溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章跟大家分析一下“Linux系統怎樣搭建hadoop集群”。內容詳細易懂,對“Linux系統怎樣搭建hadoop集群”感興趣的朋友可以跟著小編的思路慢慢深入來閱讀一下,希望閱讀后能夠對大家有所幫助。下面跟著小編一起深入學習“Linux系統怎樣搭建hadoop集群”的知識吧。
Hadoop,是一個分布式系統基礎架構,由Apache基金會開發。用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力高速運算和存儲。
簡單地說來,Hadoop是一個可以更容易開發和運行處理大規模數據的軟件平臺。該平臺使用的是面向對象編程語言Java實現的,具有良好的可移植性。
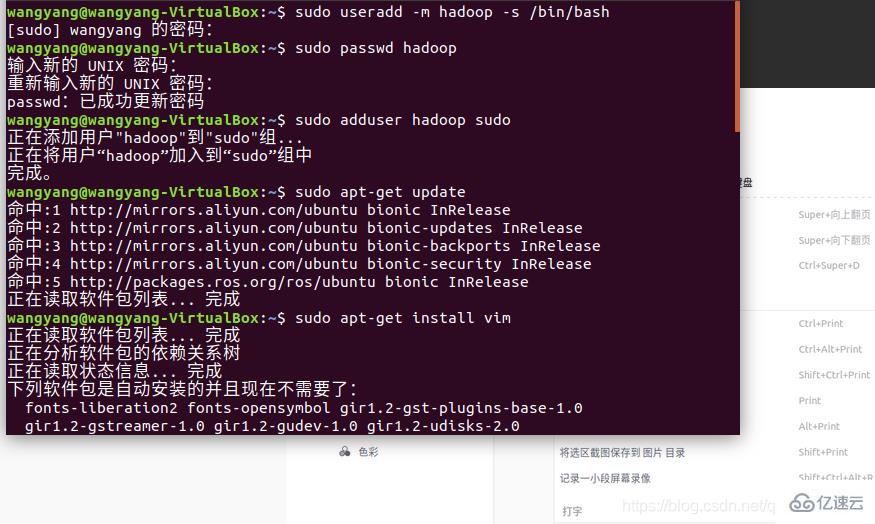
但是在剛開始就遇到了問題:由于我們下載的Hadoop和jdk在Windows下下載的,將文件共享進ubuntu時,只能共享到第一個創建的用戶(我也不知道為什么),而且ubuntu下網絡很慢,所以,我就沒有創建新的用戶,在原有的用戶上進行的安裝(后面運行成功證實是可以的)。
