溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Netty分布式解碼器讀取數據不完整的邏輯是什么,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
如果Server在讀取客戶端的數據的時候, 如果一次讀取不完整, 就觸發channelRead事件, 那么Netty是如何處理這類問題的, 在這一章中, 會對此做詳細剖析
之前的章節我們學習過pipeline, 事件在pipeline中傳遞, handler可以將事件截取并對其處理, 而之后剖析的編解碼器, 其實就是一個handler, 截取byteBuf中的字節, 然后組建成業務需要的數據進行繼續傳播
編碼器, 通常是OutBoundHandler, 也就是以自身為基準, 對那些對外流出的數據做處理, 所以也叫編碼器, 將數據經過編碼發送出去
解碼器, 通常是inboundHandler, 也就是以自身為基準, 對那些流向自身的數據做處理, 所以也叫解碼器, 將對向的數據接收之后經過解碼再進行使用
同樣, 在netty的編碼器中, 也會對半包和粘包問題做相應的處理
什么是半包, 顧名思義, 就是不完整的數據包, 因為netty在輪詢讀事件的時候, 每次將channel中讀取的數據, 不一定是一個完整的數據包, 這種情況, 就叫半包
粘包同樣也不難理解, 如果client往server發送數據包, 如果發送頻繁很有可能會將多個數據包的數據都發送到通道中, 如果在server在讀取的時候可能會讀取到超過一個完整數據包的長度, 這種情況叫粘包
有關半包和粘包, 入下圖所示:
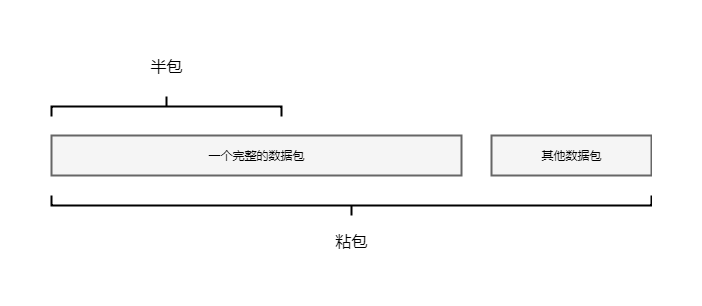
6-0-1
netty對半包的或者粘包的處理其實也很簡單, 通過之前的學習, 我們知道, 每個handler是和channel唯一綁定的, 一個handler只對應一個channel, 所以將channel中的數據讀取時候經過解析, 如果不是一個完整的數據包, 則解析失敗, 將這塊數據包進行保存, 等下次解析時再和這個數據包進行組裝解析, 直到解析到完整的數據包, 才會將數據包進行向下傳遞
具體流程是在代碼中如何體現的呢?我們進入到源碼分析中
ByteToMessageDecoder解碼器, 顧名思義, 是一個將Byte解析成消息的解碼器,
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter{
//類體省略
}這里繼承了ChannelInboundHandlerAdapter, 根據之前的學習, 我們知道, 這是個inbound類型的handler, 也就是處理流向自身事件的handler
其次, 該類通過abstract關鍵字修飾, 說明是個抽象類, 在我們實際使用的時候, 并不是直接使用這個類, 而是使用其子類, 類定義了解碼器的骨架方法, 具體實現邏輯交給子類, 同樣, 在半包處理中也是由該類進行實現的
netty中很多解碼器都實現了這個類, 并且, 我們也可以通過實現該類進行自定義解碼器
我們重點關注一下該類的一個屬性:
ByteBuf cumulation;
這個屬性, 就是有關半包處理的關鍵屬性, 從概述中我們知道, netty會將不完整的數據包進行保存, 這個數據包就是保存在這個屬性中
之前的學習我們知道, ByteBuf讀取完數據會傳遞channelRead事件, 傳播過程中會調用handler的channelRead方法, ByteToMessageDecoder的channelRead方法, 就是編碼的關鍵部分
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//如果message是byteBuf類型
if (msg instanceof ByteBuf) {
//簡單當成一個arrayList, 用于盛放解析到的對象
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
//當前累加器為空, 說明這是第一次從io流里面讀取數據
first = cumulation == null;
if (first) {
//如果是第一次, 則將累加器賦值為剛讀進來的對象
cumulation = data;
} else {
//如果不是第一次, 則把當前累加的數據和讀進來的數據進行累加
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
//調用子類的方法進行解析
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Throwable t) {
throw new DecoderException(t);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
numReads = 0;
discardSomeReadBytes();
}
//記錄list長度
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
//向下傳播
fireChannelRead(ctx, out, size);
out.recycle();
}
} else {
//不是byteBuf類型則向下傳播
ctx.fireChannelRead(msg);
}
}這方法比較長, 帶大家一步步剖析
首先判斷如果傳來的數據是ByteBuf, 則進入if塊中
CodecOutputList out = CodecOutputList.newInstance() 這里就當成一個ArrayList就好, 用于盛放解碼完成的數據
ByteBuf data = (ByteBuf) msg 這步將數據轉化成ByteBuf
first = cumulation == null 這里表示如果cumulation == null, 說明沒有存儲板半包數據, 則將當前的數據保存在屬性cumulation中
如果 cumulation != null , 說明存儲了半包數據, 則通過cumulator.cumulate(ctx.alloc(), cumulation, data)將讀取到的數據和原來的數據進行累加, 保存在屬性cumulation中
private Cumulator cumulator = MERGE_CUMULATOR;
這里調用了其靜態屬性MERGE_CUMULATOR, 我們跟過去:
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
//不能到過最大內存
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1) {
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
} else {
buffer = cumulation;
