溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下C#的并發機制有什么優點,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
由于我需要記錄的文件拷出信息并沒有回顯在UI的需要,因此也就沒考慮并發沖突的問題,在最初版本的實現中,我對于filesystemwatcher的回調事件,都是直接處理的,如下:
private void DeleteFileHandler(object sender, FileSystemEventArgs e)
{
if(files.Contains(e.FullPath))
{
files.Remove(e.FullPath);
//一些其它操作
}
}這個程序的處理效率在普通的辦公PC上如果同時拷出20個文件,那么在拷貝過程中,U盤監測程序的CPU使用率大約是0.7%。

但是一個非常偶然的機會,我使用了Event/Delegate的Invoke機制,結果發現這樣一個看似的廢操作,卻讓程序的CPU占用率下降到0.2%左右
private void UdiskWather_Deleted(object sender, FileSystemEventArgs e)
{
if(this.InvokeRequired)
{
this.Invoke(new DeleteDelegate(DeleteFileHandler), new object[] { sender,e }); }
else
{
DeleteFileHandler(sender, e);
}
}
在我最初的認識中.net中的Delegate機制在調用過程中是要進行拆、裝箱操作的,因此這不拖慢操作就不錯了,但實際的驗證結果卻相反。
這里先給出結論,Invoke能提升程序執行效率,其關鍵還是在于線程在多核之間切換的消耗要遠遠高于拆、裝箱的資源消耗,我們知道我們程序的核心就是操作files這個共享變量,每次在被檢測的U盤目錄中如果發生文件變動,其回調通知函數可能都運行在不同的線程,如下:
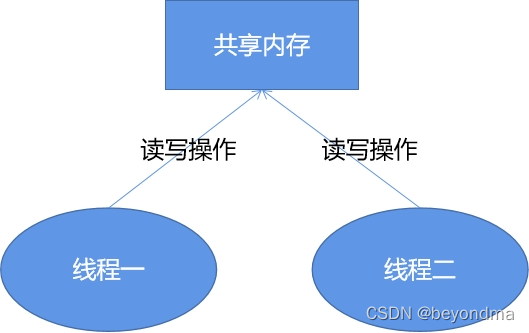
Invoke機制的背后其實就是保證所有對于files這個共享變量的操作,全部都是由一個線程執行完成的。

目前.Net的代碼都開源的,下面我們大致講解一下Invoke的調用過程,不管是BeginInvoke還是Invoke背后其實都是調用的MarshaledInvoke方法來完成的,如下:
public IAsyncResult BeginInvoke(Delegate method, params Object[] args) {
using (new MultithreadSafeCallScope()) {
Control marshaler = FindMarshalingControl();
return(IAsyncResult)marshaler.MarshaledInvoke(this, method, args, false);
}
}MarshaledInvoke的主要工作是創建ThreadMethodEntry對象,并把它放在一個鏈表里進行管理,然后調用PostMessage將相關信息發給要通信的線程,如下:
private Object MarshaledInvoke(Control caller, Delegate method, Object[] args, bool synchronous) {
if (!IsHandleCreated) {
throw new InvalidOperationException(SR.GetString(SR.ErrorNoMarshalingThread));
}
ActiveXImpl activeXImpl = (ActiveXImpl)Properties.GetObject(PropActiveXImpl);
if (activeXImpl != null) {
IntSecurity.UnmanagedCode.Demand();
}
// We don't want to wait if we're on the same thread, or else we'll deadlock.
// It is important that syncSameThread always be false for asynchronous calls.
//
bool syncSameThread = false;
int pid; // ignored
if (SafeNativeMethods.GetWindowThreadProcessId(new HandleRef(this, Handle), out pid) == SafeNativeMethods.GetCurrentThreadId()) {
if (synchronous)
syncSameThread = true;
}
// Store the compressed stack information from the thread that is calling the Invoke()
// so we can assign the same security context to the thread that will actually execute
// the delegate being passed.
