溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
PageRank簡單介紹:

其值是通過其他值得指向值所決定,具體例子如下:
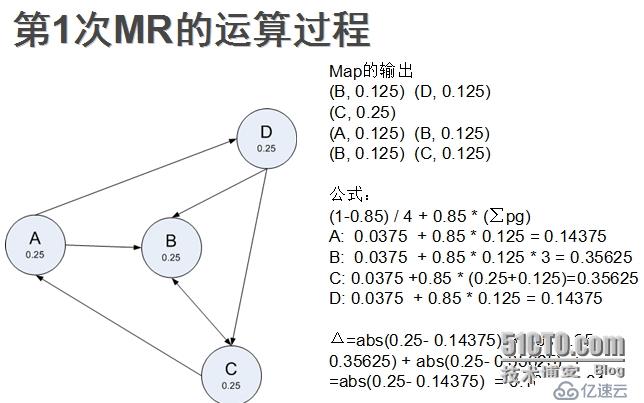
第一部分:
對應于每個mapReduce的計算:
由mapper算出每個點所指節點的分值,由reduce整個key相同的,由公式算出。
三角號表示的是迭代兩次之間計算的差值,若小于某個值則計算完成,求的每個點的pagerank值。
自我實現的代碼:如下
輸入的數據分為:
input1.txt
A,B,D
B,C
C,A,B
D,B,C
表示每行第一個點所指向的節點,在reducer的setup會用到,構建hashmap供使用。
input2.txt
A,0.25,B,D
B,0.25,C
C,0.25,A,B
D,0.25,B,C
中間多的數字,表示當前每個節點的pagerank值,其文件可無,因為可以由上面的文件計算生成,有四個節點,即1/4。
自我實現的代碼:
package bbdt.steiss.pageRank;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class PageRank {
public static class PageMapper extends Mapper<LongWritable, Text, Text, Text>{
private Text averageValue = new Text();
private Text node = new Text();
@Override
//把每行數據的對應節點的分pagerank找出,并輸出,當前節點的值除以指向節點的總數
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String string = value.toString();
String [] ss = string.split(",");
int length = ss.length;
double pageValue = Double.parseDouble(ss[1]);
double average = pageValue/(length-2);
averageValue.set(String.valueOf(average));
int i = 2;
while(i<=length-1){
node.set(ss[i]);
context.write(node,averageValue);
i++;
}
}
}
public static class PageReducer extends Reducer<Text, Text, Text, Text>{
private HashMap<String, String> content;
private Text res = new Text();
//reducer工作前,key相同的會分組分在一組,用迭代器操作,從總的圖中找到所有該節點的分pagerank值
//利用公式計算該pagerank值,輸出。因為下一次要用,因此輸出可以湊近一些,把結果都放在value里輸出
@Override
protected void reduce(Text text, Iterable<Text> intIterable,
Context context)
throws IOException, InterruptedException {
double sum = 0.0;
double v = 0.0;
for (Text t : intIterable) {
v = Double.parseDouble(t.toString());
sum = sum + v;
}
double a = 0.85;
double result = (1-a)/4 + a*sum;
String sRes = String.valueOf(result);
String back = content.get(text.toString());
String front = text.toString();
String comp = front + "," + sRes + back;
res.set(comp);
context.write(null,res);
}
@Override
//reducer的初始化時,先把節點對應文件的數據,存在hashmap中,也就是content中,供每次reduce方法使用,相當于數據庫的作用
//方便查詢
protected void setup(Context context)
throws IOException, InterruptedException {
URI[] uri = context.getCacheArchives();
content = new HashMap<String, String>();
for(URI u : uri)
{
FileSystem fileSystem = FileSystem.get(u.create("hdfs://hadoop1:9000"), context.getConfiguration());
FSDataInputStream in = null;
in = fileSystem.open(new Path(u.getPath()));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in));
String line;
while((line = bufferedReader.readLine())!=null)
{
int index = line.indexOf(",");
String first = line.substring(0,index);
String last = line.substring(index,line.length());
content.put(first, last);
}
}
}
}
public static void main(String[] args) throws Exception{
//接受路徑文件
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
Path cachePath = new Path(args[2]);
double result = 100;
int flag = 0;
//制定差值多大時進入循環
while(result>0.1)
{
if(flag == 1)
{
//初次調用mapreduce不操作這個
//這個是把mapreduce的輸出文件復制到輸入文件中,作為這次mapreduce的輸入文件
copyFile();
flag = 0;
}
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(PageRank.class);
job.setMapperClass(PageMapper.class);
job.setReducerClass(PageReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
job.addCacheArchive(cachePath.toUri());
outputPath.getFileSystem(configuration).delete(outputPath, true);
job.waitForCompletion(true);
String outpathString = outputPath.toString()+"/part-r-00000";
//計算兩個文件的各節點的pagerank值差
result = fileDo(inputPath, new Path(outpathString));
flag = 1;
}
System.exit(0);
}
//計算兩個文件的每個節點的pagerank差值,返回