}
//將當前數據buffer
buffer.writeBytes(in);
in.release();
return buffer;
}
};這里創建了Cumulator類型的靜態對象, 并重寫了cumulate方法, 這里cumulate方法, 就是用于將ByteBuf進行拼接的方法:
方法中, 首先判斷cumulation的寫指針+in的可讀字節數是否超過了cumulation的最大長度, 如果超過了, 將對cumulation進行擴容, 如果沒超過, 則將其賦值到局部變量buffer中
然后將in的數據寫到buffer中, 將in進行釋放, 返回寫入數據后的ByteBuf
回到channelRead方法中:
最后通過callDecode(ctx, cumulation, out)方法進行解碼, 這里傳入了Context對象, 緩沖區cumulation和集合out:
我們跟到callDecode(ctx, cumulation, out)方法中:
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
//只要累加器里面有數據
while (in.isReadable()) {
int outSize = out.size();
//判斷當前List是否有對象
if (outSize > 0) {
//如果有對象, 則向下傳播事件
fireChannelRead(ctx, out, outSize);
//清空當前list
out.clear();
//解碼過程中如ctx被removed掉就break
if (ctx.isRemoved()) {
break;
}
outSize = 0;
}
//當前可讀數據長度
int oldInputLength = in.readableBytes();
//子類實現
//子類解析, 解析玩對象放到out里面
decode(ctx, in, out);
if (ctx.isRemoved()) {
break;
}
//List解析前大小 和解析后長度一樣(什么沒有解析出來)
if (outSize == out.size()) {
//原來可讀的長度==解析后可讀長度
//說明沒有讀取數據(當前累加的數據并沒有拼成一個完整的數據包)
if (oldInputLength == in.readableBytes()) {
//跳出循環(下次在讀取數據才能進行后續的解析)
break;
} else {
//沒有解析到數據, 但是進行讀取了
continue;
}
}
//out里面有數據, 但是沒有從累加器讀取數據
if (oldInputLength == in.readableBytes()) {
throw new DecoderException(
StringUtil.simpleClassName(getClass()) +
".decode() did not read anything but decoded a message.");
}
if (isSingleDecode()) {
break;
}
}
} catch (DecoderException e) {
throw e;
} catch (Throwable cause) {
throw new DecoderException(cause);
}
}這里首先循環判斷傳入的ByteBuf是否有可讀字節, 如果還有可讀字節說明沒有解碼完成, 則循環繼續解碼
然后判斷集合out的大小, 如果大小大于1, 說明out中盛放了解碼完成之后的數據, 然后將事件向下傳播, 并清空out
因為我們第一次解碼out是空的, 所以這里不會進入if塊, 這部分我們稍后分析, 這里繼續往下看
通過 int oldInputLength = in.readableBytes() 獲取當前ByteBuf, 其實也就是屬性cumulation的可讀字節數, 這里就是一個備份用于比較, 我們繼續往下看:
decode(ctx, in, out)方法是最終的解碼操作, 這部會讀取cumulation并且將解碼后的數據放入到集合out中, 在ByteToMessageDecoder中的該方法是一個抽象方法, 讓子類進行實現, 我們使用的netty很多的解碼都是繼承了ByteToMessageDecoder并實現了decode方法從而完成了解碼操作, 同樣我們也可以遵循相應的規則進行自定義解碼器, 在之后的小節中會講解netty定義的解碼器, 并剖析相關的實現細節, 這里我們繼續往下看:
if (outSize == out.size()) 這個判斷表示解析之前的out大小和解析之后out大小進行比較, 如果相同, 說明并沒有解析出數據, 我們進入到if塊中:
if (oldInputLength == in.readableBytes()) 表示cumulation的可讀字節數在解析之前和解析之后是相同的, 說明解碼方法中并沒有解析數據, 也就是當前的數據并不是一個完整的數據包, 則跳出循環, 留給下次解析, 否則, 說明沒有解析到數據, 但是讀取了, 所以跳過該次循環進入下次循環
最后判斷 if (oldInputLength == in.readableBytes()) , 這里代表out中有數據, 但是并沒有從cumulation讀數據, 說明這個out的內容是非法的, 直接拋出異常
我們關注finally中的內容:
finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
numReads = 0;
discardSomeReadBytes();
}
//記錄list長度
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
//向下傳播
fireChannelRead(ctx, out, size);
out.recycle();
}首先判斷cumulation不為null, 并且沒有可讀字節, 則將累加器進行釋放, 并設置為null
之后記錄out的長度, 通過fireChannelRead(ctx, out, size)將channelRead事件進行向下傳播, 并回收out對象
我們跟到fireChannelRead(ctx, out, size)方法中:
static void fireChannelRead(ChannelHandlerContext ctx, CodecOutputList msgs, int numElements) {
//遍歷List
for (int i = 0; i < numElements; i ++) {
//逐個向下傳遞
ctx.fireChannelRead(msgs.getUnsafe(i));
}
}這里遍歷out集合, 并將里面的元素逐個向下傳遞
關于“Netty分布式解碼器讀取數據不完整的邏輯是什么”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