//
ExecutionContext executionContext = null;
if (!syncSameThread) {
executionContext = ExecutionContext.Capture();
}
ThreadMethodEntry tme = new ThreadMethodEntry(caller, this, method, args, synchronous, executionContext);
lock (this) {
if (threadCallbackList == null) {
threadCallbackList = new Queue();
}
}
lock (threadCallbackList) {
if (threadCallbackMessage == 0) {
threadCallbackMessage = SafeNativeMethods.RegisterWindowMessage(Application.WindowMessagesVersion + "_ThreadCallbackMessage");
}
threadCallbackList.Enqueue(tme);
}
if (syncSameThread) {
InvokeMarshaledCallbacks();
} else {
//
UnsafeNativeMethods.PostMessage(new HandleRef(this, Handle), threadCallbackMessage, IntPtr.Zero, IntPtr.Zero);
}
if (synchronous) {
if (!tme.IsCompleted) {
WaitForWaitHandle(tme.AsyncWaitHandle);
}
if (tme.exception != null) {
throw tme.exception;
}
return tme.retVal;
}
else {
return(IAsyncResult)tme;
}
}Invoke的機制就保證了一個共享變量只能由一個線程維護,這和GO語言使用通信來替代共享內存的設計是暗合的,他們的理念都是 "讓同一塊內存在同一時間內只被一個線程操作" 。這和現代計算體系結構的多核CPU(SMP)有著密不可分的聯系,
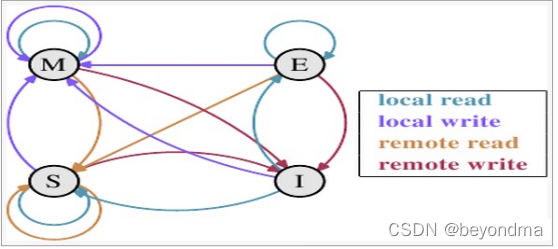
這里我們先來科普一下CPU之間的通信MESI協議的內容。我們知道現代的CPU都配備了高速緩存,按照多核高速緩存同步的MESI協議約定,每個緩存行都有四個狀態,分別是E(exclusive)、M(modified)、S(shared)、I(invalid),其中:
M:代表該緩存行中的內容被修改,并且該緩存行只被緩存在該CPU中。這個狀態代表緩存行的數據和內存中的數據不同。
E:代表該緩存行對應內存中的內容只被該CPU緩存,其他CPU沒有緩存該緩存對應內存行中的內容。這個狀態的緩存行中的數據與內存的數據一致。
I:代表該緩存行中的內容無效。
S:該狀態意味著數據不止存在本地CPU緩存中,還存在其它CPU的緩存中。這個狀態的數據和內存中的數據也是一致的。不過只要有CPU修改該緩存行都會使該行狀態變成 I 。
四種狀態的狀態轉移圖如下:
我們上文也提到了,不同的線程是有大概率是運行在不同CPU核上的,在不同CPU操作同一塊內存時,站在CPU0的角度上看,就是CPU1會不斷發起remote write的操作,這會使該高速緩存的狀態總是會在S和I之間進行狀態遷移,而一旦狀態變為I將耗費比較多的時間進行狀態同步。
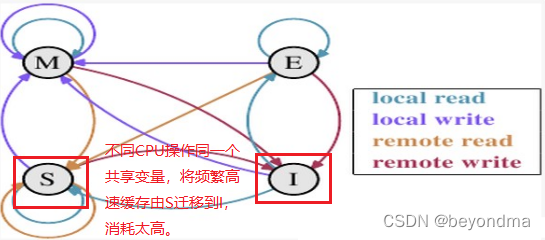
因此我們可以基本得出 this.Invoke(new DeleteDelegate(DeleteFileHandler), new object[] { sender,e }); ;這行看似無關緊要的代碼之后,無意中使files共享變量的維護操作,由多核多線程共同操作,變成了眾多子線程向主線程通信,所有維護操作均由主線程進行,這也使最終的執行效率有所提高。
在當前使用通信替代共享內存的大潮之下,鎖其實是最重要的設計。
我們看到在.Net的Invoke實現中,使用了兩把鎖lock (this) 與lock (threadCallbackList)。
