溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“C++11語法之右值引用的方法”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“C++11語法之右值引用的方法”吧!
在原先c++的基礎上,C++11擴展了很多初始化的方法。
#include<iostream>
using namespace std;
struct A
{
int _x;
int _y;
};
int main()
int a[] = { 1,2,3,4,5 };
int a1[] { 1,2,3,4,5 };
int* p = new int[5]{ 1,2,3,4,5 };
A b = { 1,2 };//初始化
A b2[5]{ {1,1},{2,2},{3,3},{4,4},{5,5} };
A* pb = new A{ 1,2 };
A* pb2 = new A[5]{ {1,1},{2,2},{3,3},{4,4},{5,5} };
return 0;
}結果:
全部初始化正常,vs下指針后面跟數字可以表示顯示多少個。

除了上面的 new[]{}我認為是比較有意義的,很好的解決了new的對象沒有構造函數又需要同時創建多個對象的場景。
除了上面的,下面的這種方式底層實現不相同。
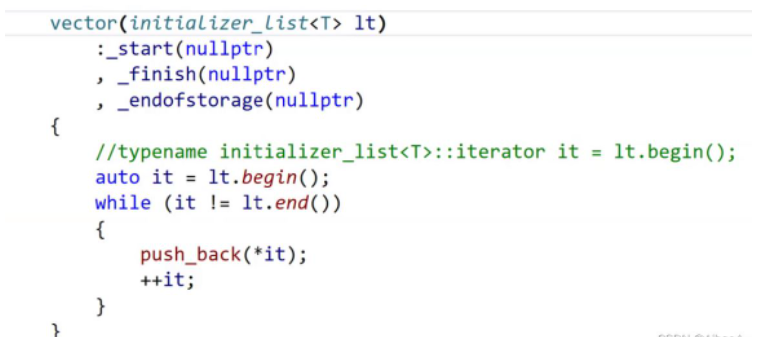
vector<int> v{1,2,3,4};
實際上上面就是通過傳參給initializer_list對象,這個對象相當于淺拷貝了外部的{1,2,3,4}的頭指針和尾指針,這樣vector的構造函數就可以通過迭代器遍歷的方式一個個的push_back到自己的容器當中。上述過程initializer_list是很高效的,因為他只涉及淺拷貝指針和一個整形。
#include <iostream>
template <class T>
class initializer_list
{
public:
typedef T value_type;
typedef const T& reference; //注意說明該對象永遠為const,不能被外部修改!
typedef const T& const_reference;
typedef size_t size_type;
typedef const T* iterator; //永遠為const類型
typedef const T* const_iterator;
private:
iterator _M_array; //用于存放用{}初始化列表中的元素
size_type _M_len; //元素的個數
//編譯器可以調用private的構造函數!!!
//構造函數,在調用之前,編譯會先在外部準備好一個array,同時把array的地址傳入模板
//并保存在_M_array中
constexpr initializer_list(const_iterator __a, size_type __l)
:_M_array(__a),_M_len(__l){}; //注意構造函數被放到private中!
constexpr initializer_list() : _M_array(0), _M_len(0){} // empty list,無參構造函數
//size()函數,用于獲取元素的個數
constexpr size_type size() const noexcept {return _M_len;}
//獲取第一個元素
constexpr const_iterator begin() const noexcept {return _M_array;}
//最后一個元素的下一個位置
constexpr const_iterator end() const noexcept
{
return begin() + _M_len;
}
};
而{}初始化,和{}調用initializer_list組合起來是可以讓初始化變得方便起來的,下面的m0用了initializer_list進行初始化,但還是比較麻煩。但m1用了{}進行單個對象初始化加initializer_list的組合之后變得方便快捷起來。
#include<map>
int main()
{
map<int, int> m0 = { pair<int,int>(1,1), pair<int,int>(2,2), pair<int,int>(3,3) };
map<int, int> m1= { {1,1},{2,2},{3,3} };
return 0;
}小總結:
一個自定義類型調用{}初始化,本質是調用對應的構造函數;自定義類型對象可以使用{}初始化,必須要有對應的參數類型和個數;STL容器支持{}初始化,則容器必須有一個initializer_list作為參數的構造函數。
auto:
定義變量前加auto表示自動存儲,表示不用管對象的銷毀,但是默認定義的就是自動類型,所以這個關鍵字后面就不這樣用了,C++11中改成了自動推導類型。
#include<cstring>
int main()
{
int i = 10;
auto p = &i;
auto pf = strcmp;
cout << typeid(p).name() << endl;
cout << typeid(pf).name() << endl;
return 0;
}結果:
int *
int (__cdecl*)(char const *,char const *)
auto只能推導類型,但推導出來的類型不能用來定義對象,decltype解決了這點,推導類型后可以用來定義對象。
decltype(表達式,變量),不能放類型!
