溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“C++內聯函數inline與auto關鍵字怎么使用”,在日常操作中,相信很多人在C++內聯函數inline與auto關鍵字怎么使用問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”C++內聯函數inline與auto關鍵字怎么使用”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
我們在使用C語言中我們都學過函數,我們知道函數在調用的過程中需要開辟棧幀。如果我們需要頻繁的調用一個函數,假設我們調用10次Add()函數,那我們就需要建立10次棧幀。我們都知道在棧幀中要做很多事情,例如保存寄存器,壓參數,壓返回值等等,這個過程是很麻煩的。那在C語言中,我們可以通過宏來解決這個問題。在C++中,我們便引入了內斂函數(inline)。
以inline修飾的函數叫做內聯函數,編譯時C++編譯器會在調用內聯函數的地方展開,沒有函數壓棧的開銷,內聯函數提升程序運行的效率。
我們這里依然使用Add()函數舉例。這段代碼是我們常寫的Add()函數。假設我們多次調用Add函數,在C語言中,我們可以使用宏替換。在C++我們可以在函數前加上inline
int Add(int x, int y)
{
int z = x + y;
return z;
}C語言中用宏來代替Add函數:
#define Add(x,y) ((x)+(y))
C++中在函數前加上inline使之成為內聯函數
inline int Add(int x, int y)
{
int z = x + y;
return z;
}那C語言已經有了宏替換,為什么C++還要出現內聯函數呢?
