溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“MySQL索引的語法是什么”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“MySQL索引的語法是什么”文章能幫助大家解決問題。

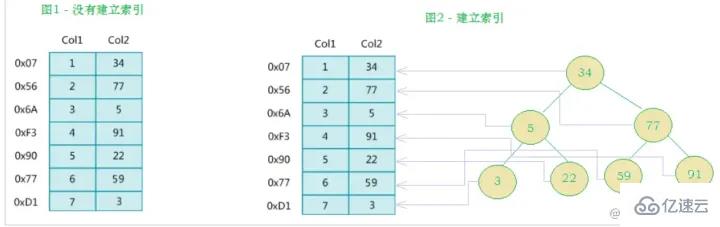
MySQL官方對索引的定義為:索引(index)是幫助MySQL高效獲取數據的數據結構(有序)。索引是在數據庫表的字段上添加的,是為了提高查詢效率存在的一種機制。除了數據之外,數據庫系統還維護著滿足特定查找算法的數據結構,這些數據結構以某種方式引用(指向)數據, 這樣就可以在這些數據結構上實現高級查找算法,這種數據結構就是索引。如下面的示意圖所示 :
其實簡單來說,索引就是一個排好序的數據結構
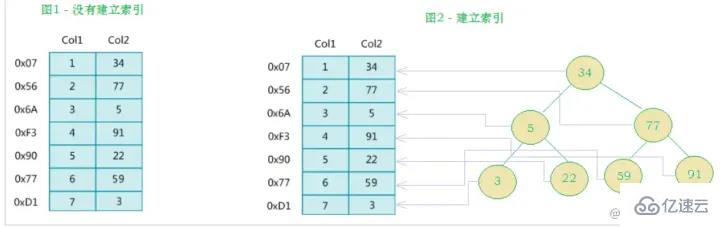
左邊是數據表,一共有兩列七條記錄,最左邊的是數據記錄的物理地址(注意邏輯上相鄰的記錄在磁盤上也并不是一定物理相鄰的)。為了加快Col2的查找,可以維護一個右邊所示的二叉查找樹,每個節點分別包含索引鍵值和一個指向對應數據記錄物理地址的指針,這樣就可以運用二叉查找快速獲取到相應數據。
加快查找和排序的速率,降低數據庫的IO成本以及CPU的消耗
通過創建唯一性索引,可以保證數據庫表中每一行數據的唯一性。
索引實際上也是一張表,保存了主鍵和索引字段,并指向實體類的記錄,本身需要占用空間
雖然增加了查詢效率,但對于增刪改,每次改動表,還需要更新一下索引 新增:自然需要在索引樹中新增節點 刪除:索引樹中指向的記錄可能會失效,意味著這棵索引樹很多節點,都是失效的 改動:索引樹中節點的指向可能需要改變
但實際上呢,我們MySQL中并不是用二叉查找樹來存儲,為何呢?
要知道,二叉查找樹,此處一個節點只能存儲一條數據,而一個節點呢,在MySQL里邊又對應一個磁盤塊,這樣我們每次讀取一個磁盤塊,只能獲取一條數據,效率特別的低,所以我們會想到采用B樹這種結構來存儲。
索引是在MySQL的存儲引擎層中實現的,而不是在服務器層實現的。所以每種存儲引擎的索引都不一定完全相同,而且也不是所有的引擎都支持所有的索引類型。
BTREE 索引 : 最常見的索引類型,大部分索引都支持 B 樹索引。
HASH 索引:只有Memory引擎支持 , 使用場景簡單 。
R-tree 索引(空間索引):空間索引是MyISAM引擎的一個特殊索引類型,主要用于地理空間數據類型,通常使用較少,不做特別介紹。
