溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了pandas的排序、分組groupby及cumsum累計求和的方法的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇pandas的排序、分組groupby及cumsum累計求和的方法文章都會有所收獲,下面我們一起來看看吧。
df['sum_age'] = df['age'].cumsum() print(df)
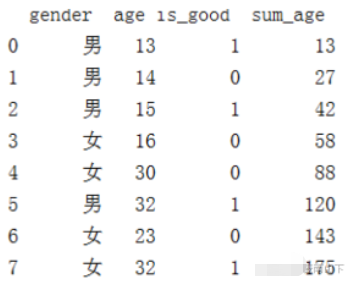
df['sum_age_new'] = df.groupby(['gender','is_good'])['age'].cumsum() print(df)

df['rank_g'] = df.groupby(['gender'])['age'].rank() print(df)
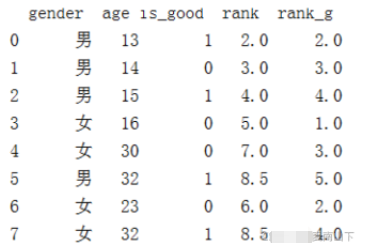
這里的 rank( ) 即 'rank_g' ,并不是按照1、2、3、4、、依次排
按照官方文檔的意思,該函數是沿著某個軸來計算數值數據等級(1到n)。默認情況下,為相等的值分配同一個等級,該等級是這些值的等級的平均值。
例子:
import pandas as pd obj = pd.Series([7,-5,7,4,2,0,4]) print(obj.rank())
代碼對 [7, -5, 7, 4, 2, 0, 4] 進行從小到大地排序,很明顯地,可以排成 [-5, 0, 2 ,4, 4, 7, 7],數值7有第6和第7兩個位置,那應該排序應該排到第幾級?根據官方文檔,取平均值,(6+7)/2=6.5,所以兩個7的等級都為6.5,同理可得兩個4的等級都為(4+5)/2=4.5。
輸出:
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
dtype: float64
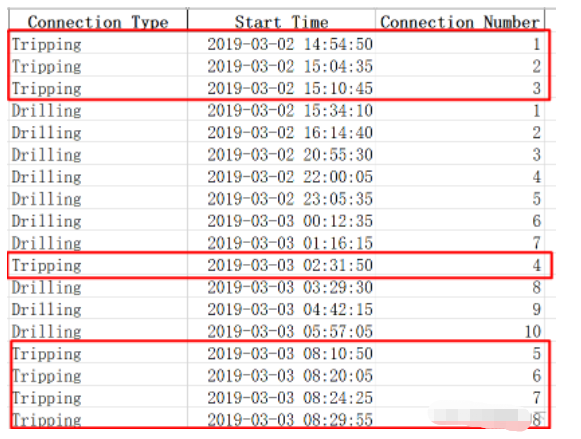
# 對Start Time進行排序,Connection Type分組,temp進行累計求和cumsum wsw_1 = wsw.sort_values(['Start Time']) wsw_1.loc[:, 'Connection Number'] = wsw_1.groupby(['Connection Type'])['temp'].cumsum()
這里如果不對start time排序,Connection Number不會按時間順序,統計drilling、tripping 的number數
在一個班級里,學生考試科目有語文、數學、英語,分別有對應的成績。
現在,想要列出每個科目班級的前五名的情況,要求包含科目、姓名、成績、名次。
通過以下代碼實現:
import pandas as pd
a=['小紅','小綠','小藍','小白','小青','小紫','小粉','小傻','小紅','小綠','小藍','小白','小青','小紫','小粉','小傻','小紅','小綠','小藍','小白','小青','小紫','小粉','小傻']
b=['語文','語文','語文','語文','語文','語文','語文','語文','數學','數學','數學','數學','數學','數學','數學','數學','英語','英語','英語','英語','英語','英語','英語','英語']
c=[97,65,23,43,67,23,55,98,56,45,67,78,98,45,87,65,67,23,55,98,56,45,67,78]
len(a),len(b),len(c)
df=pd.DataFrame({'name':a,'kemu':b,'score':c})
df2=df.sort_values(['kemu','score','name'], ascending=[1, 0,1])
df2['rn']=df2.groupby(['kemu']).rank(method='first',ascending =0)['score']
df2[df2['rn']<=5]
''''關于“pandas的排序、分組groupby及cumsum累計求和的方法”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“pandas的排序、分組groupby及cumsum累計求和的方法”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