lock (this) {
if (threadCallbackList == null) {
threadCallbackList = new Queue();
}
}
lock (threadCallbackList) {
if (threadCallbackMessage == 0) {
threadCallbackMessage = SafeNativeMethods.RegisterWindowMessage(Application.WindowMessagesVersion + "_ThreadCallbackMessage");
}
threadCallbackList.Enqueue(tme);
}在.NET當中lock關鍵字的基本可以理解為提供了一個近似于CAS的鎖(Compare And Swap)。CAS的原理不斷地把"期望值"和"實際值"進行比較,當它們相等時,說明持有鎖的CPU已經釋放了該鎖,那么試圖獲取這把鎖的CPU就會嘗試將"new"的值(0)寫入"p"(交換),以表明自己成為spinlock新的owner。偽代碼演示如下:
void CAS(int p, int old,int new)
{
if *p != old
do nothing
else
*p ← new
}基于CAS的鎖效率沒問題,尤其是在沒有多核競爭的情況CAS表現得尤其優秀,但CAS最大的問題就是不公平,因為如果有多個CPU同時在申請一把鎖,那么剛剛釋放鎖的CPU極可能在下一輪的競爭中獲取優勢,再次獲得這把鎖,這樣的結果就是一個CPU忙死,而其它CPU卻很閑,我們很多時候詬病多核SOC“一核有難,八核圍觀”其實很多時候都是由這種不公平造成的。
為了解決CAS的不公平問題,業界大神們又引入了TAS(Test And Set Lock)機制,個人感覺還是把TAS中的T理解為Ticket更好記一些,TAS方案中維護了一個請求該鎖的頭尾索引值,由"head"和"tail"兩個索引組成。
struct lockStruct{
int32 head;
int32 tail;
} ;"head"代表請求隊列的頭部,"tail"代表請求隊列的尾部,其初始值都為0。
最一開始時,第一個申請的CPU發現該隊列的tail值是0,那么這個CPU會直接獲取這把鎖,并會把tail值更新為1,并在釋放該鎖時將head值更新為1。
在一般情況下當鎖被持有的CPU釋放時,該隊列的head值會被加1,當其他CPU在試圖獲取這個鎖時,鎖的tail值獲取到,然后把這個tail值加1,并存儲在自己專屬的寄存器當中,然后再把更新后的tail值更新到隊列的tail當中。接下來就是不斷地循環比較,判斷該鎖當前的"head"值,是否和自己存儲在寄存器中的"tail"值相等,相等時則代表成功獲得該鎖。
TAS這類似于用戶到政務大廳去辦事時,首先要在叫號機取號,當工作人員廣播叫到的號碼與你手中的號碼一致時,你就獲取了辦事柜臺的所有權。
但是TAS卻存在一定的效率問題,根據我們上文介紹的MESI協議,這個lock的頭尾索引其實是在各個CPU之間共享的,因此tail和head頻繁更新,還是會引發調整緩存不停的invalidate,這會極大的影響效率。
因此我們看到在.Net的實現中干脆就直接引入了threadCallbackList的隊列,并不斷將tme(ThreadMethodEntry)加入隊尾,而接收消息的進程,則不斷從隊首獲取消息.
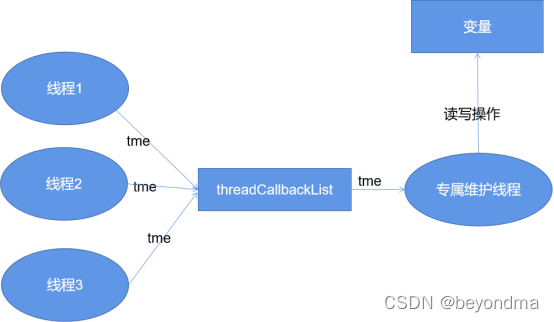
lock (threadCallbackList) {
if (threadCallbackMessage == 0) {
threadCallbackMessage = SafeNativeMethods.RegisterWindowMessage(Application.WindowMessagesVersion + "_ThreadCallbackMessage");
}
threadCallbackList.Enqueue(tme);
}當隊首指向這個tme時,消息才被發送,其實是一種類似于MAS的實現,當然MAS實際是為每個CPU都建立了一個專屬的隊列,和Invoke的設計略有不同,不過基本的思想是一致的。
以上是“C#的并發機制有什么優點”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