Full-text (全文索引) :全文索引也是MyISAM的一個特殊索引類型,主要用于全文索引,InnoDB從Mysql5.6版本開始支持全文索引。
MyISAM、InnoDB、Memory三種存儲引擎對各種索引類型的支持
索引 | INNODB引擎 | MYISAM引擎 | MEMORY引擎 |
BTREE索引 | 支持 | 支持 | 支持 |
HASH 索引 | 不支持 | 不支持 | 支持 |
R-tree 索引 | 不支持 | 支持 | 不支持 |
Full-text | 5.6版本之后支持 | 支持 | 不支持 |
我們平常所說的索引,如果沒有特別指明,都是指B+樹(多路搜索樹,并不一定是二叉的)結構組織的索引。其中聚集索引、復合索引、前綴索引、唯一索引默認都是使用 B+tree 索引,統稱為 索引。
多路平衡搜索樹,一棵m階(m叉)BTREE滿足:
每個節點最多m個孩子 孩子個數:ceil(m/2) 到 m 關鍵字個數:ceil(m/2)-1 到 m-1
ceil表示向上取整,ceil(2.3)=3

由于3階,最多只能2個節點,所以一開始26和30在一起,之后再來個85就要開始分裂了,30作為中間上位,26保持,85去到右邊
即:中間位置上位,然后左邊留在舊節點,右邊去到新結點
如圖中的70再插入的時候,70剛好是中間位置上位,然后62保持,85又去分一個新節點出來
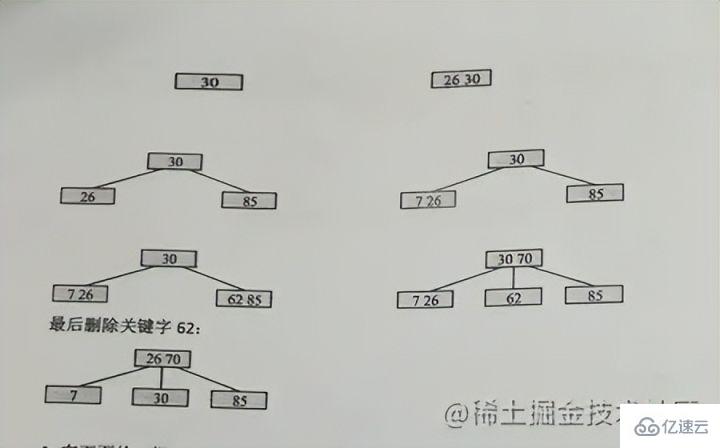
繼續向上分裂即可,同理的
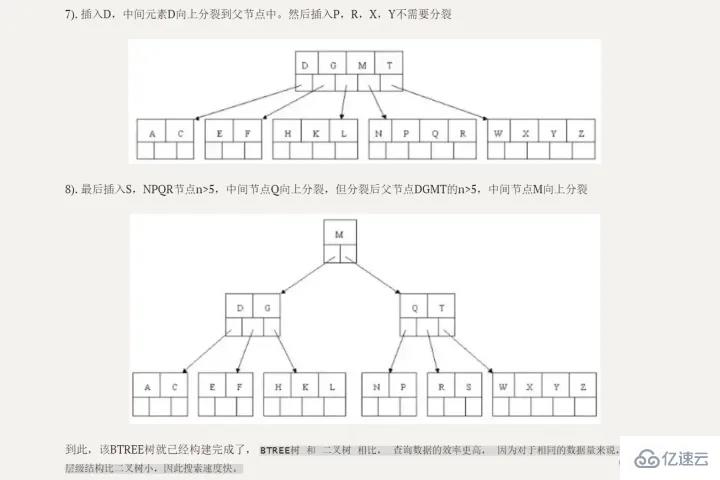
相比二叉搜索樹,高度/深度更低,自然查詢效率更高。
B+樹有兩種類型的節點:內部結點(也稱索引結點)和葉子結點。內部節點就是非葉子節點,內部節點不存儲數據,只存儲索引,數據都存儲在葉子節點。
內部結點中的key都按照從小到大的順序排列,對于內部結點中的一個key,左樹中的所有key都小于它,右子樹中的key都大于等于它。葉子結點中的記錄也按照key的大小排列。
每個葉子結點都存有相鄰葉子結點的指針,葉子結點本身依關鍵字的大小自小而大順序連接。
父節點存有右孩子的第一個元素的索引。

B+Tree的查詢效率更加穩定。由于B+Tree只有葉子節點保存key信息,查詢任何key都要從root走到葉子,所以更穩定。
只需遍歷葉子節點,就可以實現整棵樹的遍歷。
MySql索引數據結構對經典的B+Tree進行了優化。在原B+Tree的基礎上,增加一個指向相鄰葉子節點的鏈表指針(整體類似一個雙向鏈表的結構),就形成了帶有順序指針的B+Tree,提高區間訪問的性能。
細心的同學可以看出,這張圖跟我們的二叉查找樹簡圖的一個最大區別是什么?
