溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了Java中Elasticsearch核心原理是什么,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶大家一起來研究并學習一下“Java中Elasticsearch核心原理是什么”這篇文章吧。
Elasticsearch(以下稱之為ES)是一款基于Lucene的分布式全文搜索引擎,擅長海量數據存儲、數據分析以及全文檢索查詢,它是一款非常優秀的數據存儲與數據分析中間件,廣泛應用于日志分析以及全文檢索等領域,目前很多大廠都基于Elasticsearch開發了自己的存儲中間件以及數據分析平臺。
Lucene是Apache下的一個子項目,是一個開放源代碼的全文檢索引擎工具包,但它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,它是ES實現全文檢索的核心基礎,索引文檔以及搜索索引的的核心流程都是在Lucene中完成的。

我們都說ES是面向document的,這句話什么意思呢?實際就是表示ES是基于document進行數據操作的,操作主要包括數據搜索以及索引(這里的索引時數據寫入的意思)。因此可以說document是ES的基礎數據結構,它會被序列化之后保存到ES中。那么這個document到底是個什么東東呢?相信大家都對Mysql還是比較熟悉的,因此我們用Mysql中的數據庫與表的概念與ES的index進行對比,可能并不是十分的恰當和吻合,但是可以有助于大家對于這些概念的理解。另外type也在ES6.x版本之后逐漸取消了。
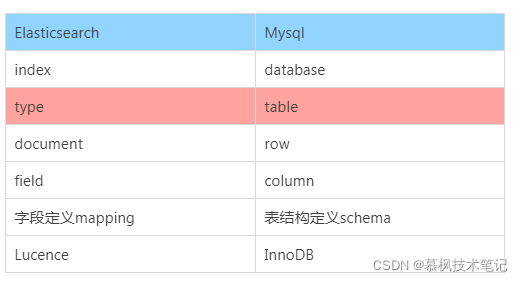
在ES之前的版本中,是有type這個概念的,類比數據庫中的表,那上文中所說的document就會放在type中。但是在ES后面的版本中為了提高數據存儲的效率逐漸取消了type,因此index實際上在現在的ES中既有庫的概念也有表的概念。簡單理解就是index就是文檔的容器,它是一類文檔的集合,但是這里需要注意的是index是邏輯空間的分類,實際數據是存在物理空間的分片上的。

另外需要說明的是,在ES中索引是有不同上下文含義的,它既可以是名詞也可以是動詞。索引為名詞是就是上文中提到的它是document的集合,索引為動詞的時候表示將document數據保存到ES中,也就是數據寫入。
在ES中,為了屏蔽語言的交互差異,ES直接對外的交互都是通過Rest API進行的。
