溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Linux系統如何安裝Flume”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Linux系統如何安裝Flume”這篇文章吧。
Flume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸的系統,是一個日志系統。
flume 是由 cloudera 軟件公司產出的可分布式日志收集系統,后與 2009 年被捐贈了 apache 軟件基金會, 為hadoop 相關組件之一。
Flume 是一種分布式 , 可靠且可用的服務 , 用于高效地收集 , 匯總和移動大量日志數據 。
它具有基于流式數據流的簡單而靈活的架構 。 它具有可靠的可靠性機制以及許多故障轉移和恢復機制 , 具有強大的容錯性和容錯能力。它使用一個簡單的可擴展數據模型,允許在線分析應用程序。
前提:已搭建好Hadoop
1 上傳壓縮包到虛擬機,解壓
tar -zxvf apache-flume-1.7.0-bin.tar.gz
2 修改名字便于使用
mv apache-flume-1.7.0-bin flume
3 修改flume-env.sh文件:
進入flume安裝目錄下的conf目錄,
cp flume-env.sh.template flume-env.sh vim flume-env.sh
在里面配置JAVA_HOME
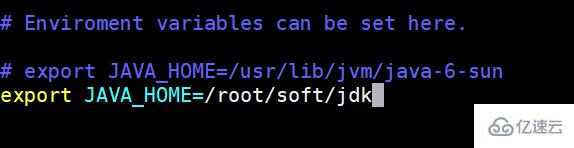
4 根據數據采集的需求配置采集方案,描述在配置文件中(文件名可任意自定義)
這里在flume的conf目錄下新建一個文件:vim netcat-logger.conf
配置如下方案:
# 定義這個agent中各組件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source組件:r1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # 描述和配置sink組件:k1 a1.sinks.k1.type = logger # 