public static double fileDo(Path inputPath,Path outPath) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop1:9000");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in1 = null;
FSDataInputStream in2 = null;
in1 = fs.open(inputPath);
in2 = fs.open(outPath);
BufferedReader br1 = new BufferedReader(new InputStreamReader(in1));
BufferedReader br2 = new BufferedReader(new InputStreamReader(in2));
String s1 = null;
String s2 = null;
ArrayList<Double> arrayList1 = new ArrayList<Double>();
ArrayList<Double> arrayList2 = new ArrayList<Double>();
while ((s1 = br1.readLine()) != null)
{
String[] ss = s1.split(",");
arrayList1.add(Double.parseDouble(ss[1]));
}
br1.close();
while ((s2 = br2.readLine()) != null)
{
String[] ss = s2.split(",");
arrayList2.add(Double.parseDouble(ss[1]));
}
double res = 0;
for(int i = 0;i<arrayList1.size();i++)
{
res = res + Math.abs(arrayList1.get(i)-arrayList2.get(i));
}
return res;
}
//將輸出文件復制到輸入文件中
public static void copyFile() throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop1:9000");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in1 = null;
in1 = fs.open(new Path("/output/part-r-00000"));
BufferedReader br1 = new BufferedReader(new InputStreamReader(in1));
//這里刪除需要打開hdfs在/input目錄下的權限操作,非常重要
//“hdfs dfs -chmod 777 /input”打開權限,這樣才可以刪除其下面的文件
fs.delete(new Path("/input/test2.txt"),true);
//建立一個新文件,返回流
FSDataOutputStream fsDataOutputStream = fs.create(new Path("/input/test2.txt"));
BufferedWriter bw1 = new BufferedWriter(new OutputStreamWriter(fsDataOutputStream));
String s1 = null;
//寫出并寫入
while ((s1 = br1.readLine()) != null)
{
bw1.write(s1);
bw1.write("\n");
}
bw1.close();
fsDataOutputStream.close();
br1.close();
in1.close();
}
}注意:
在本地操作hdfs時,進行文件的刪除和添加,需要打開hdfs的文件操作權限,
這里刪除需要打開hdfs在/input目錄下的權限操作,非常重要 “hdfs dfs -chmod 777 /input”打開權限,這樣才可以刪除其下面的文件
打開/input路徑的操作權限
第二部分
以上是自己實現的pagerank的算法;下面介紹一下別人的代碼
robby的代碼實現:
1.首先對節點定義節點類,用于存當前節點的pagerank值以及所指向的節點,存在一個數組中。
package org.robby.mr.pagerank;
import org.apache.commons.lang.StringUtils;
import java.io.IOException;
import java.util.Arrays;
//節點類,記錄的是當前節點的pagerank值和其指向的節點
public class Node {
private double pageRank = 0.25;
private String[] adjacentNodeNames;
//分割符號
public static final char fieldSeparator = '\t';
public double getPageRank() {
return pageRank;
}
public Node setPageRank(double pageRank) {
this.pageRank = pageRank;
return this;
}
public String[] getAdjacentNodeNames() {
return adjacentNodeNames;
}
//接受一個數組,復制在指向節點數組上
public Node setAdjacentNodeNames(String[] adjacentNodeNames) {
this.adjacentNodeNames = adjacentNodeNames;
return this;
}
public boolean containsAdjacentNodes() {
return adjacentNodeNames != null;
}
//這個方法是從pagerank值開始+后面的指向的節點
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(pageRank);
if (getAdjacentNodeNames() != null) {
sb.append(fieldSeparator)
.append(StringUtils
.join(getAdjacentNodeNames(), fieldSeparator));
}
return sb.toString();
}
//通過字符串建立一個node
public static Node fromMR(String value) throws IOException {
String[] parts = StringUtils.splitPreserveAllTokens(
value, fieldSeparator);
if (parts.length < 1) {
throw new IOException(
"Expected 1 or more parts but received " + parts.length);
}
Node node = new Node()
.setPageRank(Double.valueOf(parts[0]));
if (parts.length > 1) {
node.setAdjacentNodeNames(Arrays.copyOfRange(parts, 1,
parts.length));
}
return node;
}
}2.這個是mapper的實現
package org.robby.mr.pagerank;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//這里map的輸入時Text和Text類型,說明是兩個文本,因此主函數中應設置job的輸入類型格式為KeyValueTextInputFormat
public class Map
extends Mapper<Text, Text, Text, Text> {
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
