANY DEPARTMENT兩個表。其中ID 作為主鍵,NOT NULL 的約束表示在表中創建紀錄時這些字段不能為 NULL。
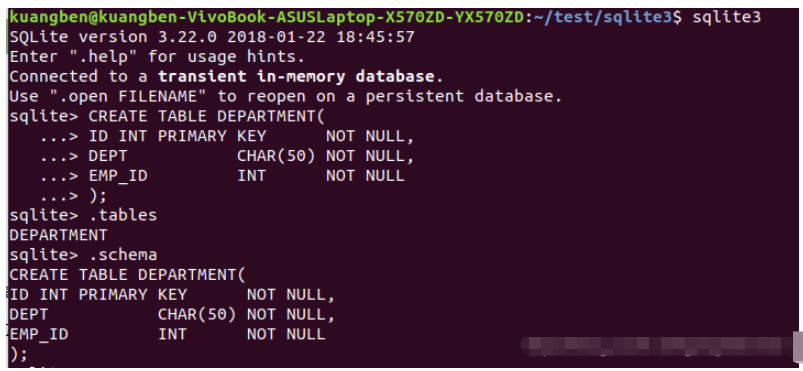
.schema --注意:打開數據庫時才能操作
DROP TABLE database_name.table_name;
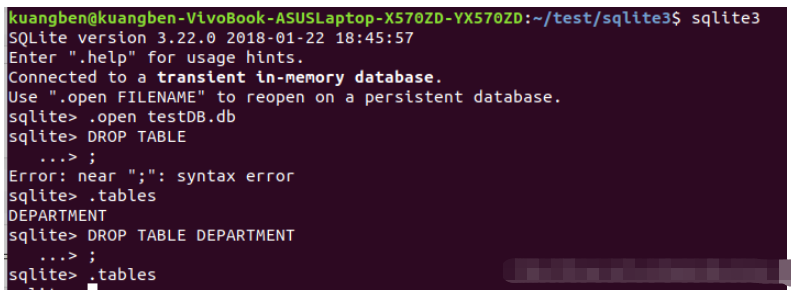
如上,刪除了名為DEPARTMENT的表
INSERT INTO TABLE_NAME [(column1, column2, column3,...columnN)] VALUES (value1, value2, value3,...valueN);
在這里,column1, column2,...columnN 是要插入數據的表中的列的名稱。
如果要為表中的所有列添加值,您也可以不需要在 SQLite 查詢中指定列名稱。但要確保值的順序與列在表中的順序一致。SQLite 的 INSERT INTO 語法如下:
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
現在,我已經創建了COMPANY表,如下
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
現在,下面的語句將在 COMPANY 表中創建六個記錄:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'Teddy', 23, 'Norway', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (5, 'David', 27, 'Texas', 85000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (6, 'Kim', 22, 'South-Hall', 45000.00 );
輸出結果如下:
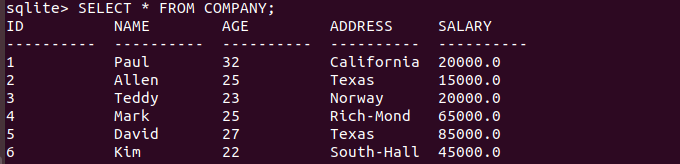
我們也可以使用第二種語法在COMPANY 表中創建一個記錄,如下所示:
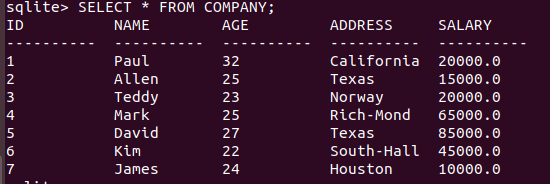
INSERT INTO COMPANY VALUES (7, 'James', 24, 'Houston', 10000.00 );
輸出結果如下:
.header on .mode column .timer on --開啟CPU定時器 SELECT * FROM table_name; --顯示表table_name
非格式化輸出

格式化輸出
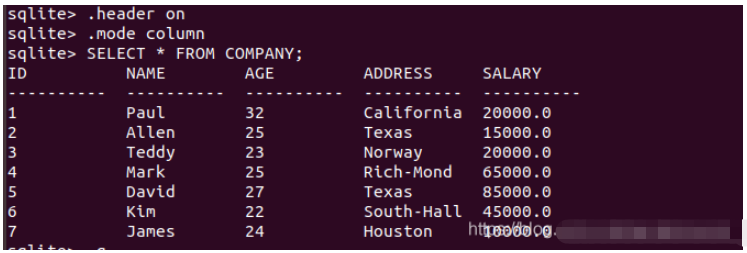
完整輸出
.header on .mode column SELECT * FROM COMPANY;
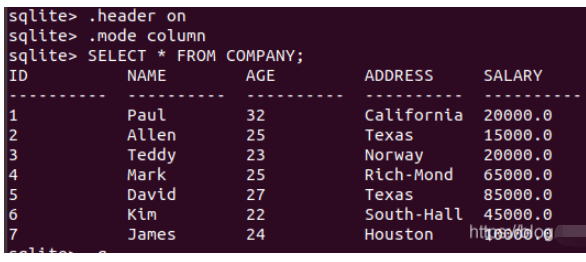
輸出指定列
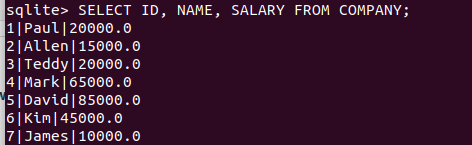
.header on .mode column SELECT ID, NAME, SALARY FROM COMPANY; --只輸出ID, NAME和SALARY三列
設置輸出列的寬度
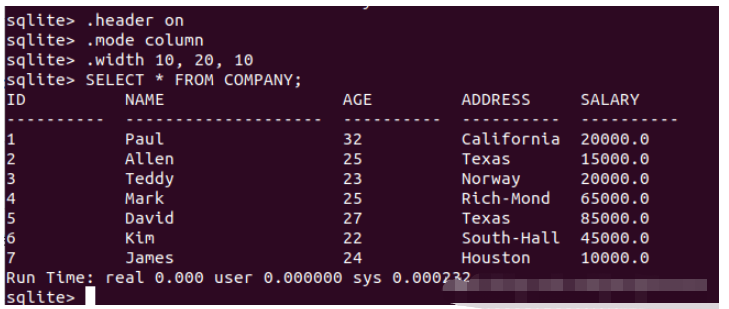
.width num1,num1,num3.... SELECT * FROM COMPANY;
下面 .width 命令設置第一列的寬度為 10,第二列的寬度為 20,第三列的寬度為 10。輸出結果如下:
sqlite運算符主要用于 SQLite 語句的 WHERE 子句中執行操作,如比較和算術運算。
運算符用于指定 SQLite 語句中的條件,并在語句中連接多個條件。
算術運算符:
運算符描述實例+加法 - 把運算符兩邊的值相加a + b 將得到 30-減法 - 左操作數減去右操作數a - b 將得到 -10*乘法 - 把運算符兩邊的值相乘a * b 將得到 200/除法 - 左操作數除以右操作數b / a 將得到 2%取模 - 左操作數除以右操作數后得到的余數b % a will give 0
比較運算符
| 運算符 | 描述 | 實例 |
|---|---|---|
