溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“R語言數據類型與相應運算的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“R語言數據類型與相應運算的示例分析”這篇文章吧。
R 語言基本的數據類型有數值型,邏輯型(TRUE, FALSE),文本(字符串)。 支持缺失值,有專門的復數類型。
常量是指直接寫在程序中的值。
數值型常量包括整型、單精度、雙精度等,一般不需要區分。寫法如 123, 123.45, -123.45,-0.012, 1.23E2, -1.2E-2 等。為了表示 123 是整型,可以寫成 123L。
字符型常量用兩個雙撇號或兩個單撇號包圍,如"Li Ming" 或'Li Ming'。字符型支持中文,如"李明" 或'李明'。國內的中文編碼主要有 GBK 編碼和 UTF-8 編碼,有時會遇到編碼錯誤造成亂碼的題,MS Windows 下 R 程序 一般用 GBK 編碼,但是 RStudio 軟件采用 UTF-8 編碼。在 R 軟件內字符串一般用 UTF-8 編碼保存。
邏輯型常量只有 TRUE 和 FALSE。
缺失值用 NA 表示。統計計算中經常會遇到缺失值,表示記錄丟失、因為錯誤而不能用、節假日沒有數據等。除了數值型,邏輯型和字符型也可以有缺失值,而且字符型的空白值不會自動辨識為缺失值,需要自己規定。R 支持特殊的 Inf 值,這是實數型值,表示正無窮大,不算缺失值。
復數常量寫法如 2.2 + 3.5i, 1i 等。
程序語言中的變量用來保存輸入的值或者計算得到的值。在 R 中,變量可以保存所有的數據類型,比如標量、向量、矩陣、數據框、函數等。
變量都有變量名,R 變量名必須以字母、數字、下劃線和句點組成,變量名的第一個字符不能取為數字。在中文環境下,漢字也可以作為變量名的合法字符使用。變量名是區分大小寫的,y 和 Y 是兩個不同的變量名。
變量名舉例: x, x1, X, cancer.tab, clean_data, diseaseData。
用 <-賦值的方法定義變量。<-也可以寫成 =,但是 <-更直觀。如
x5 <- 6.25 x6 = sqrt(x5)
R 語言基本的數據類型有數值,邏輯型(TRUE, FALSE),文本(字符串)。支持缺失值,有專門的復數類型。
R 語言數據結構包括向量,矩陣和數據框,多維數組,列表,對象等。數據中元素、行、列還可以用名字訪問。最基本的是向量類型。向量類型數據的訪問方式也是其他數據類型訪問方式的基礎。
向量是將若干個基礎類型相同的值存儲在一起,各個元素可以按序號訪問。如 果將若干個數值存儲在一起可以用序號訪問,就叫做一個數值型向量。
用 c() 函數把多個元素或向量組合成一個向量。如:
marks <- c(10, 6, 4, 7, 8) marks
返回:

再如:
x <- c(1:3, 10:13) x
返回:

再如:
x1 <- c(1, 2) x2 <- c(3, 4) x <- c(x1, x2) x
返回:

length(x) 可以求 x 的長度
x <- c(1:3, 10:13) length(x)
返回:

numeric() 函數可以用來初始化一個指定元素個數而元素都等于零的數值型向量,如 numeric(10) 會生成元素為 10 個零的向量,長度為零的向量表示為 numeric(0)。
numeric(10)
返回:

單個數值稱為標量,R 沒有單獨的標量類型,標量實際是長度為 1 的向量。 R 中四則運算用 + - * / ˆ 表示 (加、減、乘、除、乘方),如
1.5 + 2.3 - 0.6 + 2.1*1.2 - 1.5/0.5 + 2^3 ## [1] 10.72
返回:

R 中四則運算仍遵從通常的優先級規則,可以用圓括號 () 改變運算的先后次序。如
1.5 + 2.3 - (0.6 + 2.1)*1.2 - 1.5/0.5 + 2^3 ## [1] 5.56
除了加、減、乘、除、乘方,R 還支持整除運算和求余運算。用%/% 表示整除, 用%% 表示求余。如
5 %/% 3 ## [1] 1 5 %% 3 ## [1] 2
返回:

向量與標量的運算為每個元素與標量的運算, 如
x <- c(1, 10) x + 2 ## [1] 3 12 x - 2 ## [1] -1 8 x * 2 ## [1] 2 20 x / 2 ## [1] 0.5 5.0 x ^ 2 ## [1] 1 100 2 / x ## [1] 2.0 0.2 2 ^ x ## [1] 2 1024 x %% 2 ##[1] 1 0 x %/% 2 ##[1] 0 5
返回:
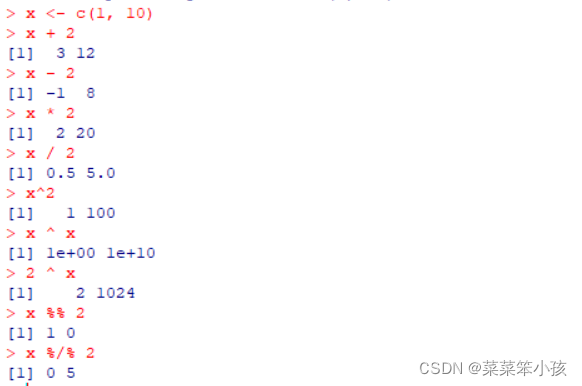
一個向量乘以一個標量,就是線性代數中的數乘運算。 四則運算時如果有缺失值,缺失元素參加的運算相應結果元素仍缺失。如
c(1, NA, 3) + 10
返回:

等長向量的運算為對應元素兩兩運算。如
x1 <- c(1, 10) x2 <- c(4, 2) x1 + x2
返回:

同樣也可以進行減,乘,除;如
x1 - x2 ## [1] -3 8 x1 * x2 ## [1] 4 20 x1 / x2 ## [1] 0.25 5.00
兩個不等長向量的四則運算,如果其長度為倍數關系,規則是每次從頭重復利用短的一個。如:
x1 <- c(10, 20) x2 <- c(1, 3, 5, 7) x1 + x2
返回:

不僅是四則運算,R 中有兩個或多個向量按照元素一一對應參與某種運算或函數調用時,如果向量長度不同,一般都采用這樣的規則。 如果兩個向量的長度不是倍數關系,會給出警告信息。如
c(1,2) + c(1,2,3)
返回:

R 中的函數一般都是向量化的: 在 R 中,如果普通的一元函數以向量為自變量,一般會對每個元素計算。這樣的函數包括 sqrt, log10, log, exp, sin, cos, tan 等許多。如
sqrt(c(1, 4, 6.25))
返回:

為了查看這些基礎的數學函數的列表,運行命令 help.start(),點擊鏈接 “Search Engine and Keywords”,找到 “Mathematics” 欄目,瀏覽其中的 “arith” 和 “math” 鏈接中的說明。
常用的數學函數有:常用的數學函數有:
• 舍入:ceiling, floor, round, signif, trunc, zapsmall
• 符號函數 sign
• 絕對值 abs
• 平方根 sqrt
• 對數與指數函數 log, exp, log10, log2
• 三角函數 sin, cos, tan
• 反三角函數 asin, acos, atan, atan2
• 雙曲函數 sinh, cosh, tanh
• 反雙曲函數 asinh, acosh, atanh
有一些不太常用的數學函數:
• 貝塔函數 beta, lbeta
• 伽 瑪 函 數 gamma, lgamma, digamma, trigamma, tetragamma, pentagamma
• 組合數 choose, lchoose
• 富利葉變換和卷積 fft, mvfft, convolve
• 正交多項式 poly
• 求根 polyroot, uniroot
• 最優化 optimize, optim
• Bessel 函數 besselI, besselK, besselJ, besselY
• 樣條插值 spline, splinefun
• 簡單的微分 deriv
如果自己編寫的函數沒有考慮向量化問題,可以用 Vectorize() 函數將其轉換成向量化版本。
sort(x) 返回排序結果。rev(x) 返回把各元素排列次序反轉后的結果。order(x) 返回排序用的下標。如
x <- c(33, 55, 11) sort(x) ## [1] 11 33 55 rev(sort(x)) ## [1] 55 33 11 order(x) ## [1] 3 1 2 x[order(x)] ## [1] 11 33 55
返回:

order(x) 結果中 3 是 x 的最小元素 11 所在的位置下標,1 是 x 的 第二小元素 33 所在的位置下標,2 是 x 的最大元素 55 所在的位置下標。
sum(求和), mean(求平均值), var(求樣本方差), sd(求樣本標準差), min(求最小值), max(求最大值), range(求最小值和最大值) 等函數稱為統計函數,把輸入向量看作樣本,計算樣本統計量。prod 求所有元素的乘積。
cumsum 和 cumprod 計算累加和累乘積。如
cumsum(1:5)
返回:

cumprod(1:5)
返回:

