溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“怎么用node抓取小說章節”,內容詳細,步驟清晰,細節處理妥當,希望這篇“怎么用node抓取小說章節”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。

準備用electron制作一個小說閱讀工具練練手,那么首先要解決的就是數據問題,也就是小說的文本。
這里準備使用nodejs對小說網站進行爬蟲爬取,嘗試爬下一本小說,數據就不存放數據庫了,先使用txt作為文本存儲
在node中對于網站的請求,本身就存在http和https庫,內部含有request請求方法。
實例:
request = https.request(TestUrl, { encoding:'utf-8' }, (res)=>{
let chunks = ''
res.on('data', (chunk)=>{
chunks += chunk
})
res.on('end',function(){
console.log('請求結束');
})
})但是也就到此為止了,只是存取了一個html的文本數據,并不能夠對內部元素進行提取之類的工作(也可以正則拿,但是太過復雜)。
我將訪問到的數據通過fs.writeFile方法存儲起來了,這只是整個網頁的html
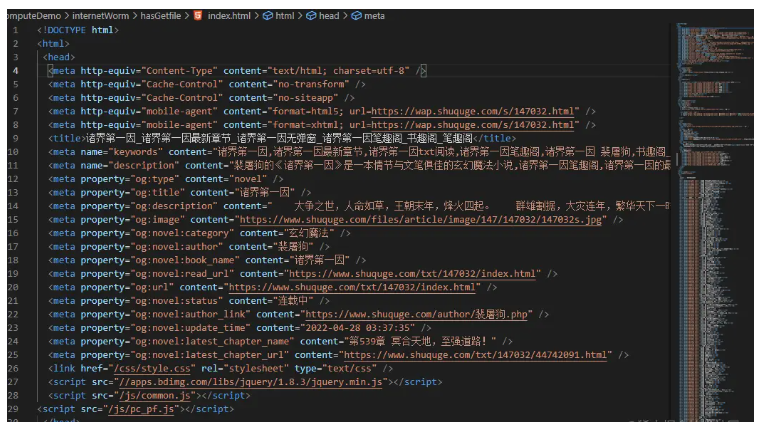
但是我想要的還有各個章節中的內容,這樣一來就需要獲取章節的超鏈接,組成超鏈接鏈表進去爬取
在文檔中,可以使用示例進行調試
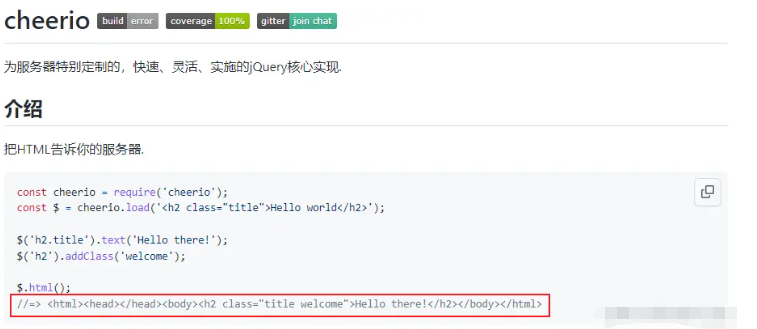
cheerio解析html時,獲取dom節點的方式與jquery相似。
根據之前獲取到的書籍首頁的html,查找自己想要的dom節點數據
const fs = require('fs')
const cheerio = require('cheerio');
// 引入讀取方法
const { getFile, writeFun } = require('./requestNovel')
let hasIndexPromise = getFile('./hasGetfile/index.html');
let bookArray = [];
hasIndexPromise.then((res)=>{
let htmlstr = res;
let $ = cheerio.load(htmlstr);
$(".listmain dl dd a").map((index, item)=>{
let name = $(item).text(), href = 'https://www.shuquge.com/txt/147032/' + $(item).attr('href')
if (index > 11){
bookArray.push({ name, href })
}
})
// console.log(bookArray)
writeFun('./hasGetfile/hrefList.txt', JSON.stringify(bookArray), 'w')
})打印一下信息
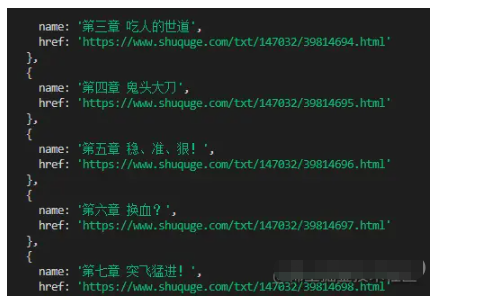
可以同時將這些信息也存儲起來
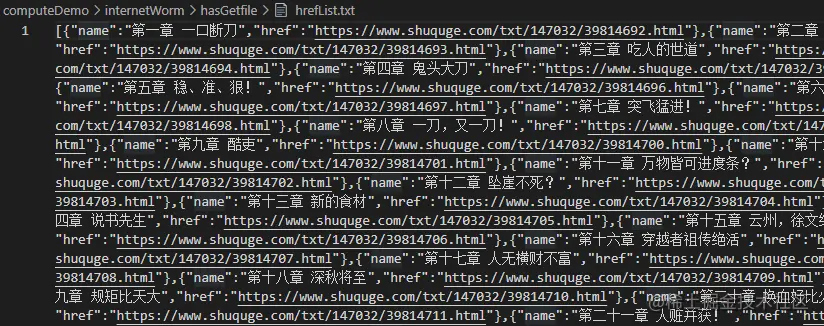
現在章節數和章節的鏈接都有了,那么就可以獲取章節的內容了。
因為批量爬取最后需要IP代理,這里還沒準備,暫時先寫獲取某一章節小說的內容方法
爬取某一章節的內容其實也比較簡單:
// 爬取某一章節的內容方法
function getOneChapter(n) {
return new Promise((resolve, reject)=>{
if (n >= bookArray.length) {
reject('未能找到')
}
let name = bookArray[n].name;
request = https.request(bookArray[n].href, { encoding:'gbk' }, (res)=>{
let html = ''
res.on('data', chunk=>{
html += chunk;
})
res.on('end', ()=>{
let $ = cheerio.load(html);
let content = $("#content").text();
if (content) {
// 寫成txt
writeFun(`./hasGetfile/${name}.txt`, content, 'w')
resolve(content);
} else {
reject('未能找到')
}
})
})
request.end();
})
}
getOneChapter(10)
這樣,就可以根據上面的方法,來創造一個調用接口,傳入不同的章節參數,獲取當前章節的數據
const express = require('express');
const IO = express();
const { getAllChapter, getOneChapter } = require('./readIndex')
// 獲取章節超鏈接鏈表
getAllChapter();
IO.use('/book',function(req, res) {
// 參數
let query = req.query;
if (query.n) {
// 獲取某一章節數據
let promise = getOneChapter(parseInt(query.n - 1));
promise.then((d)=>{
res.json({ d: d })
}, (d)=>{
res.json({ d: d })
})
} else {
res.json({ d: 404 })
}
})
//服務器本地主機的數字
IO.listen('7001',function(){
console.log("啟動了。。。");
})讀到這里,這篇“怎么用node抓取小說章節”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





