溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Docker虛擬化怎么部署的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Docker虛擬化怎么部署文章都會有所收獲,下面我們一起來看看吧。
本小節將介紹 Docker 虛擬化的一些特點。
Docker 是一個開放源代碼軟件項目,自動化進行應用程序容器化部署,借此在Linux操作系統上,提供一個額外的軟件抽象層,以及操作系統層虛擬化的自動管理機制。 -From wiki

在接觸 Docker 的過程中,或多或少會了解到 Docker 的虛擬化,最常見的介紹方式是對比 Docker 和虛擬機之間的差別,筆者這里也給出兩者的對比表格,以便后面詳細地展開來講。
| 虛擬機 | Docker 容器 | |
|---|---|---|
| 隔離程度 | 硬件級進程隔離 | 操作系統級進程隔離 |
| 系統 | 每個虛擬機都有一個單獨的操作系統 | 每個容器可以共享操作系統(共享操作系統內核) |
| 啟動時間 | 需要幾分鐘 | 幾秒 |
| 體積大小 | 虛擬機鏡像GB級別 | 容器是輕量級的(KB/MB) |
| 啟動鏡像 | 虛擬機鏡像比較難找到 | 預建的 docker 容器很容易獲得 |
| 遷移 | 虛擬機可以輕松遷移到新主機 | 容器被銷毀并重新創建而不是移動 |
| 創建速度 | 創建 VM 需要相對較長的時間 | 可以在幾秒鐘內創建容器 |
| 資源使用 | GB級別 | MB級別 |
Docker 中的虛擬化是依賴于 Windows 和 Linux 內核的,在 Windows 上會要求開啟 Hyper-V,在 Linux 上需要依賴 namespace 和 cgroups 等,因此這里就不過多介紹 Docker 了,后面主要介紹 Linux 上的虛擬化技術。
傳統虛擬化方式是在硬件抽象級別虛擬化,其特點是 虛擬化程度高。
傳統虛擬化方式的優點是:
1,虛擬機之間通過虛擬化技術隔離互不影響
2,物理機上可部署多臺虛擬機,提升資源利用率
3,應用資源分配、擴容通過虛擬管理器直接可配置
4,支持快照、虛擬機克隆多種技術,快速部署、容災減災
傳統虛擬化部署方式的缺點:
1,資源占用高,需要額外的操作系統鏡像,需要占用GB級別的內存以及數十GB存儲空間。
2,啟動速度慢,虛擬機啟動需要先啟動虛擬機內操作系統,然后才能啟動應用。
3,性能影響大,應用 => 虛擬機操作系統=> 物理機操作系統=> 硬件資源
本節簡單地講解 Docker 的實現原理,讀者可以從中了解 Linux 是如何隔離資源的、Docker 又是如何隔離的。
我們知道,操作系統是以一個進程為單位進行資源調度的,現代操作系統為進程設置了資源邊界,每個進程使用自己的內存區域等,進程之間不會出現內存混用。Linux 內核中,有 cgroups 和 namespaces 可以為進程定義邊界,使得進程彼此隔離。
在容器中,當我們使用 top 命令或 ps 命令查看機器的進程時,可以看到進程的 Pid,每個進程都有一個 Pid,而機器的所有容器都具有一個 Pid = 1 的基礎,但是為什么不會發生沖突?容器中的進程可以任意使用所有端口,而不同容器可以使用相同的端口,為什么不會發生沖突?這些都是資源可以設定邊界的表現。