從二叉查找樹過渡到B樹,有一個顯著的變化就是,一個節點可以存儲多個數據了,相當于一個磁盤塊里邊可以存儲多個數據,大大減少了我們的 IO次數!!
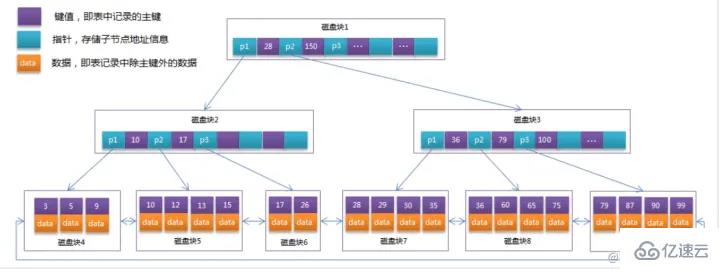
MySQL中的 B+Tree 索引結構示意圖:
二叉查找樹簡圖:
淺藍色的稱之為一個磁盤塊,可以看到每個磁盤塊包含幾個數據項(深藍色所示)和指針(黃色所示)
如磁盤塊1包含數據項17和35,包含指針P1、P2、P3,
P1表示小于17的磁盤塊,P2表示在17和35之間的磁盤塊,P3表示大于35的磁盤塊。
真實的數據存在于葉子節點即3、5、9、10、13、15、28、29、36、60、75、79、90、99。`
非葉子節點不存儲真實的數據,只存儲指引搜索方向的數據項,如17、35并不真實存在于數據表中。`
如果要查找數據項29,那么首先會把磁盤塊1由磁盤加載到內存,此時發生一次IO。在內存中用二分查找確定29在17和35之間,鎖定磁盤塊1的P2指針,內存時間因為非常短(相比磁盤的IO)可以忽略不計,通過磁盤塊1的P2指針的磁盤地址把磁盤塊3由磁盤加載到內存,發生第二次IO,29在26和30之間,鎖定磁盤塊3的P2指針,通過指針加載磁盤塊8到內存,發生第三次IO,同時內存中通過二分查找搜索到29,結束查詢,總計三次IO。
真實的情況是,3層的B+樹可以表示上百萬的數據,如果上百萬的數據查找只需要三次IO,性能提高將是巨大的,如果沒有索引,每個數據項都要發生一次IO,那么總共需要百萬次的IO,顯然成本非常非常高。
在InnoDB中,表都是根據主鍵順序以索引的形式存放的,這種存儲方式的表稱為索引組織表。又因為前面我們提到的,InnoDB使用了B+樹索引模型,所以數據都是存儲在B+樹中的。
每一個索引在InnoDB里面對應一棵B+樹。
假設,我們有一個主鍵列為ID的表,表中有字段k,并且在k上有索引。
這個表的建表語句是:
mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB; 復制代碼
表中R1~R5的(ID,k)值分別為(100,1)、(200,2)、(300,3)、(500,5)和(600,6),兩棵樹的示例示意圖如下:
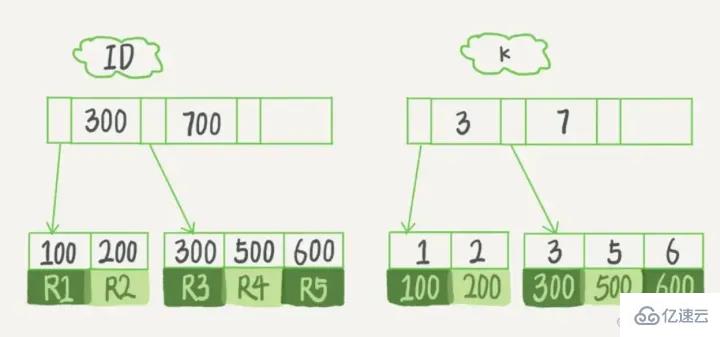
從圖中不難看出,根據葉子節點的內容,索引類型分為主鍵索引和非主鍵索引。
數據表的主鍵列使用的就是主鍵索引,且會默認創建,這也是為什么,我們還沒學索引的時候,老師經常跟我們說根據主鍵查會快一點,原來主鍵本身就建好了索引。
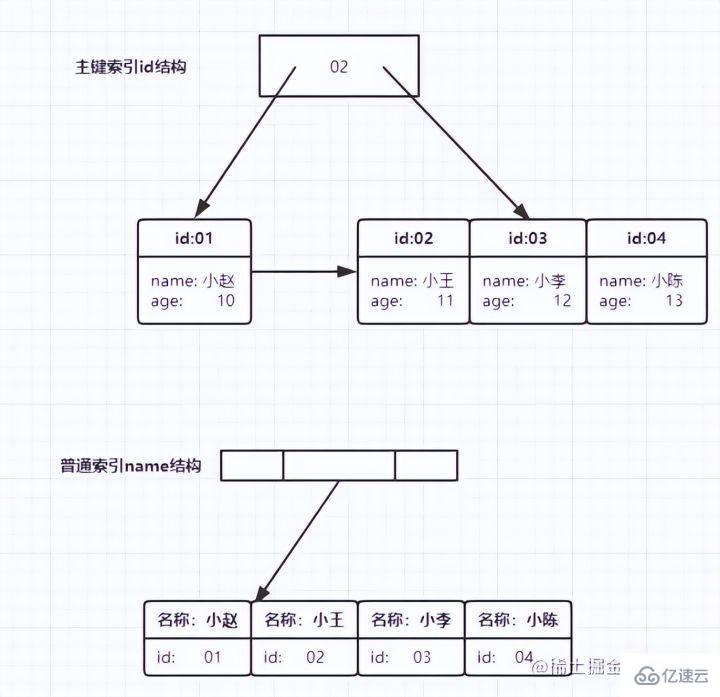
主鍵索引的葉子節點存的是整行數據。在InnoDB里,主鍵索引也被稱為聚簇索引(clustered index)。
輔助索引的葉子節點內容是主鍵的值。在InnoDB里,輔助索引也被稱為二級索引(secondary index)。
如下圖:
主鍵索引存放了整行數據
輔助索引只存放了自己本身,以及id主鍵用于回表查詢
根據上面的索引結構,我們來討論一個問題:基于主鍵索引和輔助索引的查詢有什么區別?