#include<cstring>
int main()
{
int i = 10;
auto p = &i;
auto pf = strcmp;
decltype(p) pi;//int*
pi = &i;
cout << *pi << endl;//10
return 0;
}NULL在C中是0,是int類型。C++11添加nullptr表示((void*)0),避免匹配錯參數。
支持迭代器就支持范圍for
array,沒啥用,靜態的數組,不支持push_back,支持方括號,里面有assert斷言防止越界,保證了安全。
foward_list,沒啥用,單鏈表,只能在節點的后面插入。
unordered_map,很有用,后面講
unordered_set,很有用,后面講
左值
作指示一個數據表達式(變量名或解引用的指針)。
左值可以在賦值符號左右邊,右值不能出現在賦值符號的左邊。
const修飾符后的左值,不能給他賦值,但是可以取他的地址。左值引用就是給左值的引用,給左值取別名。
左值都是可以獲取地址,基本都可以可以賦值
但const修飾的左值,只能獲取地址,不能賦值。
右值?
右值也是一個數據的表達式,如字面常量,表達式返回值,傳值返回的函數的返回值(不能是左值引用返回)。右值不能取地址,不能出現在賦值符號的左邊。
關鍵看能不能取地址
給右值取別名就用右值引用,右值引用是左值了,放在賦值符號的左邊了。
右值不能取地址,但是給右值引用后,引用的變量是可以取地址的,并且可以修改!右值引用存放的地方在棧的附近。
int main()
{
int&& rra = 10;
//不想被修改 const int&& rra
cout << &rra << endl;
rra = 100;
return 0;
}左值引用總結:
左值引用只能引用左值,不能引用右值。
但是const修飾的左值引用既可以引用左值,又可以引用右值。在沒有右值引用的時候就必須采用這種方式了。
左值最重要的特征是都可以取地址,即使自定義類型也有默認的取地址重載。
右值引用總結:
右值引用只能引用右值,不能引用左值。
右值引用可以引用move以后的左值。
左值引用可以接著引用左值引用,右值引用不可以。
原因:右值引用放到左邊表示他已經是一個左值了,右值引用不能引用左值!
int main()
{
int a = 10;
int& ra = a;
int& rb = ra;
int&& rra = 10;
int&& rrb = rra;//err:無法從“int”轉換為“int && "
return 0;
}匹配問題:
void func(const int& a)
{
cout << "void func(const int& a)" << endl;
}
void func(int&& a)
cout << "void func(int&& a)" << endl;
int main()
int a = 10;
func(10);
func(a);
return 0;右值在有右值引用會去匹配右值引用版本!

本質上引用都是為了減少拷貝,提高效率。而左值引用解決了大部分的場景,但是左值引用在傳值返回的時候比較吃力,由右值引用來間接解決。
左值引用在引用傳參可以減少拷貝構造,但是返回值的時候避免不了要調用拷貝構造。
傳參用左值拷貝和右值拷貝都一樣,但是返回值如果用右值引用效率會高,并且通常左值引用面臨著對象出了作用域銷毀的問題。所以這就是右值引用的一個比較厲害的用法。
返回對象若出了作用域不存在,則用左值引用返回和右值引用返回都是錯誤的。
std::move是將對象的狀態或者所有權從一個對象轉移到另一個對象,只是轉移,沒有內存的搬遷或者內存拷貝,所以可以提高利用效率,改善性能。所以當作函數返回值的時候如果對象不存在左值引用和右值引用都會報錯!