在 Linux 中,namespace 是 Linux 內核提供的一種資源隔離技術,可以將系統中的網絡、進程環境等進行隔離,使得每個 namespace 中的系統資源不再是全局性的。目前有以下 6 種資源隔離,Docker 也基本在這 6 種資源上對容器環境進行隔離。
讀者可以稍微記憶一下這個表格,后面會使用到。
| namespace | 系統調用參數 | 隔離內容 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主機名和域名 |
| IPC | CLONE_NEWIPC | 信號量、消息隊列、共享內存 |
| PID | CLONE_NEWPID | 進程編號 |
| Network | CLONE_NEWNET | 網絡設備、網絡棧、端口 |
| Mount | CLONE_NEWNS | 文件系統掛載 |
| User | CLONE_NEWUSER | 用戶和用戶組 |
[info] 關于 Mount
namespace 的 Mount 可以實現將子目錄掛載為根目錄。
Linux 中,unshare 命令行程序可以創建一個 namespace,并且根據參數創建在 namespace 中隔離各種資源,在這里我們可以用使用這個工具簡單地創建一個 namespace。
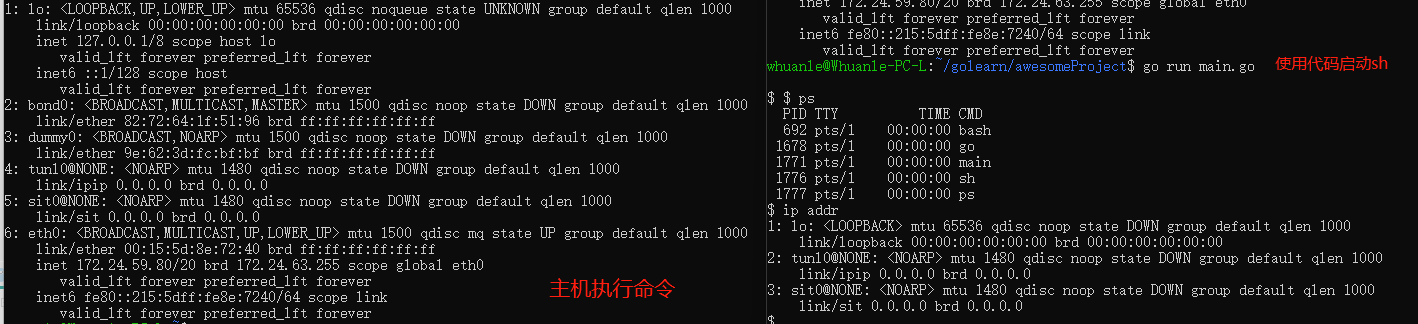
為了深刻理解 Linux 中的 namespace,我們可以在 Linux 中執行:
unshare --pid /bin/sh
--pid僅隔離進程。
這命令類似于docker run -it {image}:{tag} /bin/sh。當我們執行命令后,終端會進入一個 namespace 中,執行 top 命令查看進程列表。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 160188 8276 5488 S 0.0 0.4 9:35.58 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.08 kthreadd 3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
可以看到,進程 PID 是從 1 開始的,說明在這個 namespace 中,與主機的進程是隔離開來的。
這個命令中,只隔離了進程,因為并沒有隔離網絡,因此當我們執行netstat --tlap命令時,這個命名空間的網絡跟其它命名空間的網絡是相通的。
在執行 unshare 命令前,使用 pstree 命令查看進程樹:
init─┬─2*[init───init───bash]
├─init───init───bash───pstree
├─init───init───fsnotifier-wsl
├─init───init───server───14*[{server}]
└─2*[{init}]為了方便比較,我們使用unshare --pid top創建一個 namespace,對比執行了 unshare 命令后:
$> pstree -lha
init
├─init
│ └─init