主要是有兩個原因:
1.宏晦澀難懂不好控制,特別容易寫錯.語法機制設計不好。
2.宏不支持調試,但是內斂在debug下支持調試(在debug下不會展開,在release下才會展開),這樣我們對代碼的理解和掌握將大大提高。
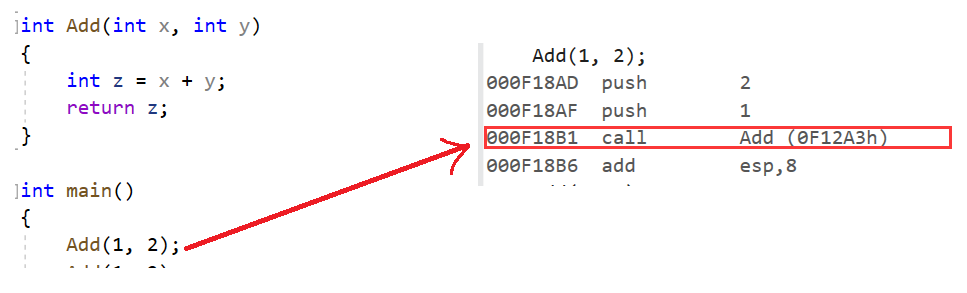
如果在Add函數前增加 inline 關鍵字將其改成內聯函數,在編譯期間編譯器會用函數體替換函數的調用。 查看方式:
1. 在 release 模式下,查看編譯器生成的匯編代碼中是否存在 call Add
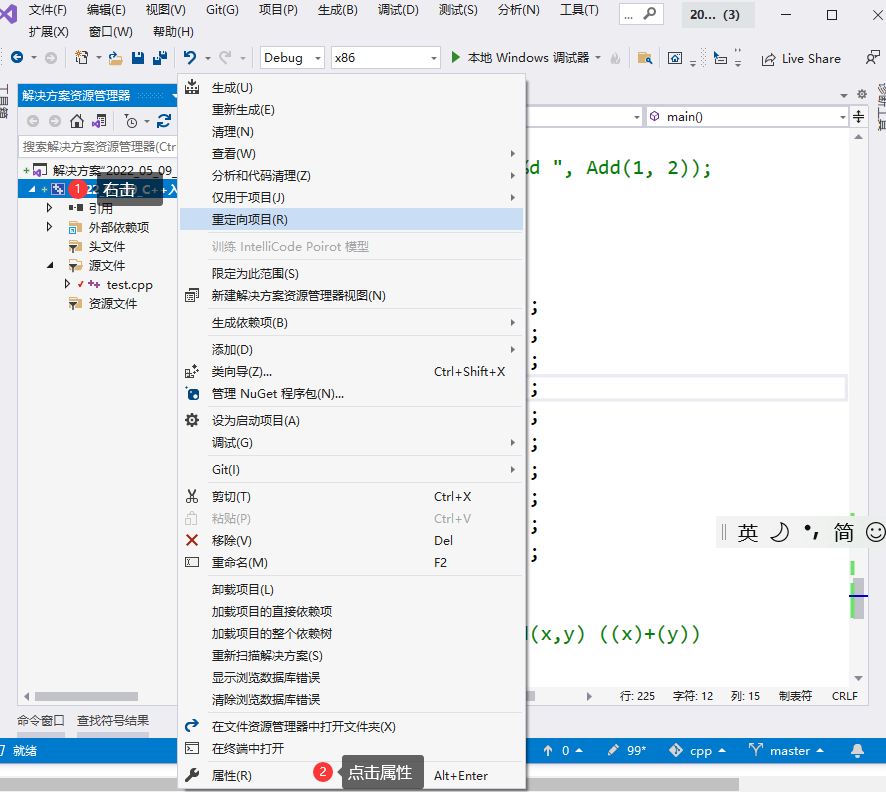
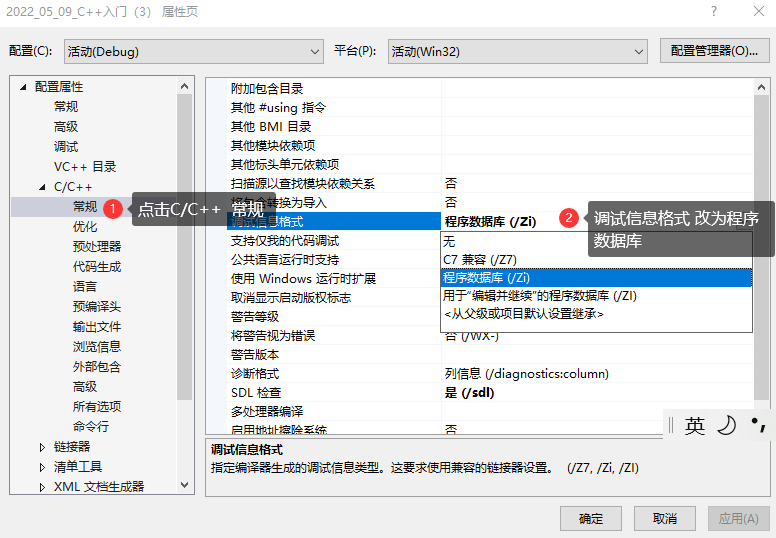
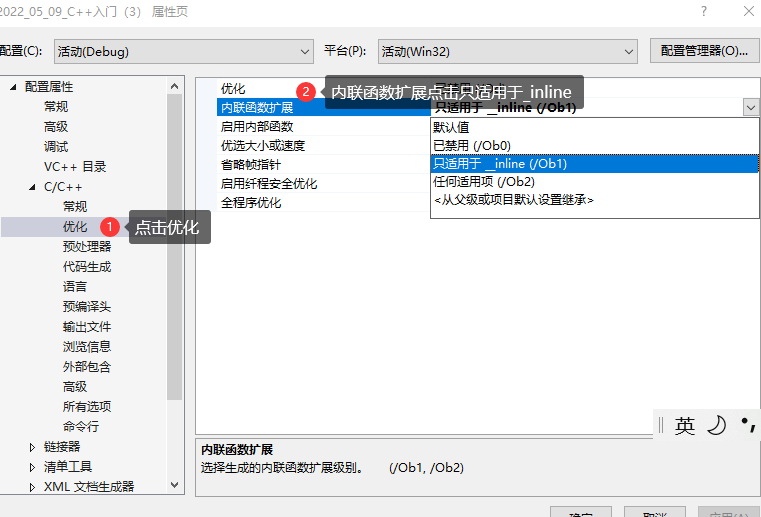
2. 在 debug 模式下,需要對編譯器進行設置,否則不會展開 ( 因為 debug 模式下,編譯器默認不會對代碼進 行優化,以下給出 vs2019 的設置方式 )
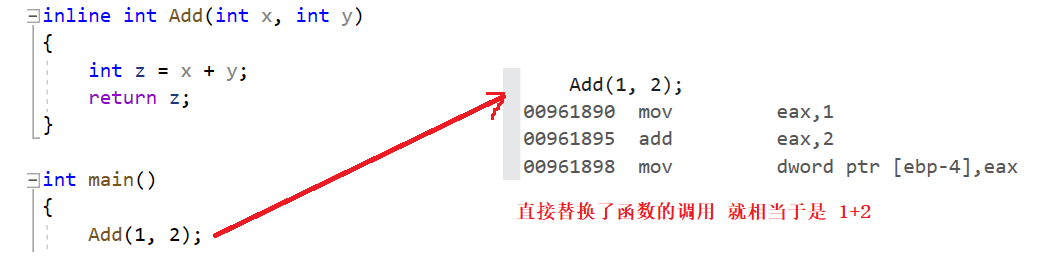
1. inline 是一種 以空間換時間 的做法,省去調用函數額開銷。所以 代碼很長 或者有 循環 / 遞歸 的函數不適宜使用作為內聯函數。
2. inline 對于編譯器而言只是一個建議 ,編譯器會自動優化,如果定義為 inline 的函數體內有循環 / 遞歸等等,編譯器優化時會忽略掉內聯。
3. inline 不建議聲明和定義分離,分離會導致鏈接錯誤。因為 inline 被展開,就沒有函數地址了,鏈接就會找不到
inline是一種以空間換時間的做法,省去調用函數額開銷(建立棧幀).所以代碼很長或者遞歸的函數不適宜用內聯函數.