場景:返回的對象在局部域中棧上存在,返回該對象必須用傳值返回,并且有返回對象接受,這個時候編譯器優化,將兩次拷貝構造優化成一次拷貝構造。
測試用的string類
#include<assert.h>
namespace ljh
{
class string
{
public:
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
//cout << "string(char* str)" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s1.swap(s2)
void swap(string& s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
// 拷貝構造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷貝" << endl;
string tmp(s._str);
swap(tmp);
}
// 賦值重載
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷貝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
// 移動構造
/*string(string&& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(string&& s) -- 移動語義" << endl;
swap(s);
}*/
// 移動賦值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移動語義" << endl;
swap(s);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
++_size;
_str[_size] = '\0';
}
//string operator+=(char ch)
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
const char* c_str() const
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity; // 不包含最后做標識的\0
};
}臨時變量如果是4/8字節,通常在寄存器當中,但是如果是較大的內存,會在調用方的函數棧幀中開辟一塊空間用于接受,這就是臨時對象。
臨時對象存在的必要性
當我們不需要接受返回值,而是對返回的對象進行直接使用,這個時候被調用的函數中的對象出了函數棧幀就銷毀了,所以在棧幀銷毀前會將對象拷貝到調用方棧幀的一塊空間當中,我們可以用函數名對這個臨時對象直接進行操作的(通常不能修改這個內存空間,臨時變量具有常性)。
分析下面幾組圖片代碼的效率
不可避免的,下面的這個過程必然要調用兩次拷貝構造,編譯器對于連續拷貝構造優化成不生成臨時對象,由func::ss直接拷貝給main的str,我們如果只有前面所學的左值引用,func中的string ss在出了func后銷毀,這個時候引用的空間被銷毀會出現問題,這個時候顯得特別無力。
在連續的構造+拷貝構造會被編譯器進行優化,這個優化要看平臺,但大部分平臺都會做這個處理。結果:
即使下面這種情況,在main接受沒有引用的情況下,依舊會調用一次拷貝構造,跟上面并沒有起到一個優化的作用。
結果:
解決方案:添加移動構造,添加一個右值引用版本的構造函數,構造函數內部講s對象(將亡值)的內容直接跟要構造的對象交換,效率很高!!
string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "string(string&& s) -- 移動語義" << endl;swap(s);}有了移動構造,對于上面的案例就變成了一次拷貝構造加一次移動構造。**編譯器優化后將ss判斷為將亡值,直接移動構造str對象,不產生臨時對象了,就只是一次移動構造,效率升高!!**同理移動賦值!
結果:
下面情況是引用+移動構造,但是編譯器優化就會判斷ss出了作用域還存在,反而會拿ss拷貝構造str,這個時候起不到優化的作用!
結果:
以上采用將對象開辟在堆上或靜態區都能夠采用引用返回解決問題,但是有一個壞處?
引入多線程的概念,每個線程執行的函數當中若有大量的堆上的數據或者靜態區的數據,相當于臨界資源變多,要注意訪問臨界資源要加鎖。而每個棧區私有棧,會相對好些