| + | 加法 - 把運算符兩邊的值相加 | a + b 將得到 30 |
| - | 減法 - 左操作數減去右操作數 | a - b 將得到 -10 |
| * | 乘法 - 把運算符兩邊的值相乘 | a * b 將得到 200 |
| / | 除法 - 左操作數除以右操作數 | b / a 將得到 2 |
| % | 取模 - 左操作數除以右操作數后得到的余數 | b % a will give 0 |
邏輯運算符
| 運算符 | 描述 | 實例 |
|---|---|---|
| == | 檢查兩個操作數的值是否相等,如果相等則條件為真。 | (a == b) 不為真。 |
| = | 檢查兩個操作數的值是否相等,如果相等則條件為真。 | (a = b) 不為真。 |
| != | 檢查兩個操作數的值是否相等,如果不相等則條件為真。 | (a != b) 為真。 |
| <> | 檢查兩個操作數的值是否相等,如果不相等則條件為真。 | (a <> b) 為真。 |
| > | 檢查左操作數的值是否大于右操作數的值,如果是則條件為真。 | (a > b) 不為真。 |
| < | 檢查左操作數的值是否小于右操作數的值,如果是則條件為真。 | (a < b) 為真。 |
| >= | 檢查左操作數的值是否大于等于右操作數的值,如果是則條件為真。 | (a >= b) 不為真。 |
| <= | 檢查左操作數的值是否小于等于右操作數的值,如果是則條件為真。 | (a <= b) 為真。 |
| !< | 檢查左操作數的值是否不小于右操作數的值,如果是則條件為真。 | (a !< b) 為假。 |
| !> | 檢查左操作數的值是否不大于右操作數的值,如果是則條件為真。 | (a !> b) 為真。 |
位運算符
| p | q | p & q | p | q |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
下面直接上例子
我有COMPANY 表如下:
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
用 SELECT列出SALARY 大于 50,000.00 的所有記錄:
SELECT * FROM COMPANY WHERE SALARY > 50000;
輸出結果如下:

用 SELECT列出SALARY 等于的所有記錄:
SELECT * FROM COMPANY WHERE SALARY = 20000;
輸出結果如下:

用 SELECT列出AGE 大于等于 25 且SALARY大于等于 65000.00的所有記錄:
SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
輸出結果如下:

SQLite的 WHERE 子句用于指定從一個表或多個表中獲取數據的條件。如果滿足給定的條件,即為真(true)時,則從表中返回特定的值。您可以使用 WHERE 子句來過濾記錄,只獲取需要的記錄。WHERE 子句不僅可用在 SELECT 語句中,它也可用在 UPDATE、DELETE 語句中,等等。用例參考運算符。
SQLite中,刪除記錄表數據為DELETE語句,我們可以使用帶有 WHERE 子句的 DELETE。
語法如下:
DELETE FROM table_name WHERE [condition];
我們有以下記錄表:
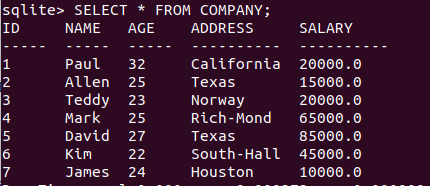
刪除ID為7的列:
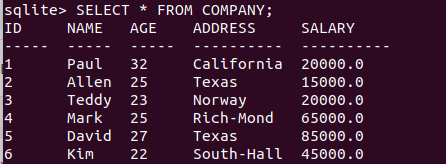
DELETE FROM COMPANY WHERE ID = 7;
再次輸出結果:
SQLite 的 UPDATE 查詢用于修改表中已有的記錄。可以使用帶有 WHERE 子句的 UPDATE 查詢來更新選定行,否則所有的行都會被更新。
語法:
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
注:這三行實為同一行。
現在我有數據表如下:
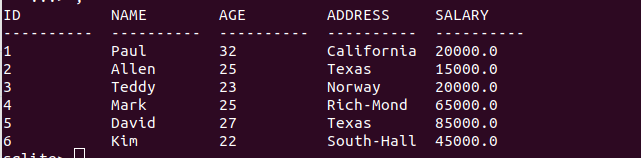
把COMPANY表中ID 為 6 的客戶地址改為Texas:
UPDATE COMPANY SET ADDRESS = 'Texas' WHERE ID = 6;
修改結果:

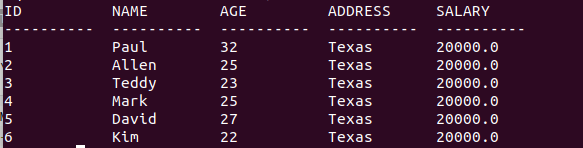
如果您想修改 COMPANY 表中 ADDRESS 和 SALARY 列的所有值,則不需要使用 WHERE 子句,UPDATE 查詢如下:
UPDATE COMPANY SET ADDRESS = 'Texas', SALARY = 20000.00;
修改結果:
下面接口能滿足我們的基本需求,需要學習更多的操作,我們可以參考官方文檔。
| 序號 | API & 描述 |
|---|---|
| 1 | sqlite3_open(const char *filename, sqlite3 **ppDb) 該例程打開一個指向 SQLite 數據庫文件的連接,返回一個用于其他 SQLite 程序的數據庫連接對象。 如果 filename 參數是 NULL 或 ':memory:',那么 sqlite3_open() 將會在 RAM 中創建一個內存數據庫,這只會在 session 的有效時間內持續。 如果文件名 filename 不為 NULL,那么 sqlite3_open() 將使用這個參數值嘗試打開數據庫文件。如果該名稱的文件不存在,sqlite3_open() 將創建一個新的命名為該名稱的數據庫文件并打開。 |
| 2 | sqlite3_exec(sqlite3*, const char *sql, sqlite_callback, void *data, char **errmsg) 該例程提供了一個執行 SQL 命令的快捷方式,SQL 命令由 sql 參數提供,可以由多個 SQL 命令組成。 在這里,第一個參數 sqlite3 是打開的數據庫對象,sqlite_callback 是一個回調,data 作為其第一個參數,errmsg 將被返回用來獲取程序生成的任何錯誤。 sqlite3_exec() 程序解析并執行由 sql 參數所給的每個命令,直到字符串結束或者遇到錯誤為止。 |
| 3 | sqlite3_close(sqlite3*) 該例程關閉之前調用 sqlite3_open() 打開的數據庫連接。所有與連接相關的語句都應在連接關閉之前完成。 如果還有查詢沒有完成,sqlite3_close() 將返回 SQLITE_BUSY 禁止關閉的錯誤消息。 |
下面的 C 代碼段顯示了如何連接到一個現有的數據庫。如果數據庫不存在,那么它就會被創建,最后將返回一個數據庫對象。
#include <stdio.h>
#include <sqlite3.h>
int main(int argc, char* argv[])
{
sqlite3 *db;
char *zErrMsg = 0;
int rc;
rc = sqlite3_open("test.db", &db);
if( rc ){
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}else{
fprintf(stderr, "Opened database successfully\n");
}
sqlite3_close(db);
}編譯命令
gcc lianjie.c -l sqlite3
運行結果

終端輸入ls -l命令發現多了個test.db文件,如圖:

C語言創建表與終端創建操作差不多,只不過命令由sqlite3_exec()函數的sql參數傳入。格式如下:
sql = "CREATE TABLE COMPANY(" \
"ID INT PRIMARY KEY NOT NULL," \
"NAME TEXT NOT NULL," \
"AGE INT NOT NULL," \
"ADDRESS CHAR(50)," \
"SALARY REAL );";示例代碼:
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>
static int callback(void *NotUsed, int argc, char **argv, char **azColName){
int i;
for(i=0; i<argc; i++){
printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
int main(int argc, char* argv[])
{
sqlite3 *db;
char *zErrMsg = 0;