我們都知道索引存在的意義就是為了加速數據的查詢。在關系型數據庫中如果沒有索引的話,為了查找數據我們需要每條數據去進行比對,運氣不好的話可能需要掃描全表才能查找到想要的數據。以Mysql為例,它使用了B+樹作為索引來加速數據的查詢。假設有這樣的一種場景,周末在路上逛的時候突然聽到一首非常好聽的歌曲,你記住了其中兩句歌詞,想著趕快拿手機到QQ音樂中查一下是什么歌。如果你是QQ音樂的程序猿,你該怎么實現根據歌詞查詢歌曲的功能呢? 用B+樹作為索引行不行呢?全文索引就是需要支持對大文本進行索引的,從空間上來說 B+ 樹不適合作為全文索引,同時 B+ 樹因為每次搜索都是從根節點開始往下搜索,所以會遵循最左匹配原則,而我們使用全文搜索時,往往不會遵循最左匹配原則,所以可能會導致索引失效。這時候倒排索引就派上用場了。 所謂正排索引就像書中的目錄一樣,根據頁碼查詢內容,但是倒排索引確實相反的,它是通過對內容的分詞,建立內容到文檔ID的關聯關系。這樣在進行全文檢索的時候,根據詞典的內容便可以精確以及模糊查詢,非常符合全文檢索的要求。
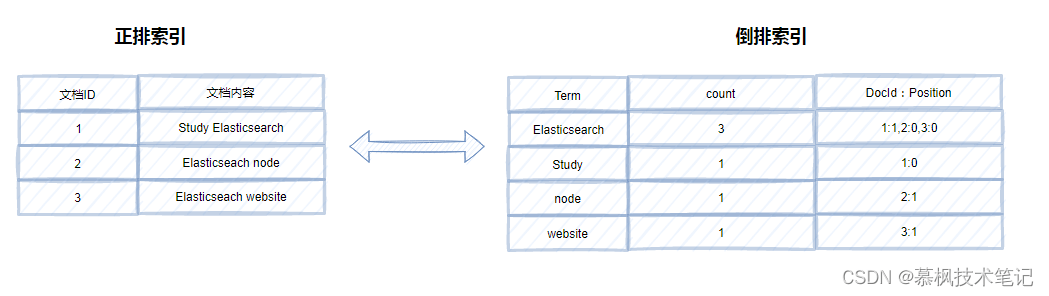
倒排索引的結構主要包括了兩大部分一個是Term Dictionary(單詞詞典),另一個是Posting List(倒排列表)。Term Dictionary(單詞詞典)記錄了所用文檔的單詞以及單詞和倒排列表的關系。Posting List(倒排列表)則是記錄了term在文檔中的位置以及其他信息,主要包括文檔ID,詞頻(term在文檔中出現的次數,用來計算相關性評分),位置以及偏移(實現搜索高亮)。
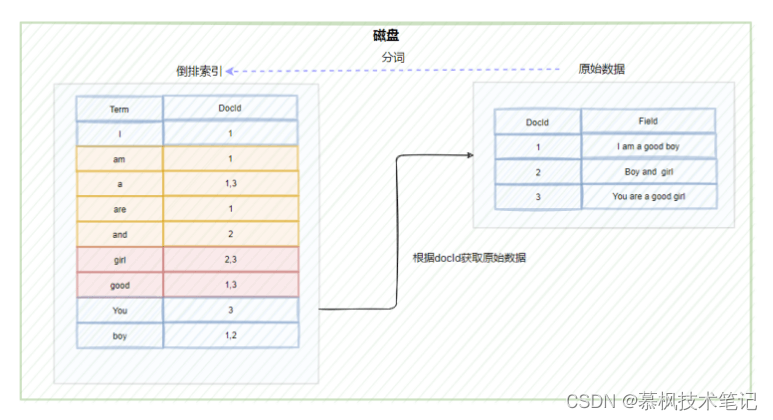
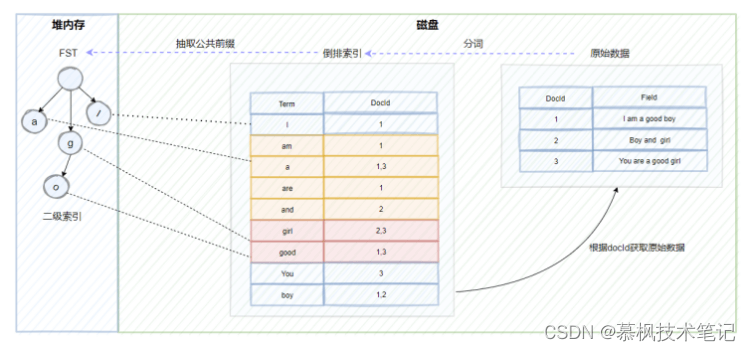
如上文所述,在進行全文檢索的時候,通過倒排索引中term與docId的關聯關系獲取到原始數據。但是這里有一個問題,ES底層依賴Lucene實現倒排索引的,因此在進行數據寫入的時候,Lucene會為原始數據中的每個term生成對應的倒排索引,因此造成的結果就是倒排索引的數據量就會很大。而倒排索引對應的倒排表文件是存儲在硬盤上的。如果每次查詢都直接去磁盤中讀取倒排索引數據,在通過獲取的docId再去查詢原始數據的話,肯定會造成多次的磁盤IO,嚴重影響全文檢索的效率。因此我們需要一種方式可以快速定位到倒排索引中的term。大家想想使用什么方式比較好呢?可以考慮HashMap, TRIE, Binary Search Tree或者Tenary Search Tree等數據結構,實際上Lucene實際是使用了FST(Finite State Transducer)有限狀態傳感器來實現二級索引的設計,它其實就是一種有限狀態機。
我們先來看下 trie樹的結構,在Lucene中是這樣做的,將倒排索引中具有公共前綴的term組成一個block,如下圖所示的cool以及copy,它們擁有co的公共前綴,按照類似前綴樹的邏輯來構成trie樹,對應節點中攜帶block的首地址。我們來分析下trie樹相比hashmap有什么優點?hashmap實現的是精準查找,但是trie樹不僅可以實現精準查找,另外由于其公共前綴的特性還可以實現模糊查找。那我們再看trie樹有什么地方可以再進行優化的地方?