//先把原始的數據輸出,供reduce找指向節點使用
context.write(key, value);
//傳入時,key是第一個節點,以制表符分割,后面是value
Node node = Node.fromMR(value.toString());
if(node.getAdjacentNodeNames() != null &&
node.getAdjacentNodeNames().length > 0) {
double outboundPageRank = node.getPageRank() /
(double)node.getAdjacentNodeNames().length;
for (int i = 0; i < node.getAdjacentNodeNames().length; i++) {
String neighbor = node.getAdjacentNodeNames()[i];
outKey.set(neighbor);
Node adjacentNode = new Node()
.setPageRank(outboundPageRank);
outValue.set(adjacentNode.toString());
System.out.println(
" output -> K[" + outKey + "],V[" + outValue + "]");
//這里輸出計算出的節點分pagerank值
context.write(outKey, outValue);
}
}
}
}
輸出的數據:例子
A 0.25 B D
B 0.125
D 0.125注意:
KeyValueTextInputFormat的輸入格式(Text,Text),對每行的文本內容進行處理,以第一個制表符作為分割,分為key和value傳入。
TextInputFormat的格式是(Longwritable,Text),以行標作為key,內容作為value處理;
3.reduce方法的實現
package org.robby.mr.pagerank;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class Reduce
extends Reducer<Text, Text, Text, Text> {
public static final double CONVERGENCE_SCALING_FACTOR = 1000.0;
public static final double DAMPING_FACTOR = 0.85;
public static String CONF_NUM_NODES_GRAPH = "pagerank.numnodes";
private int numberOfNodesInGraph;
public static enum Counter {
CONV_DELTAS
}
//reduce初始化時執行的方法,得到總節點個數,在conf對象里
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
numberOfNodesInGraph = context.getConfiguration().getInt(
CONF_NUM_NODES_GRAPH, 0);
}
private Text outValue = new Text();
public void reduce(Text key, Iterable<Text> values,
Context context)
throws IOException, InterruptedException {
System.out.println("input -> K[" + key + "]");
double summedPageRanks = 0;
Node originalNode = new Node();
for (Text textValue : values) {
System.out.println(" input -> V[" + textValue + "]");
Node node = Node.fromMR(textValue.toString());
//這里就是傳入的是原始數據
if (node.containsAdjacentNodes()) {
// the original node
//
originalNode = node;
} else {
//計算針對一個節點的pagerank總和
summedPageRanks += node.getPageRank();
}
}
double dampingFactor =
((1.0 - DAMPING_FACTOR) / (double) numberOfNodesInGraph);
double newPageRank =
dampingFactor + (DAMPING_FACTOR * summedPageRanks);
//計算差值
double delta = originalNode.getPageRank() - newPageRank;
//把原節點對象的pagerank改為新的
originalNode.setPageRank(newPageRank);
outValue.set(originalNode.toString());
System.out.println(
" output -> K[" + key + "],V[" + outValue + "]");
//把更改后的節點對象輸出
context.write(key, outValue);
int scaledDelta =
Math.abs((int) (delta * CONVERGENCE_SCALING_FACTOR));
System.out.println("Delta = " + scaledDelta);
//這個是計數器,mapreduce有很多計數器,自定義的要通過enum對象傳入建立和取值
//increment是增值的意思
context.getCounter(Counter.CONV_DELTAS).increment(scaledDelta);
}
}4.main函數的實現:
package org.robby.mr.pagerank;
import org.apache.commons.io.*;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.*;
import java.util.*;
public final class Main {
public static void main(String... args) throws Exception {
//傳入輸入文件的路徑,與輸出文件的路徑
String inputFile = args[0];
String outputDir = args[1];
iterate(inputFile, outputDir);
}
public static void iterate(String input, String output)
throws Exception {
//因為這個是在hadoop上運行的(hadoop jar ...),因此conf會自動配上集群上hadoop的hdfs的入口
//后面的文件可以直接找filesystem,即hdfs的文件操作類
Configuration conf = new Configuration();
Path outputPath = new Path(output);
outputPath.getFileSystem(conf).delete(outputPath, true);
outputPath.getFileSystem(conf).mkdirs(outputPath);
//建立輸入文件
Path inputPath = new Path(outputPath, "input.txt");
//建立文件,返回節點個數
int numNodes = createInputFile(new Path(input), inputPath);