int rc;
char *sql;
/* Open database */
rc = sqlite3_open("test.db", &db);
if( rc ){
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}else{
fprintf(stdout, "Opened database successfully\n");
}
/* Create SQL statement */
sql = "CREATE TABLE COMPANY(" \
"ID INT PRIMARY KEY NOT NULL," \
"NAME TEXT NOT NULL," \
"AGE INT NOT NULL," \
"ADDRESS CHAR(50)," \
"SALARY REAL );";
/* Execute SQL statement */
rc = sqlite3_exec(db, sql, callback, 0, &zErrMsg);
if( rc != SQLITE_OK ){
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}else{
fprintf(stdout, "Table created successfully\n");
}
sqlite3_close(db);
return 0;
}輸出結果:

再次ls -l:
我們可以看到,test.db文件大小明顯變大了。
與創建表類似,sql參數設為:
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \ "VALUES (1, 'Paul', 32, 'California', 20000.00 ); " \ "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \ "VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); " \ "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \ "VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );" \ "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \ "VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
示例代碼:
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>
static int callback(void *NotUsed, int argc, char **argv, char **azColName){
int i;
for(i=0; i<argc; i++){
printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
int main(int argc, char* argv[])
{
sqlite3 *db;
char *zErrMsg = 0;
int rc;
char *sql;
/* Open database */
rc = sqlite3_open("test.db", &db);
if( rc ){
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}else{
fprintf(stderr, "Opened database successfully\n");
}
/* Create SQL statement */
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (1, 'Paul', 32, 'California', 20000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );" \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
/* Execute SQL statement */