描述和配置channel組件,此處使用是內存緩存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之間的連接關系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
5 指定采集方案配置文件,在相應的節點上啟動flume agent去采集數據
./bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的配置文件所在目錄
-f conf/netcat-logger.con 指定我們所描述的采集方案
-n a1 指定我們這個agent的名字
6 測試
先要往agent采集監聽的端口上發送數據,讓agent有數據可采
隨便在一個能跟agent節點聯網的機器上(我這里就使用了本機,再建一個到本機的遠程連接)
telnet anget-hostname port 例如:telnet localhost 44444
但我的虛擬機中還沒有安裝telnet
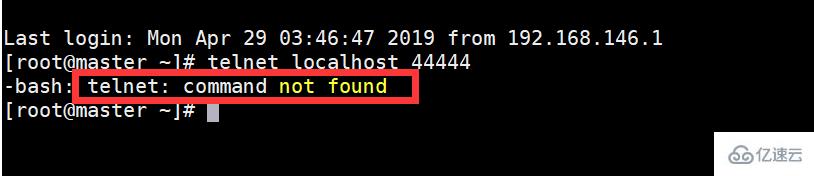
二、telnet的安裝
1 檢測telnet-server的rpm包是否安裝
rpm -qa telnet-server
若無輸出內容,則表示沒有安裝
2 若未安裝,則安裝telnet-server
yum install telnet-server
3 檢測telnet的rpm包是否安裝
rpm -qa telnet
若無輸出內容,則表示沒有安裝
4 若未安裝,則安裝telnet
yum install telnet
5 重新啟動xinetd守護進程
service xinetd restart
5 然后再次執行:telnet localhost 44444
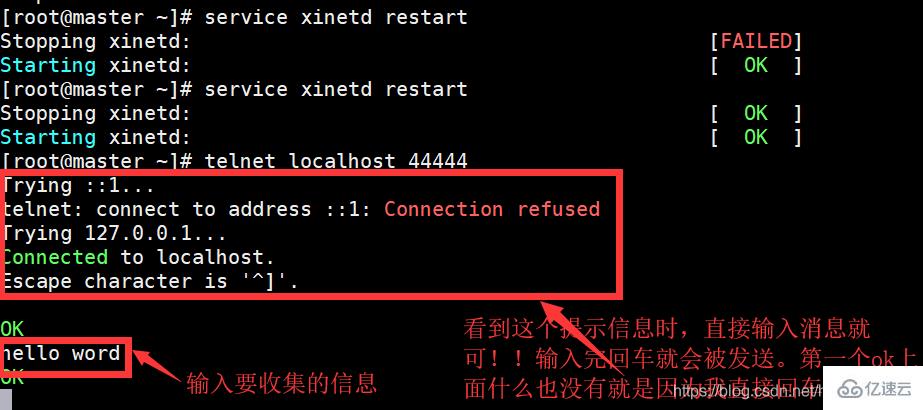
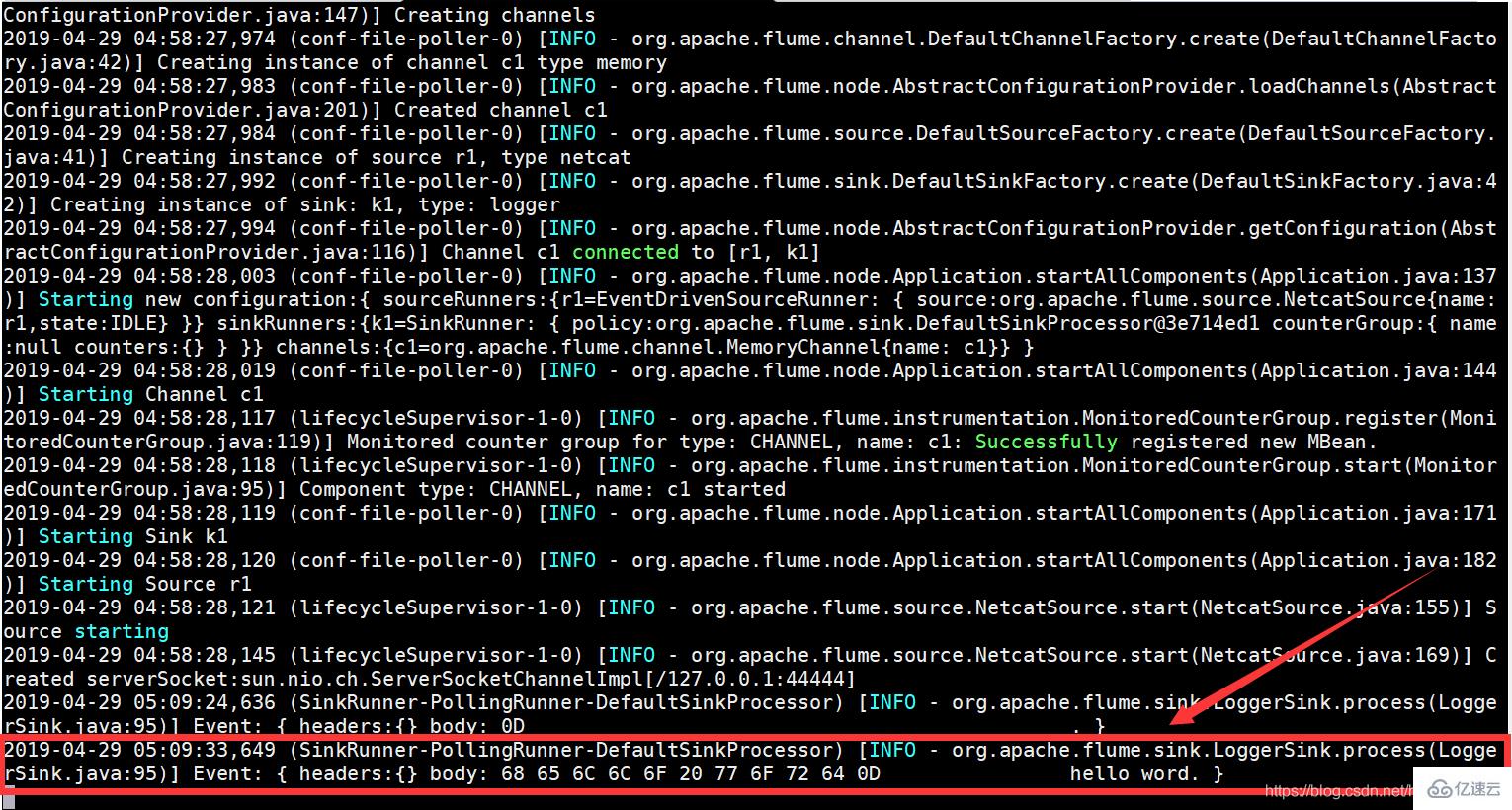
然后就可以看到flume已經接收到了要收集的數據
如何退出telnet呢???
以上是“Linux系統如何安裝Flume”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