如果語句是select * from T where ID=500,即主鍵查詢方式,則只需要搜索ID這棵B+樹;
如果語句是select * from T where k=5,即普通索引查詢方式,則需要先搜索k索引樹,得到ID的值為500,再到ID索引樹搜索一次。這個過程稱為回表。
也就是說,基于輔助索引的查詢需要多掃描一棵索引樹。因此,我們在應用中應當盡量使用主鍵查詢。
除非說,我們所要查詢的數據,剛好就是我們索引樹上存在的,此時我們稱之為覆蓋索引--即索引列中包含了我們要查詢的所有數據。
同時,二級索引又分為了如下幾種(先簡單略過即可,后續我們再慢慢了解):
唯一索引(Unique Key) :唯一索引也是一種約束。唯一索引的屬性列不能出現重復的數據,但是允許數據為 NULL,一張表允許創建多個唯一索引。 建立唯一索引的目的大部分時候都是為了該屬性列的數據的唯一性,而不是為了查詢效率。
普通索引(Index) :普通索引的唯一作用就是為了快速查詢數據,一張表允許創建多個普通索引,并允許數據重復和 NULL。
前綴索引(Prefix) :前綴索引只適用于字符串類型的數據。前綴索引是對文本的前幾個字符創建索引,相比普通索引建立的數據更小, 因為只取前幾個字符。
全文索引(Full Text) :全文索引主要是為了檢索大文本數據中的關鍵字的信息,是目前搜索引擎數據庫使用的一種技術。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引
所謂下推,顧名思義,其實是推遲我們的回表操作,MySQL不會輕而易舉讓我們去回表,因為很浪費。什么意思呢?來看下邊這個例子。
我們建立了一個復合索引(name,status,address),索引中也是按這個字段來存儲的,類似圖中這樣:
復合索引樹(只存儲索引列和主鍵用于回表)
name | status | address | id(主鍵) |
小米1 | 0 | 1 | 1 |
小米2 | 1 | 1 | 2 |
我們執行這樣一條語句:
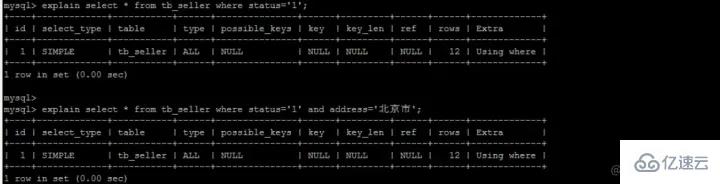
SELECT name FROM tb_seller WHERE name like '小米%' and status ='1' ; 復制代碼
首先我們在復合索引樹上,找到了第一個以小米開頭的name -- 小米1
此時我們不著急回表(回到主鍵索引樹搜索的過程,我們稱為回表),而是先在復合索引樹判斷status是否=1,此時status=0,我們直接就不回表了,直接繼續找下一個以小米開頭的name
找到第二個-- 小米2,判斷status=1,則根據id=2去主鍵索引樹上找,得到所有的數據
這種先在自身索引樹上判斷是否滿足其他的where條件,不滿足則直接pass掉,不進行回表的操作,就叫做索引下推。
所謂最左前綴,可以想象成一個爬樓梯的過程,假設我們有一個復合索引:name,status,address,那這個樓梯由低到高依次順序是:name,status,address,最左前綴,要求我們不能出現跳躍樓梯的情況,否則會導致我們的索引失效:
按樓梯從低到高,無出現跳躍的情況--此時符合最左前綴原則,索引不會失效

出現跳躍的情況
直接第一層name都不走,當然都失效
走了第一層,但是后續直接第三層,只有出現跳躍情況前的不會失效(此處就只有name成功)

同時,這個順序并不是由我們where中的排列順序決定,比如: where name='小米科技' and status='1' and address='北京市' where status='1' and name='小米科技' and address='北京市'
這兩個盡管where中字段的順序不一樣,第二個看起來越級了,但實際上效果是一樣的
其實是因為我們MySQL有一個Optimizer(查詢優化器),查詢優化器會將SQL進行優化,選擇最優的查詢計劃來執行。
關于這個查詢優化器,后續文章我們也會談談MySQL的邏輯架構與存儲引擎
查詢頻次高,且數據量多的表
最好從where子句的條件中提取,如果where子句中的組合比較多,那么應當挑選最常用、過濾效果最好的列的組合。
最好用唯一索引,區分度越高,使用索引的效率越高
不是越多越好,維護也需要時間和空間代價,建議單張表索引不超過 5 個
因為 MySQL 優化器在選擇如何優化查詢時,會根據統一信息,對每一個可以用到的索引來進行評估,以生成出一個最好的執行計劃,如果同時有很多個索引都可以用于查詢,就會增加 MySQL 優化器生成執行計劃的時間,同樣會降低查詢性能。
比如:
我們創建了三個單列索引,name,status,address
當我們where中根據status和address兩個字段來查詢時,數據庫只會選擇最優的一個索引,不會所有單列索引都使用。
最優的索引:具體是指所查詢表中,辨識度最高(所占比例最少)的索引列,比如此處address中有一個辨識度很高的 '西安市'數據;
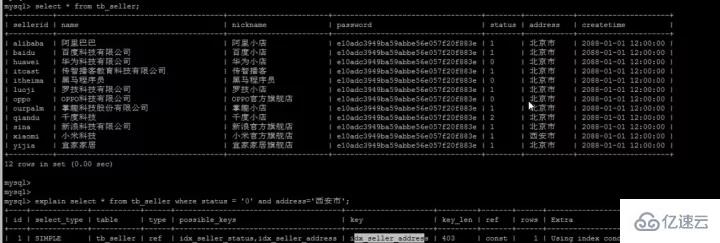
使用短索引,索引創建之后也是使用硬盤來存儲的,因此提升索引訪問的I/O效率,也可以提升總體的訪問效率。假如構成索引的字段總長度比較短,那么在給定大小的存儲塊內可以存儲更多的索引值,相應的可以有效的提升MySQL訪問索引的I/O效率。
利用最左前綴,比如有N個字段,我們不一定需要創建N個索引,可以用復合索引
也就是說,我們盡量創建復合索引,而不是單列索引
創建復合索引: CREATE INDEX idx_name_email_status ON tb_seller(name,email,status); 就相當于 對name 創建索引 ; 對name , email 創建了索引 ; 對name , email, status 創建了索引 ; 復制代碼
假設我們有這么一個表,id為主鍵,沒有創建索引:
CREATE TABLE `tuser` ( `id` int(11) NOT NULL, `name` varchar(32) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`), ) ENGINE=InnoDB 復制代碼
如果要在此處建立復合索引,我們要遵循什么原則呢?
