溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Go實現線程池的兩種方式是什么”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Go實現線程池的兩種方式是什么”文章吧。
worker pool其實就是線程池thread pool。對于go來說,直接使用的是goroutine而非線程,不過這里仍然以線程來解釋線程池。
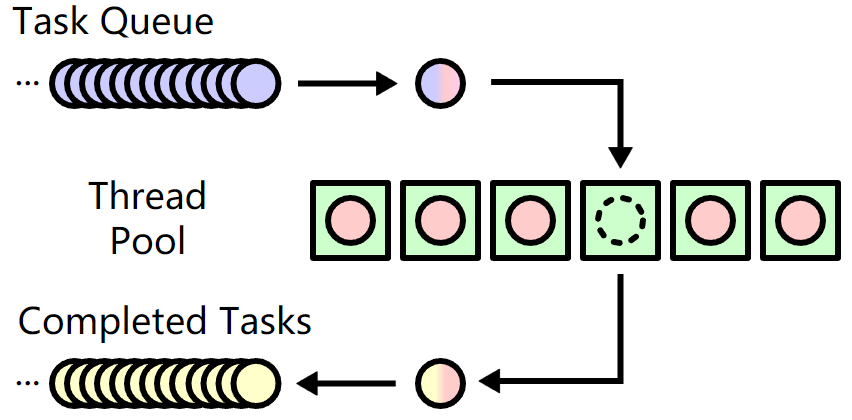
在線程池模型中,有2個隊列一個池子:任務隊列、已完成任務隊列和線程池。其中已完成任務隊列可能存在也可能不存在,依據實際需求而定。
只要有任務進來,就會放進任務隊列中。只要線程執行完了一個任務,就將任務放進已完成任務隊列,有時候還會將任務的處理結果也放進已完成隊列中。
worker pool中包含了一堆的線程(worker,對go而言每個worker就是一個goroutine),這些線程嗷嗷待哺,等待著為它們分配任務,或者自己去任務隊列中取任務。取得任務后更新任務隊列,然后執行任務,并將執行完成的任務放進已完成隊列。
下圖來自wiki:
在Go中有兩種方式可以實現工作池:傳統的互斥鎖、channel。
假設Go中的任務的定義形式為:
type Task struct {
...
}每次有任務進來時,都將任務放在任務隊列中。
使用傳統的互斥鎖方式實現,任務隊列的定義結構大概如下:
type Queue struct{
M sync.Mutex
Tasks []Task
}然后在執行任務的函數中加上Lock()和Unlock()。例如:
func Worker(queue *Queue) {
for {
// Lock()和Unlock()之間的是critical section
queue.M.Lock()
// 取出任務
task := queue.Tasks[0]
// 更新任務隊列
queue.Tasks = queue.Tasks[1:]
queue.M.Unlock()
// 在此goroutine中執行任務
process(task)
}
}假如在線程池中激活了100個goroutine來執行Worker()。Lock()和Unlock()保證了在同一時間點只能有一個goroutine取得任務并隨之更新任務列表,取任務和更新任務隊列都是critical section中的代碼,它們是具有原子性。然后這個goroutine可以執行自己取得的任務。于此同時,其它goroutine可以爭奪互斥鎖,只要爭搶到互斥鎖,就可以取得任務并更新任務列表。當某個goroutine執行完process(task),它將因為for循環再次參與互斥鎖的爭搶。
上面只是給出了一點主要的代碼段,要實現完整的線程池,還有很多額外的代碼。
通過互斥鎖,上面的一切操作都是線程安全的。但問題在于加鎖/解鎖的機制比較重量級,當worker(即goroutine)的數量足夠多,鎖機制的實現將出現瓶頸。
在Go中,也能用buffered channel實現工作池。
示例代碼很長,所以這里先拆分解釋每一部分,最后給出完整的代碼段。
在下面的示例中,每個worker的工作都是計算每個數值的位數相加之和。例如給定一個數值234,worker則計算2+3+4=9。這里交給worker的數值是隨機生成的[0,999)范圍內的數值。
這個示例有幾個核心功能需要先解釋,也是通過channel實現線程池的一般功能:
創建一個task buffered channel,并通過allocate()函數將生成的任務存放到task buffered channel中
創建一個goroutine pool,每個goroutine監聽task buffered channel,并從中取出任務
goroutine執行任務后,將結果寫入到result buffered channel中
從result buffered channel中取出計算結果并輸出
首先,創建Task和Result兩個結構,并創建它們的通道:
type Task struct {
ID int
randnum int
}
type Result struct {
task Task
result int
}
var tasks = make(chan Task, 10)
var results = make(chan Result, 10)這里,每個Task都有自己的ID,以及該任務將要被worker計算的隨機數。每個Result都包含了worker的計算結果result以及這個結果對應的task,這樣從Result中就可以取出任務信息以及計算結果。
另外,兩個通道都是buffered channel,容量都是10。每個worker都會監聽tasks通道,并取出其中的任務進行計算,然后將計算結果和任務自身放進results通道中。
然后是計算位數之和的函數process(),它將作為worker的工作任務之一。
func process(num int) int {
sum := 0
for num != 0 {
digit := num % 10
sum += digit
num /= 10
}
time.Sleep(2 * time.Second)
return sum
}這個計算過程其實很簡單,但隨后還睡眠了2秒,用來假裝執行一個計算任務是需要一點時間的。
然后是worker(),它監聽tasks通道并取出任務進行計算,并將結果放進results通道。
func worker(wg *WaitGroup){
defer wg.Done()
for task := range tasks {
result := Result{task, process(task.randnum)}
results <- result
}
}上面的代碼很容易理解,只要tasks channel不關閉,就會一直監聽該channel。需要注意的是,該函數使用指針類型的*WaitGroup作為參數,不能直接使用值類型的WaitGroup作為參數,這樣會使得每個worker都有一個自己的WaitGroup。
然后是創建工作池的函數createWorkerPool(),它有一個數值參數,表示要創建多少個worker。
func createWorkerPool(numOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < numOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}創建工作池時,首先創建一個WaitGroup的值wg,這個wg被工作池中的所有goroutine共享,每創建一個goroutine都wg.Add(1)。創建完所有的goroutine后等待所有的groutine都執行完它們的任務,只要有一個任務還沒有執行完,這個函數就會被Wait()阻塞。當所有任務都執行完成后,關閉results通道,因為沒有結果再需要向該通道寫了。