其它一些類似函數有 pmax, pmin, cummax, cummin 等。
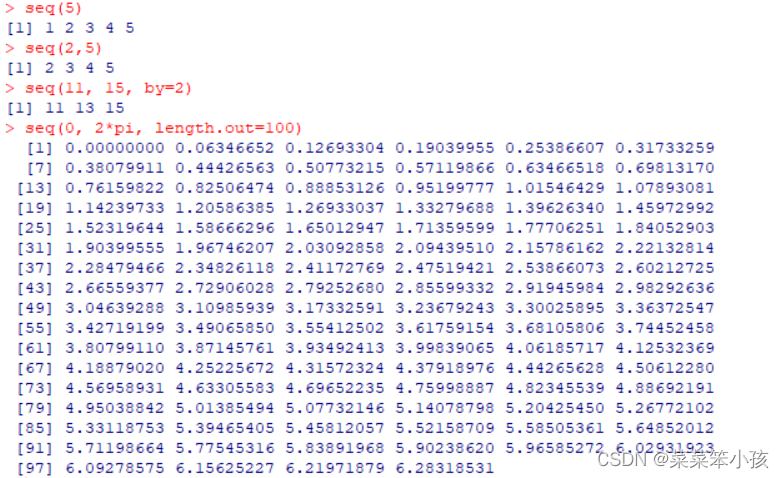
seq 函數是冒號運算符的推廣。比如
seq(5) seq(2,5) seq(11, 15, by=2) #產生從 0 到 2π 的等間隔序列,序列長度指定為 100 seq(0, 2*pi, length.out=100)
返回:
在使用變量名時次序可以顛倒,比如
seq(to=5, from=2)
返回:

rep() 函數用來產生重復數值。
為了產生一個初值為零的長度為 n 的向量,用 x <- rep(0, n) 。
rep(c(1,3), 2)
返回:

再比如:
rep(c(1,3), c(2,4))
把第一自變量的第一個元素 1 按照第二自變量中第一個元素 2 的次數重復,把第一自變量 中第二個元素 3 按照第二自變量中第二個元素 4 的次數重復,返回:

如 果 希 望 重 復 完 一 個 元 素 后 再 重 復 另 一 元 素, 用 each= 選 項, 比 如
rep(c(1,3), each=2)
返回:

復數常數表示如 3.5+2.4i, 1i。用函數 complex() 生成復數向量,指定實部和虛部。如
complex(c(1,0,-1,0), c(0,1,0,-1))
返回:

在 complex() 中可以用 mod 和 arg 指定模和輻角,如
complex(mod=1,arg=(0:3)/2*pi)
返回:

用 Re(z) 求 z 的實部,用 Im(z) 求 z 的虛部,用 Mod(z) 或 abs(z) 求 z 的模,用 Arg(z) 求 z 的輻角,用 Conj(z) 求 z 的共軛。 sqrt, log, exp, sin 等函數對復數也有定義,但是函數定義域在自變量為實數時可能有限制而復數無限制,這時需要區分自變量類型。如
sqrt(-1)sqrt(-1 + 0i)
返回:

1. 顯示 1 到 100 的整數的平方根和立方根(提示:立方根就是三分之一次 方)。
2. 設有 10 個人的小測驗成績為:
77 60 91 73 85 82 35 100 66 75
(1) 把這 10 個成績存入變量 x;
(2) 從小到大排序;
(3) 計算 order(x),解釋 order(x) 結果中第 3 項代表的意義。
(4) 計算這些成績的平均值、標準差、最小值、最大值、中位數。
3. 生成 [0, 1] 區間上等間隔的 100 個格子點存入變量 x 中。
以上是“R語言數據類型與相應運算的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