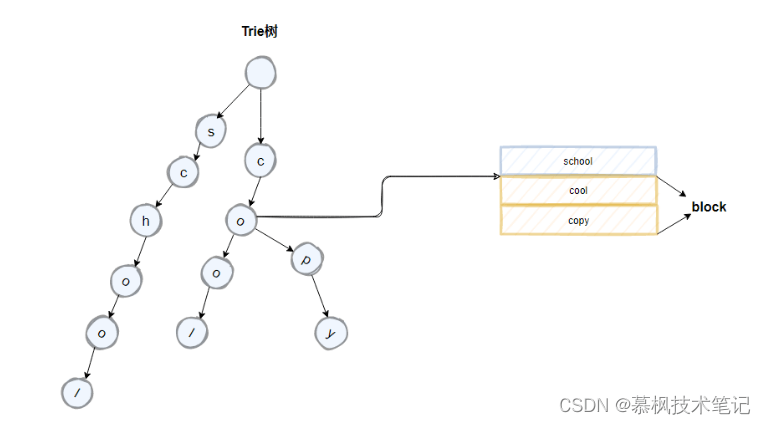
如上如所示,term中的school以及cool的后面字符是一致的,因此我們可以通過將原先的trie樹中的后綴字符進行合并來進一步的壓縮空間。優化后的trie樹就是FST。
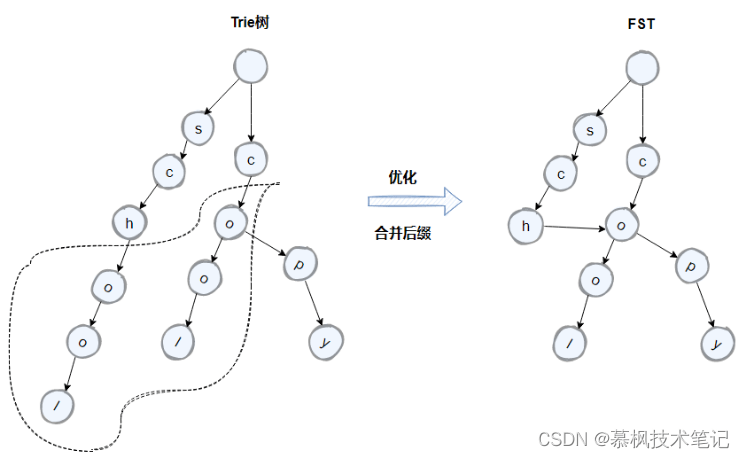
因此通過建立FST這個二級索引,可以實現倒排索引的快速定位,不需要經過多次的磁盤IO,搜索效率大大提高了。不過需要注意的是FST是存儲在堆內存中的,而且是常駐內存,大概占用50%-70%的堆內存,因此這里也是我們在生產中可以進行堆內存優化的地方。
為了增強ES的數據存儲可靠性以及高可用,ES支持進行集群部署,集群后的ES即便是某些節點出現故障,也不會導致真個ES集群不可用,同時通過水平擴容增強了ES的數據存儲能力。
所謂的節點實際就是ES的實例,我們通常在一臺服務器部署一個ES實例,其實就是一個Java進程。雖然都是ES實例,但是實際上的ES集群,不同節點承擔著不同的能力角色,有的是data node,主要負責保存分片的數據的,承擔著數據橫向擴展的重要作用,有的是coordinating node負責將用戶請求進行轉發以及將查詢的結果進行合并返回。當然還有master節點,負責對真個集群狀態進行管理和維護。
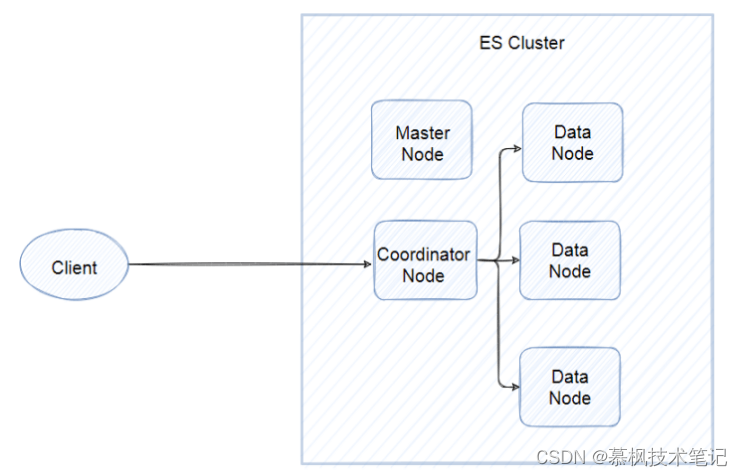
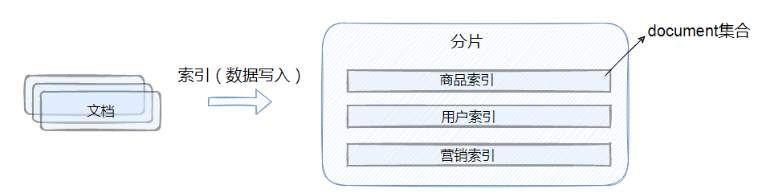
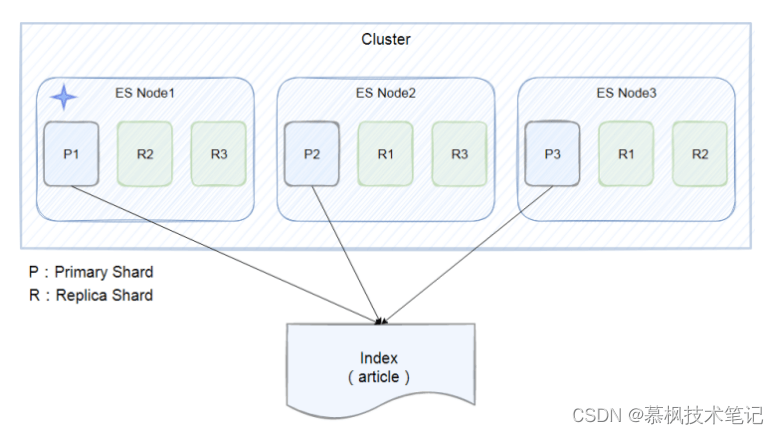