int iter = 1;
double desiredConvergence = 0.01;
while (true) {
//path建立時,outputpath+后面的是文件路徑
Path jobOutputPath =
new Path(outputPath, String.valueOf(iter));
System.out.println("======================================");
System.out.println("= Iteration: " + iter);
System.out.println("= Input path: " + inputPath);
System.out.println("= Output path: " + jobOutputPath);
System.out.println("======================================");
//這里進行mapreduce
if (calcPageRank(inputPath, jobOutputPath, numNodes) <
desiredConvergence) {
System.out.println(
"Convergence is below " + desiredConvergence +
", we're done");
break;
}
inputPath = jobOutputPath;
iter++;
}
}
//這個類的作用是把file文件的內容加上pagerank值送到targetfile里
public static int createInputFile(Path file, Path targetFile)
throws IOException {
Configuration conf = new Configuration();
FileSystem fs = file.getFileSystem(conf);
int numNodes = getNumNodes(file);
double initialPageRank = 1.0 / (double) numNodes;
//fs調用create方法根據path對象建立文件,返回該文件流
OutputStream os = fs.create(targetFile);
//file文件的流迭代器
LineIterator iter = IOUtils
.lineIterator(fs.open(file), "UTF8");
while (iter.hasNext()) {
String line = iter.nextLine();
//獲取每行的內容
String[] parts = StringUtils.split(line);
//建立node對象
Node node = new Node()
.setPageRank(initialPageRank)
.setAdjacentNodeNames(
Arrays.copyOfRange(parts, 1, parts.length));
IOUtils.write(parts[0] + '\t' + node.toString() + '\n', os);
}
os.close();
return numNodes;
}
//獲取節點數量,也就是獲取文件的行數
public static int getNumNodes(Path file) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = file.getFileSystem(conf);
return IOUtils.readLines(fs.open(file), "UTF8").size();
}
//進行mapreduce運算
public static double calcPageRank(Path inputPath, Path outputPath, int numNodes)
throws Exception {
Configuration conf = new Configuration();
conf.setInt(Reduce.CONF_NUM_NODES_GRAPH, numNodes);
Job job = Job.getInstance(conf);
job.setJarByClass(Main.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//輸入的key和value都是文本,因此使用這個class,以第一個分隔符作為分割符號,分為key和value
job.setInputFormatClass(KeyValueTextInputFormat.class);
//map輸出定義下
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
if (!job.waitForCompletion(true)) {
throw new Exception("Job failed");
}
long summedConvergence = job.getCounters().findCounter(
Reduce.Counter.CONV_DELTAS).getValue();
double convergence =
((double) summedConvergence /
Reduce.CONVERGENCE_SCALING_FACTOR) /
(double) numNodes;
System.out.println("======================================");
System.out.println("= Num nodes: " + numNodes);
System.out.println("= Summed convergence: " + summedConvergence);
System.out.println("= Convergence: " + convergence);
System.out.println("======================================");
return convergence;
}
}注意:
這個是文件流操作的方法,使用 import org.apache.commons.io.IOUtils中的IOUtils類中的方法。
還有一個Arrays方法copyOfRange,可以返回數組的指定位置,返回一個數組
OutputStream os = fs.create(targetFile);
//file文件的流迭代器
LineIterator iter = IOUtils
.lineIterator(fs.open(file), "UTF8");
while (iter.hasNext()) {
String line = iter.nextLine();
String[] parts = StringUtils.split(line);
Node node = new Node()
.setPageRank(initialPageRank)
.setAdjacentNodeNames(
Arrays.copyOfRange(parts, 1, parts.length));
IOUtils.write(parts[0] + '\t' + node.toString() + '\n', os);
}使用readLines方法,返回的是一個String數組,每個單元里放的是每行的內容
IOUtils.readLines(fs.open(file), "UTF8").size();
TextOutPutFormat的輸出的鍵值對可以是任何類型,輸出是自動調用toString方法,把對象轉為字符串輸出。
使用stringUtils,截字符串為數組
String[] parts = StringUtils.splitPreserveAllTokens( value, fieldSeparator);
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