比如我們的業務需求里邊,有如下兩種查詢方式: 根據name查詢 根據name和age查詢
如果我們建立索引(age,name),由于最左前綴原則,我們這個索引能實現的是根據age,根據age和name查詢,并不能單純根據name查詢(因為跳躍了),為了實現我們的需求,我們還得再建立一個name索引;
而如果我們通過調整順序,改成(name,age),就能實現我們的需求了,無需再維護一個name索引,這就是通過調整順序,可以少維護一個索引。
比如我們的業務需求里邊,有以下兩種查詢方式: 根據name查詢 根據age查詢 根據name和age查詢
我們有兩種方案:
建立聯合索引(name,age),建立單列索引:age索引。
建立聯合索引(age,name),建立單列索引:name索引。
這兩種方案都能實現我們的需求,這個時候我們就要考慮空間了,name字段是比age字段大的,顯然方案1所耗費的空間是更小的,所以我們更傾向于方案1。
where中的查詢字段
查詢中與其他表關聯的字段,比如外鍵
排序的字段
統計或分組的字段
表中數據量很少
經常改動的表
頻繁更新的字段
數據重復且分布均勻的表字段(比如包含了很多重復數據,那此時多叉樹的二分查找,其實用處不大,可以理解為O(logn)退化了)
默認會為主鍵創建索引--primary
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name(index_col_name,...) index_col_name : column_name[(length)][ASC | DESC] 復制代碼
結尾加上\G,可以變成豎屏顯示
select index from tbl_name\G; 復制代碼
drop INDEX index_name on tbl_name ; 復制代碼
1). alter table tb_name add primary key(column_list); 該語句添加一個主鍵,這意味著索引值必須是唯一的,且不能為NULL 2). alter table tb_name add unique index_name(column_list); 這條語句創建索引的值必須是唯一的(除了NULL外,NULL可能會出現多次) 3). alter table tb_name add index index_name(column_list); 添加普通索引, 索引值可以出現多次。 4). alter table tb_name add fulltext index_name(column_list); 該語句指定了索引為FULLTEXT, 用于全文索引 復制代碼
show status like 'Handler_read%'; -- 查看當前會話索引使用情況 show global status like 'Handler_read%'; -- 查看全局索引使用情況 復制代碼
Handler_read_first:索引中第一條被讀的次數。如果較高,表示服務器正執行大量全索引掃描(這個值越低越好)。
Handler_read_key:如果索引正在工作,這個值代表一個行被索引值讀的次數,如果值越低,表示索引得到的性能改善不高,因為索引不經常使用(這個值越高越好)。
Handler_read_next :按照鍵順序讀下一行的請求數。如果你用范圍約束或如果執行索引掃描來查詢索引列,該值增加。
Handler_read_prev:按照鍵順序讀前一行的請求數。該讀方法主要用于優化ORDER BY ... DESC。
Handler_read_rnd :根據固定位置讀一行的請求數。如果你正執行大量查詢并需要對結果進行排序該值較高。你可能使用了大量需要MySQL掃描整個表的查詢或你的連接沒有正確使用鍵。這個值較高,意味著運行效率低,應該建立索引來補救。
Handler_read_rnd_next:在數據文件中讀下一行的請求數。如果你正進行大量的表掃描,該值較高。通常說明你的表索引不正確或寫入的查詢沒有利用索引。
關于“MySQL索引的語法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