rc = sqlite3_exec(db, sql, callback, 0, &zErrMsg);
if( rc != SQLITE_OK ){
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}else{
fprintf(stdout, "Records created successfully\n");
}
sqlite3_close(db);
return 0;
}輸出結果:

sqlite3_exec()給我們提供了一個回調函數,其聲明如下:
typedef int (*sqlite3_callback)( void*, /* Data provided in the 4th argument of sqlite3_exec() */ int, /* The number of columns in row */ char**, /* An array of strings representing fields in the row */ char** /* An array of strings representing column names */ );
第一個參數:即第四個參數傳入的數據
第二個參數:行中的列數
第三個參數:表示行中字段的字符串數組,即各行中的數據
第四個參數:表示列名的字符串數組,創建鏈表時設置的
執行流程:查表,是否還有符合條件數據。有,執行sqlite3_callback()函數;沒有,退出
用法講完了,下面看例子:
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>
static int callback(void *data, int argc, char **argv, char **azColName){
int i;
fprintf(stderr, "%s: ", (const char*)data);
for(i=0; i<argc; i++){
printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
int main(int argc, char* argv[])
{
sqlite3 *db;
char *zErrMsg = 0;
int rc;
char *sql;
const char* data = "Callback function called";
/* Open database */
rc = sqlite3_open("test.db", &db);
if( rc ){
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}else{
fprintf(stderr, "Opened database successfully\n");
}
/* Create SQL statement */
sql = "SELECT * from COMPANY";
/* Execute SQL statement */
rc = sqlite3_exec(db, sql, callback, (void*)data, &zErrMsg);
if( rc != SQLITE_OK ){
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}else{
fprintf(stdout, "Operation done successfully\n");
}
sqlite3_close(db);
return 0;
}上面程序顯示了如何從前面創建的 COMPANY 表中獲取并顯示記錄,輸出結果如下:
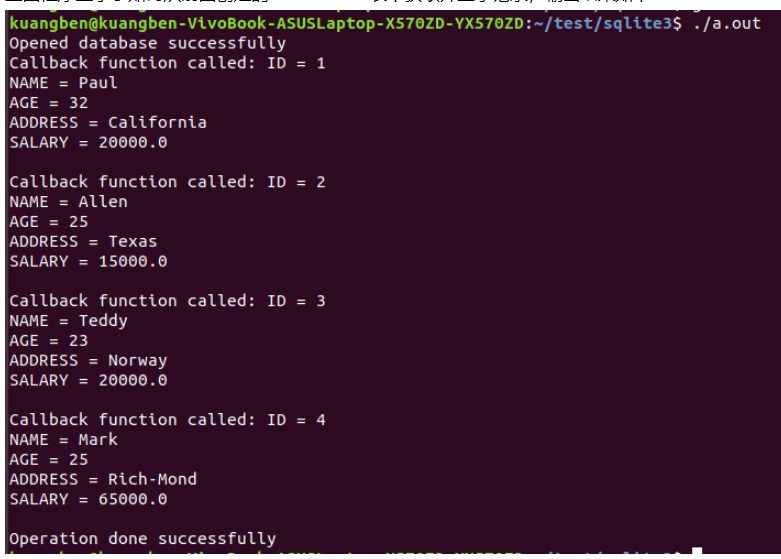
這里我沒有特殊指明查詢條件,表示查詢全部。
sql參數設置:
sql = "DELETE from COMPANY where ID=2; " \\刪除ID等于2的行 "SELECT * from COMPANY"; \\顯示表
這里跟上面不同的是多了一個命令,表面sql參數可由多個命令組成。
示例代碼:
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>
static int callback(void *data, int argc, char **argv, char **azColName){
