溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Linux的hexdump工具用來做什么”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Linux的hexdump工具用來做什么”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
hexdump是Linux下的一個二進制文件查看工具,它可以將二進制文件轉換為ASCII、八進制、十進制、十六進制格式進行查看。
hexdump [-bcCdovx] [-e format_string] [-f format_file] [-n length] [-s skip] file
新增一個文本文件,在test 文本中添加如下內容:
[root@node61 test]# cat testabcde ABCDE
1)最簡單的查看
[root@node61 test]# hexdump test0000000 6261 6463 0a65 4241 4443 0a45 000000c
第一列:表示文件文件偏移量
第二列:已兩個字節為一組的十六進制
通過上面的輸出,翻譯成文本為:badc0aeBADC0aE(注意:在Linux中換行符\n 的十六進制為0a,在windows中,換行為\r\n的十六進制編碼為:0d 0a),另:下圖為ASC碼表對應的進制編碼
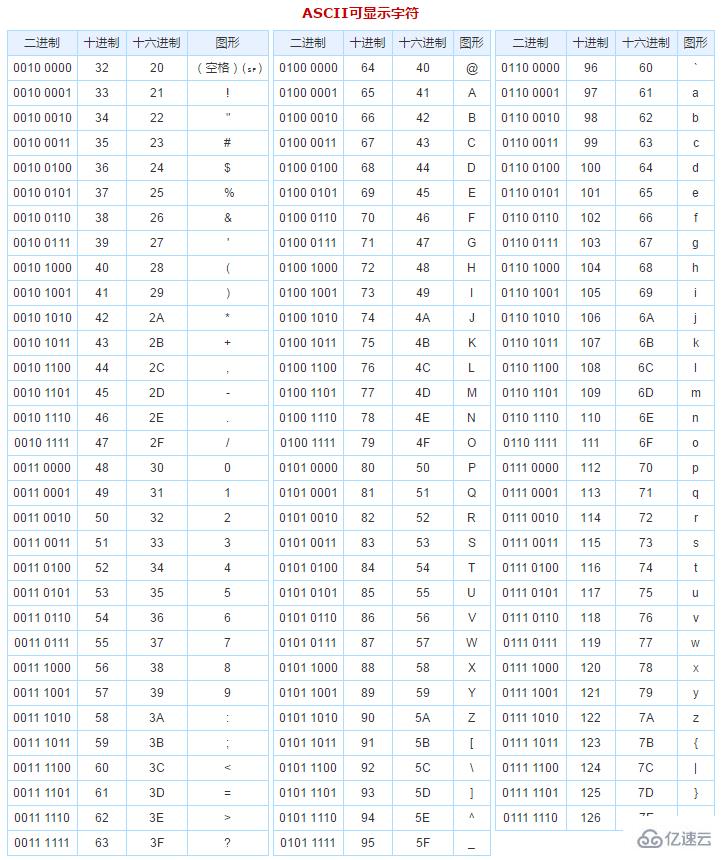
細心的讀者可能已經發現了,為什么翻譯成文本成倒序了呢?文本中的內容不是:abcde ABCDE 嗎?
其實這是X86的CPU架構所致,又進行了一番研究:字節序
字節序:其實就是字節的順序,這里是針對大于兩個字節來說,一個字節就沒有排序而言了,然而,在大部分的工作中,我們都很少直接和字節序打交道。
字節序分類兩類:Big-Endian 和Little-Endian
相關定義如下:
i) Little-Endian就是低位字節排放在內存的低地址端,高位字節排放在內存的高地址端。(X86 CPU系列采用的位序) ii) Big-Endian就是高位字節排放在內存的低地址端,低位字節排放在內存的高地址端。 iii) 網絡字節序:TCP/IP各層協議將字節序定義為Big-Endian,因此TCP/IP協議中使用的字節序通常稱之為網絡字節序。
下面的這個程序是用來判斷CPU采用的是哪種模式?
#includeint main(){
union w
{
int a;
char b;
} c;
c.a = 1;if (c.b==1){
printf("The CPU is Litle-Endian\n");
}else{
printf("The CPU is Big-Endian\n");
}return 0;
} /* end checkCPU*/
gcc -o checkCPU.o checkCPU.c
[root@node61 test]# ./checkCPU.oThe CPU is Litle-Endian本人本地虛擬機的是X86的小端模式的
至此上面使用hexdump為什么是順序是倒著的原因了
有沒有更加較便于方便的查看方式了?有,這也是較常用的方式,見下面的b)介紹;
b)以16進制和相應的ASCII字符顯示文件里的字符
[root@node61 test]# hexdump -C test #常用00000000 61 62 63 64 65 0a 41 42 43 44 45 0a |abcde.ABCDE.| 0000000c
這里既能顯示16進制也能顯示ascii碼
c)以偏移量格式輸出,參數 -s
[root@node61 test]# hexdump -C test00000000 61 62 63 64 65 0a 41 42 43 44 45 0a |abcde.ABCDE.| 0000000c [root@node61 test]# hexdump -C -s 6 test00000006 41 42 43 44 45 0a |ABCDE.| 0000000c
第一行的abcde換行 的字符都沒有了
其他hexdump還有很多的用法,具體可以參看man hexdump
讀到這里,這篇“Linux的hexdump工具用來做什么”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