當然,這里是否需要關閉results通道,是由稍后的range迭代這個通道決定的,不關閉這個通道會一直阻塞range,最終導致死鎖。
工作池部分已經完成了。現在需要使用allocate()函數分配任務:生成一大堆的隨機數,然后將Task放進tasks通道。該函數有一個代表創建任務數量的數值參數:
func allocate(numOfTasks int) {
for i := 0; i < numOfTasks; i++ {
randnum := rand.Intn(999)
task := Task{i, randnum}
tasks <- task
}
close(tasks)
}注意,最后需要關閉tasks通道,因為所有任務都分配完之后,沒有任務再需要分配。當然,這里之所以需要關閉tasks通道,是因為worker()中使用了range迭代tasks通道,如果不關閉這個通道,worker將在取完所有任務后一直阻塞,最終導致死鎖。
再接著的是取出results通道中的結果進行輸出,函數名為getResult():
func getResult(done chan bool) {
for result := range results {
fmt.Printf("Task id %d, randnum %d , sum %d\n", result.task.id, result.task.randnum, result.result)
}
done <- true
}getResult()中使用了一個done參數,這個參數是一個信號通道,用來表示results中的所有結果都取出來并處理完成了,這個通道不一定要用bool類型,任何類型皆可,它不用來傳數據,僅用來返回可讀,所以上面直接close(done)的效果也一樣。通過下面的main()函數,就能理解done信號通道的作用。
最后還差main()函數:
func main() {
// 記錄起始終止時間,用來測試完成所有任務耗費時長
startTime := time.Now()
numOfWorkers := 20
numOfTasks := 100
// 創建任務到任務隊列中
go allocate(numOfTasks)
// 創建工作池
go createWorkerPool(numOfWorkers)
// 取得結果
var done = make(chan bool)
go getResult(done)
// 如果results中還有數據,將阻塞在此
// 直到發送了信號給done通道
<- done
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}上面分配了20個worker,這20個worker總共需要處理的任務數量為100。但注意,無論是tasks還是results通道,容量都是10,意味著任務隊列最長只能是10個任務。
下面是完整的代碼段:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type Task struct {
id int
randnum int
}
type Result struct {
task Task
result int
}
var tasks = make(chan Task, 10)
var results = make(chan Result, 10)
func process(num int) int {
sum := 0
for num != 0 {
digit := num % 10
sum += digit
num /= 10
}
time.Sleep(2 * time.Second)
return sum
}
func worker(wg *sync.WaitGroup) {
defer wg.Done()
for task := range tasks {
result := Result{task, process(task.randnum)}
results <- result
}
}
func createWorkerPool(numOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < numOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}
func allocate(numOfTasks int) {
for i := 0; i < numOfTasks; i++ {
randnum := rand.Intn(999)
task := Task{i, randnum}
tasks <- task
}
close(tasks)
}
func getResult(done chan bool) {
for result := range results {
fmt.Printf("Task id %d, randnum %d , sum %d\n", result.task.id, result.task.randnum, result.result)
}
done <- true
}
func main() {
startTime := time.Now()
numOfWorkers := 20
numOfTasks := 100
var done = make(chan bool)
go getResult(done)
go allocate(numOfTasks)
go createWorkerPool(numOfWorkers)
// 必須在allocate()和getResult()之后創建工作池
<-done
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}執行結果:
Task id 19, randnum 914 , sum 14 Task id 9, randnum 150 , sum 6 Task id 15, randnum 215 , sum 8 ............ Task id 97, randnum 315 , sum 9 Task id 99, randnum 641 , sum 11 total time taken 10.0174705 seconds
總共花費10秒。
可以試著將任務數量、worker數量修改修改,看看它們的性能比例情況。例如,將worker數量設置為99,將需要4秒,將worker數量設置為10,將需要20秒。
以上就是關于“Go實現線程池的兩種方式是什么”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