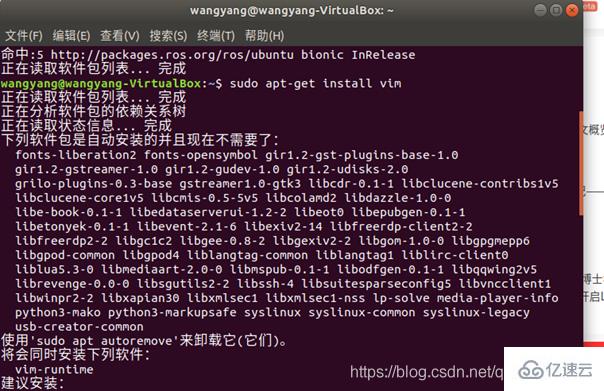
3.安裝SSH、配置SSH無密碼登陸:(提示(SSH首次登陸提示),輸入 yes 。然后按提示輸入密碼 hadoop,這樣就登陸到本機了)
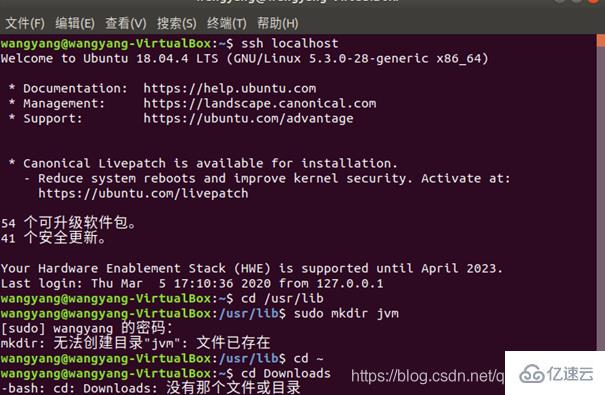
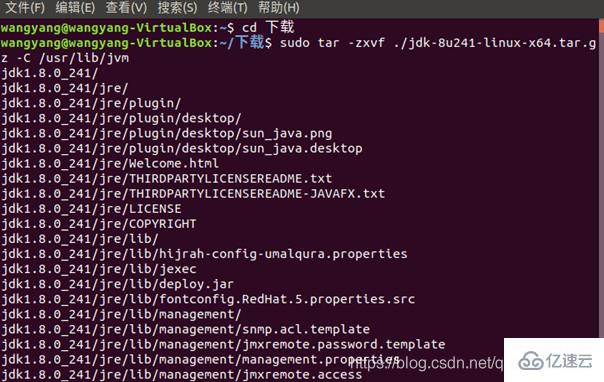
解壓過程:
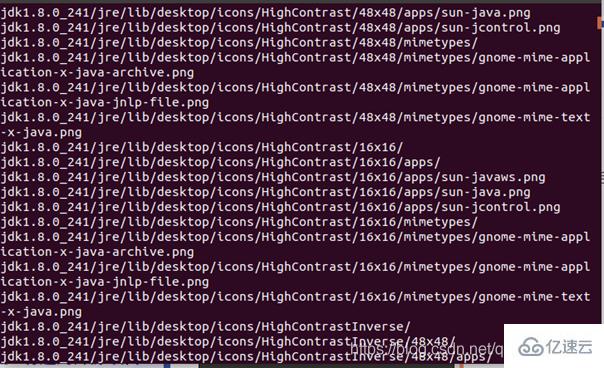
JDK文件解壓縮以后,可以執行如下命令到/usr/lib/jvm目錄查看一下:
繼續執行如下命令,設置環境變量:

下面命令使用vim編輯器打開了hadoop這個用戶的環境變量配置文件,在這個文件的開頭位置,添加如下幾行內容(注意自己的jdk 版本號):
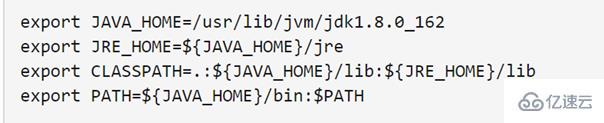
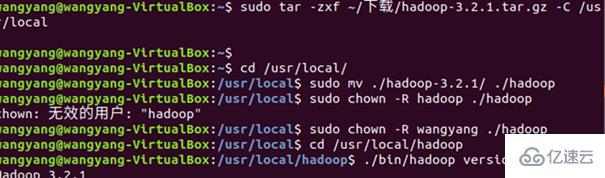
總體的命令:

運行例子:
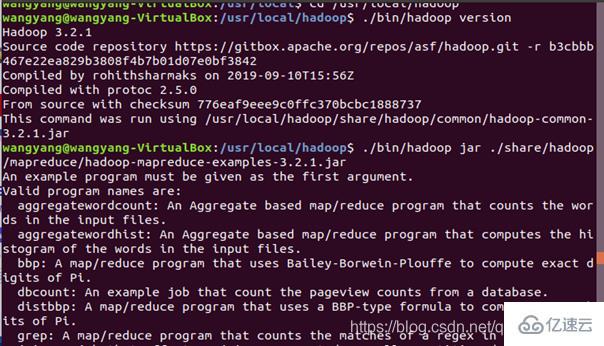