int i;
fprintf(stderr, "%s: ", (const char*)data);
for(i=0; i<argc; i++){
printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
int main(int argc, char* argv[])
{
sqlite3 *db;
char *zErrMsg = 0;
int rc;
char *sql;
const char* data = "Callback function called";
/* Open database */
rc = sqlite3_open("test.db", &db);
if( rc ){
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}else{
fprintf(stderr, "Opened database successfully\n");
}
/* Create merged SQL statement */
sql = "DELETE from COMPANY where ID=2; " \
"SELECT * from COMPANY";
/* Execute SQL statement */
rc = sqlite3_exec(db, sql, callback, (void*)data, &zErrMsg);
if( rc != SQLITE_OK ){
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}else{
fprintf(stdout, "Operation done successfully\n");
}
sqlite3_close(db);
return 0;
}輸出:

操作示例:
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>
static int callback(void *data, int argc, char **argv, char **azColName){
int i;
fprintf(stderr, "%s: ", (const char*)data);
for(i=0; i<argc; i++){
printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
int main(int argc, char* argv[])
{
sqlite3 *db;
char *zErrMsg = 0;
int rc;
char *sql;
const char* data = "Callback function called";
/* Open database */
rc = sqlite3_open("test.db", &db);
if( rc ){
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}else{
fprintf(stderr, "Opened database successfully\n");
}
/* Create merged SQL statement */
sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1; " \
"SELECT * from COMPANY";
/* Execute SQL statement */
rc = sqlite3_exec(db, sql, callback, (void*)data, &zErrMsg);
if( rc != SQLITE_OK ){
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}else{
fprintf(stdout, "Operation done successfully\n");
}
sqlite3_close(db);
return 0;
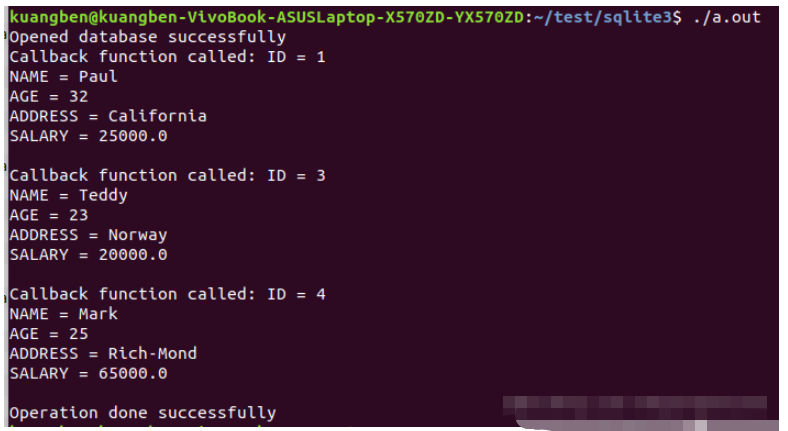
}輸出結果:
讀到這里,這篇“SQLite3基本使用方法有哪些”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