單個ES節點的數據存儲畢竟有限,沒法實現海量數據的存儲要求。那么怎么才能滿足海量數據的存儲要求呢?一個核心思想就是拆分,比如總共10億條數據,如果都放在一個節點中不僅查詢以及數據寫入的速度回很慢,頁存在單點問題。在傳統關系型數據庫中,采用分庫分表的方式,用更多的數據庫實例來承接大量的數據存儲。那么在ES中,也是采取類似的設計思想,既然一個ES的實例存在數據存儲的上線,那么就用多個實例來進行存儲。在每個實例中存在的數據集合就是分片。如下圖所示,index被切分成三個分片,三個分片分別存儲在三個ES實例中,同時為了提升數據的高可用性,每個主分片都有兩個副本分片,這些副本分片是主分片的數據拷貝。
put /article
{
"settings": {
"number_of_shards":3,
"number_of_replicas":3
}
}
這里需要注意的是,分片不是隨意進行設定的,而是需要根據實際的生產環境提前進行數據存儲的容量規劃,否則分片設置的過大或者過小都會影響ES集群的整體性能。如果分片設置的過小,那么單個分片的數據量可能會很大,影響數據檢索效率,也會影響數據的橫向擴展。如果分片設置的過大就會影響搜索結果的數據相關性評分,影響數據檢索的準確性。
1. 簡單,只需理解基本的概念,就可以編寫適合于各種情況的應用程序;2. 面向對象;3. 分布性,Java是面向網絡的語言;4. 魯棒性,java提供自動垃圾收集來進行內存管理,防止程序員在管理內存時容易產生的錯誤。;5. 安全性,用于網絡、分布環境下的Java必須防止病毒的入侵。6. 體系結構中立,只要安裝了Java運行時系統,就可在任意處理器上運行。7. 可移植性,Java可以方便地移植到網絡上的不同機器。8.解釋執行,Java解釋器直接對Java字節碼進行解釋執行。
以上就是關于“Java中Elasticsearch核心原理是什么”的內容,如果該文章對您有所幫助并覺得寫得不錯,勞請分享給您的好友一起學習新知識,若想了解更多相關知識內容,請多多關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