│ └─bash
│ └─sudo unshare --pid top
│ └─top
├─init
│ └─init
│ └─bash
│ └─pstree -lha
├─init
│ └─init
│ └─fsnotifier-wsl
├─init
│ └─init
│ └─bash
├─init
│ └─init
│ └─server --port 29687 --instance WSL-Ubuntu
│ └─14*[{server}]
└─2*[{init}]而在 namespace 中,查看 top 顯示的內容,發現:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 1904 1136 1020 S 0.0 0.0 0:08.38 init
通過進程樹可以看到,不同 namespace 內的進程處于不同的樹支,他們的進程 PID 也是相互獨立的。其功能類似于 Docker 中的 runc。
在 unshare 命令中,--pid 參數創建 隔離進程的命名空間,此外,還可以隔離多種系統資源:
mount :命名空間具有獨立的掛載文件系統;
ipc:Inter-Process Communication (進程間通訊)命名空間,具有獨立的信號量、共享內存等;
uts:命名空間具有獨立的 hostname 、domainname;
net:獨立的網絡,例如每個 docker 容器都有一個虛擬網卡;
pid:獨立的進程空間,空間中的進程 Pid 都從 1 開始;
user:命名空間中有獨立的用戶體系,例如 Docker 中的 root 跟主機的用戶不一樣;
cgroup:獨立的用戶分組;
在前面我們使用了 unshare 創建命名空間,在這里我們可以嘗試使用 Go 調用 Linux 內核的 namespace,通過編程代碼創建隔離的資源空間。
Go 代碼示例如下:
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWUSER,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatalln(err)
}
}[info] 提示
前面已經提到過 UTS 等資源隔離,讀者可以參考表格中的說明,對照代碼理解 Cloneflags 的作用。
在這個代碼中,我們啟動了 Linux 中的 sh 命令,開啟一個新的進程,這個進程將會使用新的 IPC、PID 等隔離。
讀者可以在 Linux 中,執行 go run main.go ,即可進入新的命名空間。
關于 namespace 的介紹就到這里。
前面提到的 namepace 是邏輯形式使得進程之間相互不可見,形成環境隔離,這跟 Docker 容器的日常使用是一樣的,隔離根目錄,隔離網絡,隔離進程 PID 等。
當然,Docker 處理環境隔離外,還能限制每個容器使用的物理資源,如 CPU 、內存等,這種硬件資源的限制是基于 Linux 內核的 cgroups 的。
在 Docker 中限制容器能夠使用的資源量參數示例:
-m 4G --memory-swap 0 --cpu-period=1000000 --cpu-quota=8000000