這里代碼多長算長呢? 一般是10行左右,具體取決于編譯器。
inline對于編譯器而言只是一個建議,編譯器會自動優化,如果定義為inline的函數體內有循環/遞歸等等,編譯器優化時會忽略掉內聯。
這里可以舉個例子,假設我們有一個代碼需要10行,但是我們需要調用1000次。如果inline替換的話,我們要有1000*10條指令,如果不替換則有1000+10條指令。因此最終是否替換,取決于編譯器。
inline int Add(int x, int y)
{
int z = x + y;
z += x * y;
z += x * y;
z += x * y;
z += x * y;
z += x * y;
z += x * y;
z += x * y;
z += x * y;
z += x * y;
z += x * y;
z += x * y;
return z;
}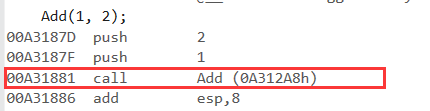
我們發現,雖然Add函數前加了inline,但是最終卻沒有展開。
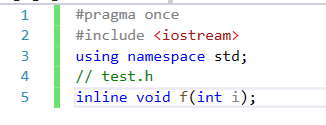
inline不建議聲明和定義分離,分離會導致鏈接錯誤。因為inline被展開,就沒有函數地址了,鏈接就會找不到
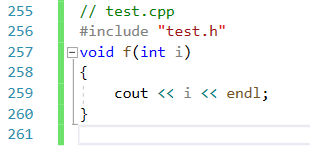
我們在f.cpp中調用一下:發現報錯了
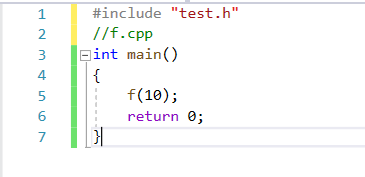
在這里他就會發生鏈接錯誤:

這是因為test.h中替換到test.cpp中發現是內聯函數,內聯函數不需要生成地址,因為內聯函數調用的地方都展開了,因此不會存在在符號表中。外部調用時就找不到。因此不要將聲明和定義分開。
在早期 C/C++ 中 auto 的含義是:使用 auto 修飾的變量,是具有自動存儲器的局部變量。C++11中,標準委員會賦予了auto 全新的含義即: auto 不再是一個存儲類型指示符,而是作為一個新的類型 指示符來指示編譯器, auto 聲明的變量必須由編譯器在編譯時期推導而得
auto在C語言中我們是接觸過的:最寬宏大量的關鍵字,由于局部變量默認都是auto修飾的,因此auto可以省略,這就導致auto常常被人忽略。那么在C++11中,auto進行了升級,有了新的功能--自動推導。(注意:auto新功能只是在C++11之后才有此功能)

那么auto是怎么自動推導呢?
