溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1、一次輸入輸出的步驟:
1)等待數據就緒
2)數據搬遷
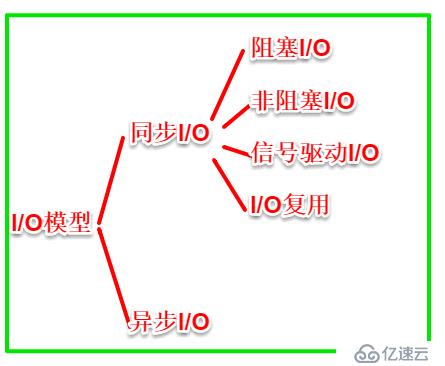
2、5種I/O模型
1)阻塞I/O模型:
應用程序調用一個I/O函數,導致應用程序阻塞,等待數據準備好。如果數據沒有準備好,一直等待。數據準備好了,從內核拷貝到用戶空間,I/O函數返回成功指示。
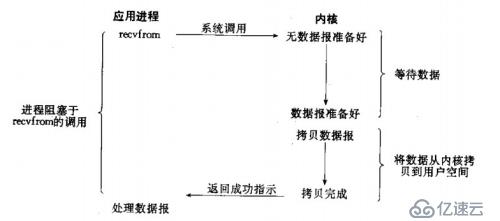
2)非阻塞I/O:
我們把一個套接口設置為非阻塞就是告訴內核,當所請求的I/O操作無法完成時,不要將進程睡眠,而是返回一個錯誤。這樣我們的I/O操作函數將不斷的測試數據是否已經準備好,如果沒有準備好,繼續測試,直到數據準備好為止。在這個不斷測試的過程中,會大量的占用CPU的時間。
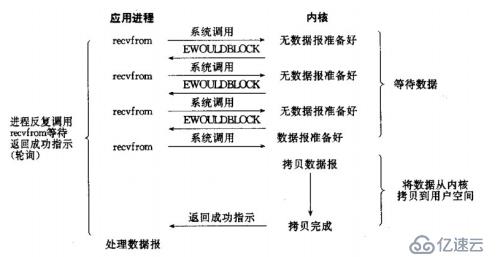
3)I/O復用模型:
I/O復用模型會用到select或者poll函數,這兩個函數也會使進程阻塞,但是和阻塞I/O 所不同的的,這兩個函數可以同時阻塞多個I/O操作。而且可以同時對多個讀操作,多個寫操作的I/O函數進行檢測,直到有數據可讀或可寫時,才真正調用I/O操作函數。
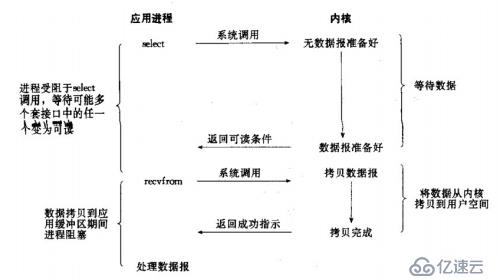
相比非阻塞IO模型,在多路復用IO模型中,會有一個線程不斷去輪詢多個socket的狀態(因為在多路復用IO模型中,只需要使用一個線程就可以管理多個socket,系統不需要建立新的進程或者線程,也不必維護這些線程和進程,所以它大大減少了資源占用)。
另外多路復用IO為何比非阻塞IO模型的效率高是因為在非阻塞IO中,不斷地詢問socket狀態是通過用戶線程去進行的,而在多路復用IO中,輪詢每個socket狀態是內核在進行的,這個效率要比用戶線程要高的多。
4)信號驅動I/O模型:
首先我們允許套接口進行信號驅動I/O,并安裝一個信號處理函數,進程繼續運行并不阻塞。當數據準備好時,進程會收到一個SIGIO信號,可以在信號處理函數中調用I/O操作函數處理數據。

以上I/O的數據搬遷動作是一樣的,只是等待方式不一樣,叫做同步I/O(所有動作是自己操作的)。
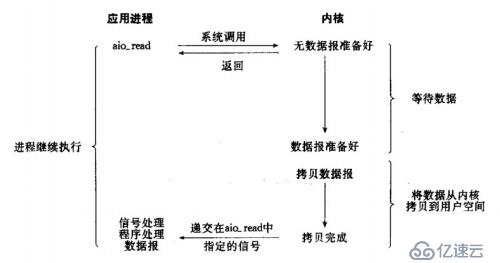
5)異步I/O模型:
調用aio_read函數,告訴內核描述字,緩沖區指針,緩沖區大小,文件偏移以及通知的方式,然后立即返回。當內核將數據拷貝到緩沖區后,再通知應用程序。
3、總結
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