cgroups 是 control groups 的縮寫,是 Linux 內核提供的一種可以進程所使用的物理資源的機制。
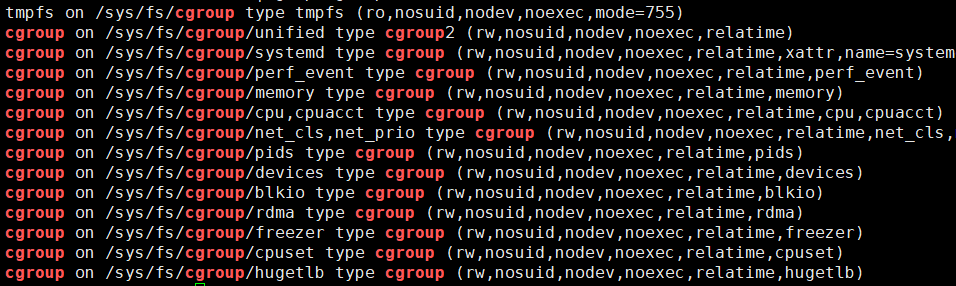
cgroups 可以控制多種資源,在 cgroups 中每種資源限制功能對應一個子系統,可以使用命令查看:
mount | grep cgroup
[info] 提示
每種子系統的功能概要如下:
blkio— 該子系統對進出塊設備的輸入/輸出訪問設置限制,如 USB 等。
cpu— 該子系統使用調度程序來提供對 CPU 的 cgroup 任務訪問。
cpuacct— 該子系統生成有關 cgroup 中任務使用的 CPU 資源的自動報告。
cpuset— 該子系統將單個 CPU和內存節點分配給 cgroup 中的任務。
devices— 該子系統允許或拒絕 cgroup 中的任務訪問設備。
freezer— 該子系統在 cgroup 中掛起或恢復任務。
memory— 該子系統對 cgroup 中的任務使用的內存設置限制,并生成有關自動報告。
net_cls— 允許 Linux 流量控制器 (tc) 識別源自特定 cgroup 任務的數據包。
net_prio— 該子系統提供了一種動態設置每個網絡接口的網絡流量優先級的方法。
ns—命名空間子系統。
perf_event— 該子系統識別任務的 cgroup 成員資格,可用于性能分析。詳細內容請參考:redhat 文檔
我們也可以使用 lssubsys 命令,查看內核支持的子系統。
$> lssubsys -a cpuset cpu cpuacct blkio memory devices freezer net_cls perf_event net_prio hugetlb pids rdma
[info] 提示
Ubuntu 可以使用
apt install cgroup-tools安裝工具。
為了避免篇幅過大,讀者只需要知道 Docker 限制容器資源使用量、CPU 核數等操作,其原理是 Linux 內核中的 cgroups 即可,筆者這里不再贅述。
本節內容將從底層角度,聊聊虛擬化。
從語言角度,一臺由軟硬件組成的通用計算機系統可以看作是按功能劃分的多層機器級組成的層次結構。
如果從語言角度來看,計算機系統的層次結構可用下圖所示。
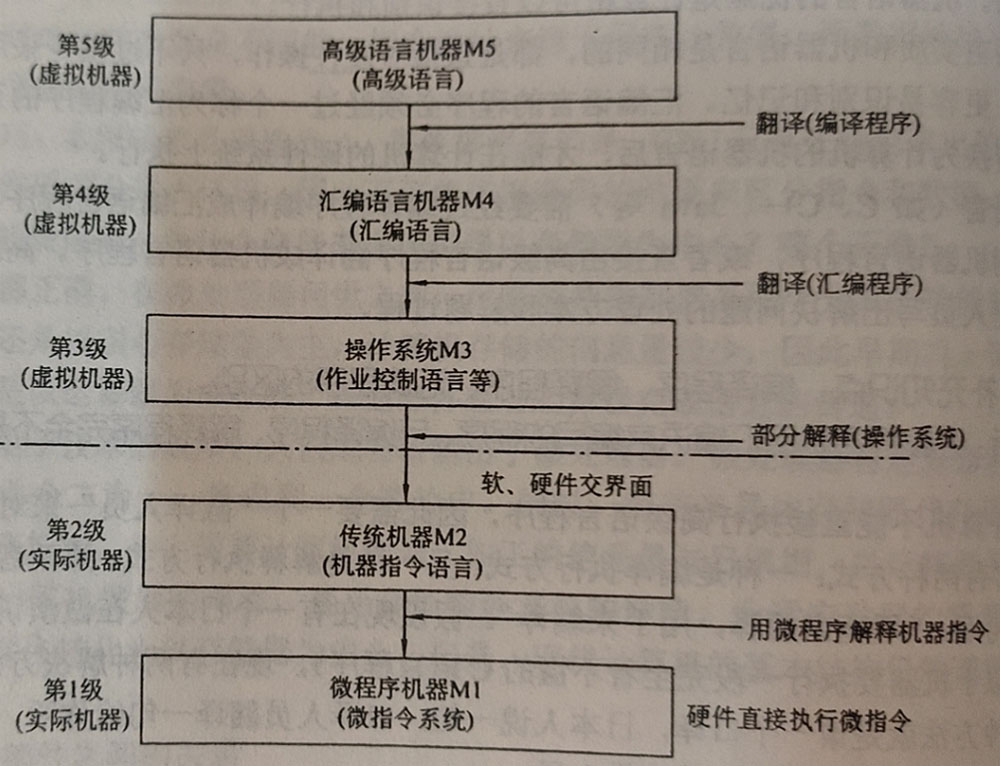
我們平時使用的筆記本、安卓手機、平板電腦、Linux 服務器等,雖然不同機器的系統和部分硬件差異很大,但是其系統結構是一致的。從 CPU 中晶體管、寄存器 到 CPU 指令集,再到操作系統、匯編,現在使用的通用計算機基本上這種結構。
下面講解一下不同層次的主要特點。
計算機的最底層是硬聯邏輯級,由門電路,觸發器等邏輯電路組成,特征是使用極小的元件構成,表示了計算機中的 0、1。

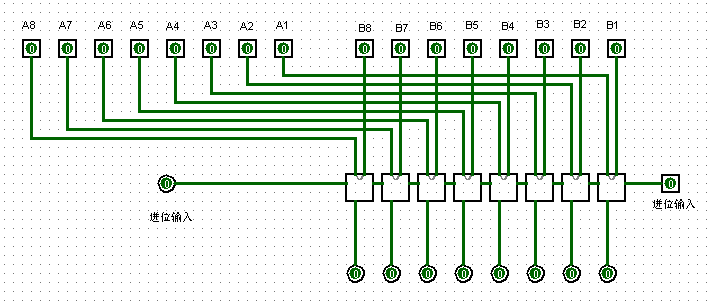
微程序是使用微指令編寫的,一個微程序即一個機器指令,一般直接由硬件執行,它可以表示一個最簡單的操作。例如一個加法指令,由多個邏輯元件構成一個加法器,其元件組成如下圖所示(圖中為一個 8 位全加器)。
傳統機器語言機器級是處理器的指令集所在,我們熟知的 X86、ARM、MIPS、RISC-V 等指令集,便是在這個層次。程序員使用指令集中的指令編寫的程序,由低一層微程序解釋。