在此我們選擇運行 grep 例子,我們將 input 文件夾中的所有文件作為輸入,篩選當中符合正則表達式 dfs[a-z.]+ 的單詞并統計出現的次數,最后輸出結果到 output 文件夾中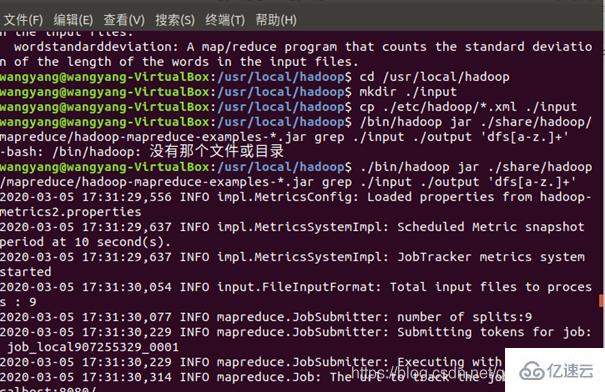
最后的結果與教程相符合:
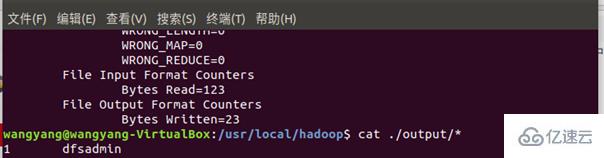
將 ./output 刪除
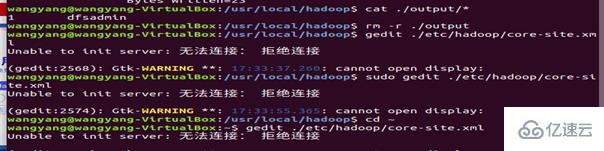
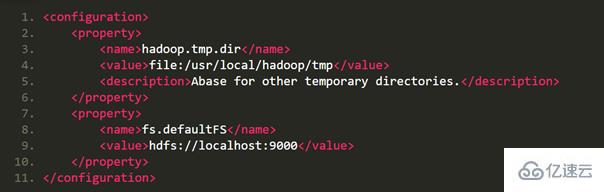
修改配置文件 core-site.xml (通過 gedit 編輯會比較方便: gedit ./etc/hadoop/core-site.xml),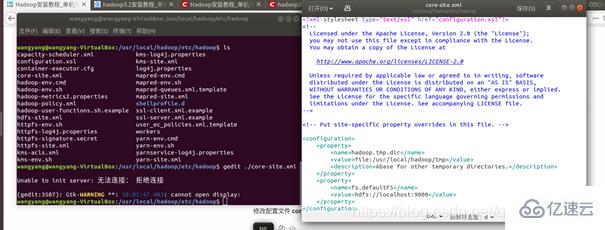
修改為:
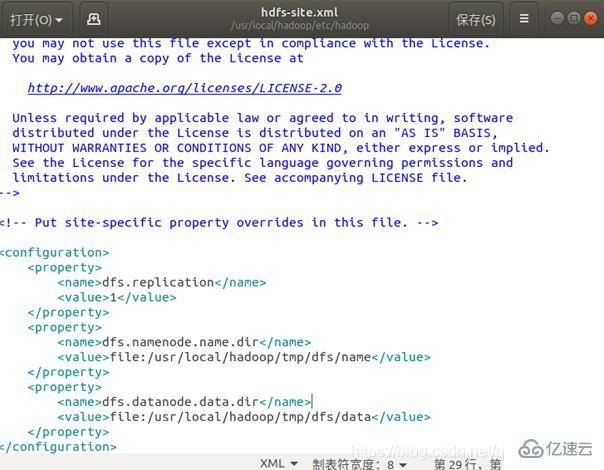
同樣的,修改配置文件 hdfs-site.xml:
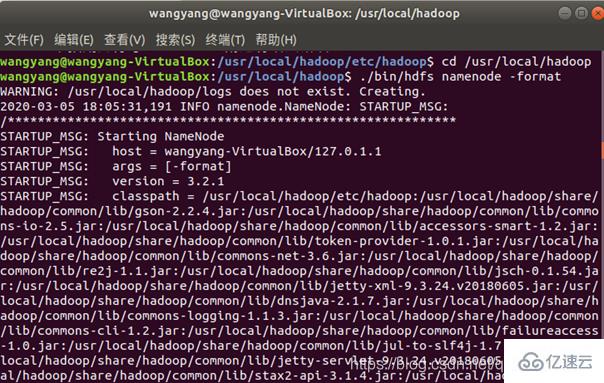
配置完成后,執行 NameNode 的格式化:
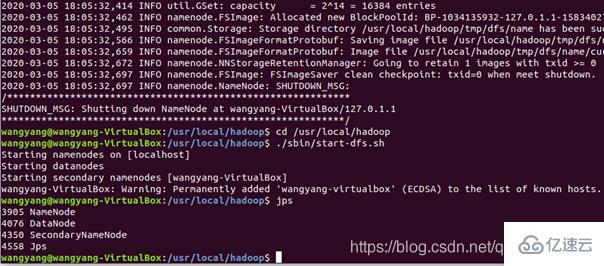
開啟 NameNode 和 DataNode 守護進程:
還好沒有教程中的錯誤:

網頁面中打開9870端口:
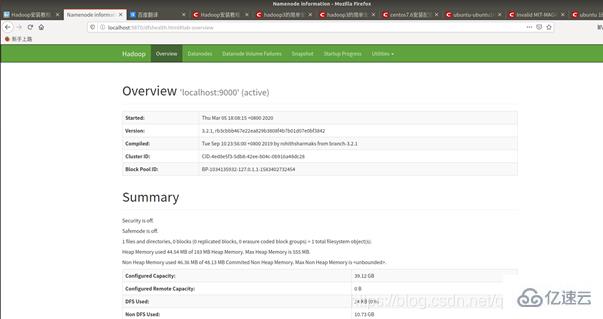
到這里表明已經成功!
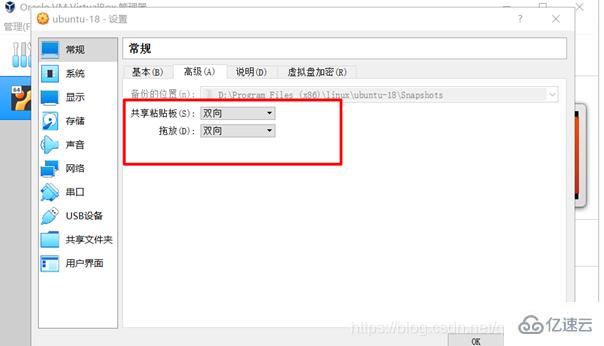
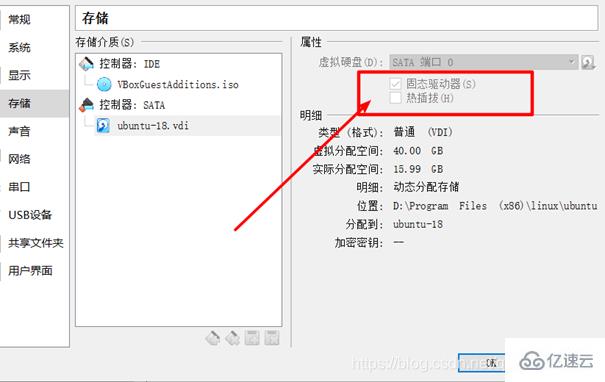
問題一:Ubuntu和Windows之間的文件傳輸,拖拽,共享粘貼板。解決辦法:安裝VBox的增強功能,以及設置如下的地方(自行百度):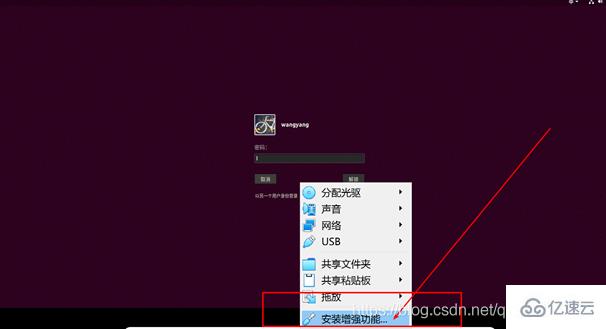
問題二:新用戶下,不能拖拽文件(就算是管理員也不行)沒有解決,因此沒有在新用戶hadoop下安裝,但是最后仍然是成功的
關于Linux系統怎樣搭建hadoop集群就分享到這里啦,希望上述內容能夠讓大家有所提升。如果想要學習更多知識,請大家多多留意小編的更新。謝謝大家關注一下億速云網站!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