我們可以使用typeid,來打印一個變量的類型。
int main()
{
const int a = 10;
auto b = &a;
auto c = 'a';
cout << typeid(b).name() << endl;//typeid可以打印一個變量的類型
cout << typeid(a).name() << endl;//typeid可以打印一個變量的類型
cout << typeid(c).name() << endl;//typeid可以打印一個變量的類型
return 0;
}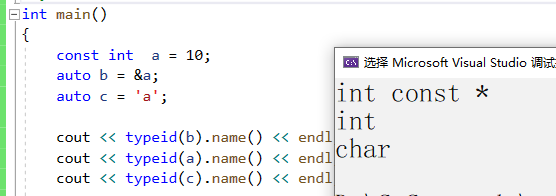
我們發現auto的自動推導還是很智能的。
auto意義之一:類型很長時,懶得寫,可以讓他自動推導
注意:
使用 auto 定義變量時必須對其進行初始化,在編譯階段編譯器需要根據初始化表達式來推導 auto 的實際類 型 。因此 auto 并非是一種 “ 類型 ” 的聲明,而是一個類型聲明時的 “ 占位符 ” ,編譯器在編譯期會將 auto 替換為 變量實際的類型 。
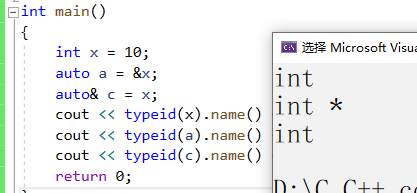
1. auto與指針和引用結合起來使用auto聲明指針類型時,用auto和auto*沒有任何區別,但用auto聲明引用類型時則必須加&.
int main()
{
int x = 10;
auto a = &x;
auto& c = x;
cout << typeid(x).name() << endl;//typeid可以打印一個變量的類型
cout << typeid(a).name() << endl;//typeid可以打印一個變量的類型
cout << typeid(c).name() << endl;//typeid可以打印一個變量的類型
return 0;
}
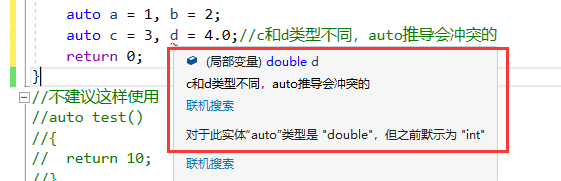
2. 在同一行定義多個變量當在同一行聲明多個變量時,這些變量必須是相同的類型,否則編譯器將會報錯,因為編譯器實際只對第一個類型進行推導,然后用推導出來的類型定義其他變量。
auto a = 1, b = 2; auto c = 3, d = 4.0;//c和d類型不同,auto推導會沖突的
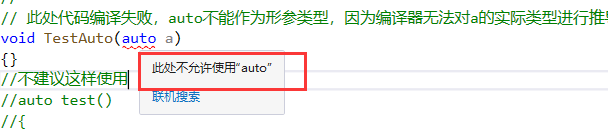
1. auto不能作為函數的參數
// 此處代碼編譯失敗,auto不能作為形參類型,因為編譯器無法對a的實際類型進行推導
void TestAuto(auto a)
{}
2. auto不能直接用來聲明數組
void TestAuto()
{
int a[] = { 1,2,3 };
auto b[] = { 4,5,6 };
}
在平常我們打印一個array數組,我們需要依次打印遍歷。如下代碼所示:
int main()
{
int array[] = { 1,2,3,4,5 };
for (int i = 0; i < sizeof(array) / sizeof(int); ++i)
array[i] *= 2;
for (int i = 0; i < sizeof(array) / sizeof(int); ++i)
cout << array[i] << " ";
cout << endl;
return 0;
}
我們也可以使用auto結合范圍for循環打印這個數組:
for (auto e : array) cout << e << " "; cout << endl;
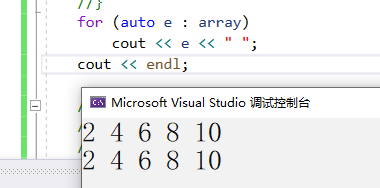
在這里我們使用到了一個新的for循環,范圍for。它會依次自動取array中的數據,賦值給e,并且會自動判斷結束,因此我們使用auto可以自動識別數組元素的類型。
注意:e只是array的拷貝,改變e不會改變array數組的內容。如果我們想改變array的內容,只需要加個引用即可,意思是讓e成為array的別名,代碼如下:
//加個引用就可以訪問到array
for (auto& e : array)
{
e /= 2;
}
for (auto e : array)
cout << e << " ";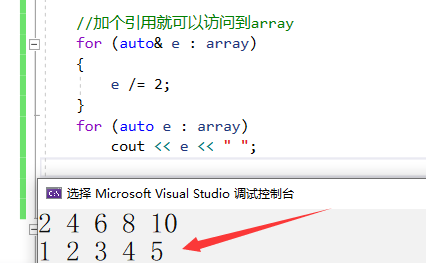
到此,關于“C++內聯函數inline與auto關鍵字怎么使用”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