操作系統機器層是從操作系統基本功能來看的,操作系統需要負責管理計算機中的軟硬件資源,如內存、設備、文件等,它是軟硬件的交互界面。常用的操作系統有 Windows、Linux、Unix 等。這個層次使用的語言是機器語言,即 0、1 組成的二進制代碼,能夠由計算機直接識別和執行。
匯編語言機器層顧名思義是匯編語言所在的位置,匯編語言與處理器有關,相同類型的處理器使用的匯編語言集是一致的。匯編語言需要被匯編語言程序變換為等效的二進制代碼目標程序。由于計算機中的資源被操作系統所管理,因此匯編語言需要在操作系統的控制下進行。
到了高級語言機器層,便是我們使用的 C、C++ 等編程語言,高級語言是與人類思維相接近的語言。
計算機的某些功能即可以由硬件實現,也可以由軟件來實現。即軟件和硬件在功能意義上是等效的。
一個功能使用硬件來實現還是使用軟件來實現?
硬件實現:速度快、成本高;靈活性差、占用內存少。
軟件實現:速度低、復制費用低;靈活性好、占用內存多。
虛擬化技術是將原本 硬件實現的功能,使用軟件來實現,它們在性能、價格、實現的難易程度是不同的。一個功能既可以使用硬件實現,也可以使用軟件實現,也可以兩者結合實現,可能要根據各種人力成本、研發難度、研發周期等考慮。
虛擬化(技術)或虛擬技術是一種資源管理技術,將計算機的各種實體資源(CPU、內存、磁盤空間、網絡適配器等),予以抽象、轉換后呈現出來并可供分割、組合為一個或多個計算機配置環境。
我們應該在很多書籍、文章中,了解到虛擬機跟 Docker 的比較,了解到 Docker 的優點,通過 Docker 打包鏡像后可以隨時在別的地方運行而不需要擔心機器的兼容問題。但是 Docker 的虛擬化并不能讓 Linux 跑 Windows 容器,也不能讓 Windows 跑 Linux 容器,更不可能讓 x86 機器跑 arm 指令集的二進制程序。但是 VMware 可以在 Windows 運行 Linux 、Mac 的鏡像,但 WMWare 也不能由 MIPS 指令構建的 Linux 系統。
Docker 和 VMware 都可以實現不同程度的虛擬化,但也不是隨心所欲的,它們虛擬化的程度相差很大,因為它們是在不同層次進行虛擬化的。

[Info] 提示
許多虛擬化軟件不單單是在一個層面上,可能具有多種層次的虛擬化能力。
在指令集級別虛擬化中,從指令系統上看,就是要在一種機器上實現另一種機器的指令系統。例如,QEMU 可以實現在 X64 機器上模擬 ARM32/64、龍芯、MIPS 等處理器。
虛擬化程度在于使用硬件實現與軟件實現的比例,硬件部分比例越多一般來說性能就會越強,軟件部分比例越多靈活性會更強,但是性能會下降,不同層次的實現也會影響性能、兼容性等。隨著現在計算機性能越來越猛,很大程度上產生了性能過剩;加之硬件研發的難度越來越高,越來越難突破,非硬件程度的虛擬化將會越來越廣泛。
關于“Docker虛擬化怎么部署”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Docker虛擬化怎么部署”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