右值:
1、內置類型表達式的右值,純右值。
2、自定義類型表達式的右值,將亡值。
將亡值:
string(string&& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(string&& s) -- 移動語義" << endl;
swap(s);
}
int main()
{
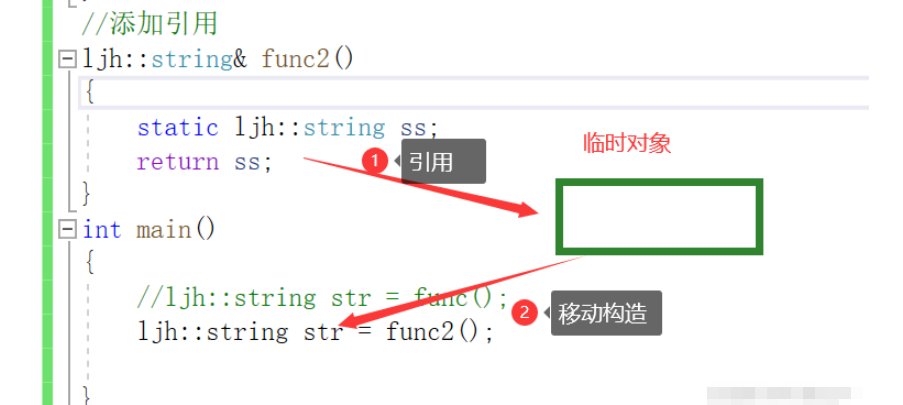
ljh::string& str = func2();
vector<ljh::string> v;
v.push_back("1234656");//傳進去的就是右值,是用"1234656"構造一個string對象傳入,就是典型的將亡值
}移動構造:
將亡值在出了生命周期就要銷毀了,構造的時候可以將資源轉移過要構造的對象,讓將亡的對象指向NULL,相當于替它掌管資源。移動構造不能延續對象的生命周期,而是轉移資源。且移動構造編譯器不優化本質是一次拷貝構造+一次移動構造(從將亡值(此時返回值還是一個左值)給到臨時變量),再有臨時變量給到返回值接受對象(移動構造);
編譯器優化做第一次優化,會將將亡值當作右值,此時要進行兩次移動構造,編譯器第二次優化,直接進行一次移動構造,去掉生成臨時對象的環節。
只有需要深拷貝的場景,移動構造才有意義,跟拷貝構造一樣,淺拷貝意義不大。
move的真正意義:
表示別人可以將這個資源進行轉移走。

int main()
{
//為了防止這種情況,也要添加移動賦值。
ljh::string str1;
str1 = "123456";
}
c++11的算法swap的效率跟容器提供的swap效率一樣了。
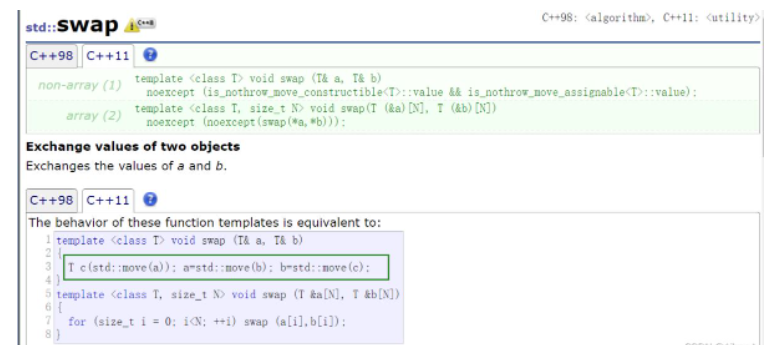
vector提供的插入的右值引用版本,就是優化了傳右值情況,如果C++98則需要拷貝放入,而有右值就可以直接移動構造。兩個接口的效率差不多。
大多數容器的插入接口都做了右值引用版本!!
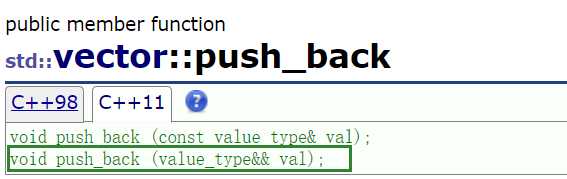
模板函數或者模板類用的&&即萬能引用。
模板中的&&不代表右值引用,而是萬能引用,其既能接收左值又能接收右值。模板的萬能引用只是提供了能夠接收同時接收左值引用和右值引用的能力。而forward才能將這種右值特性保持下去。
但是引用類型的唯一作用就是限制了接收的類型,后續使用中都退化成了左值,
此時右值在萬能引用成為左值,可能會造成本身右值可以移動構造,卻變成左值只能拷貝構造了。Fun(std::forward<T>(t));才能夠保證轉發的時候值的特性
void Fun(int &x){ cout << "左值引用" << endl; }
void Fun(const int &x){ cout << "const 左值引用" << endl; }
void Fun(int &&x){ cout << "右值引用" << endl; }
void Fun(const int &&x){ cout << "const 右值引用" << endl; }
void Func(int x) {
// ......
}
template<typename T>
void PerfectForward(T&& t) {
Fun(t);
}
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0; }C++11 新增了兩個:移動構造函數和移動賦值運算符重載。
現在有8個:構造函數,析構函數,拷貝構造,拷貝賦值,取地址,const取地址移動構造,移動賦值。
移動構造函數的默認生成的要求比較嚴格:
如果你沒有自己實現移動構造函數,且沒有實現析構函數 、拷貝構造、拷貝賦值重載都沒有實現。那么編譯器會自動生成一個默認移動構造。默認生成的移動構造函數,對于內置類型
成員會執行逐成員按字節拷貝,自定義類型成員,則需要看這個成員是否實現移動構造,如
果實現了移動構造就調用移動構造,沒有實現就調用拷貝構造。
如果你提供了移動構造或者移動賦值,編譯器不會自動提供拷貝構造和拷貝賦值。
同理移動賦值。
即對于深拷貝的類,最好所有的構造,析構,拷貝,賦值重載,移動拷貝,移動賦值都寫上。
感謝各位的閱讀,以上就是“C++11語法之右值引用的方法”的內容了,經過本文的學習后,相信大家對C++11語法之右值引用的方法這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。