溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、什么是Flume?
Flume 作為 cloudera 開發的實時日志收集系統,受到了業界的認可與廣泛應用。Flume 初始的發行版本目前被統稱為 Flume OG(original generation),屬于 cloudera。但隨著 FLume 功能的擴展,Flume OG 代碼工程臃腫、核心組件設計不合理、核心配置不標準等缺點暴露出來,尤其是在 Flume OG 的最后一個發行版本 0.94.0 中,日志傳輸不穩定的現象尤為嚴重,為了解決這些問題,2011 年 10 月 22 號,cloudera 完成了 Flume-728,對 Flume 進行了里程碑式的改動:重構核心組件、核心配置以及代碼架構,重構后的版本統稱為 Flume NG(next generation);改動的另一原因是將 Flume 納入 apache 旗下,cloudera Flume 改名為 Apache Flume。
Flume的特點:
Flume是一個分布式、可靠、和高可用的海量日志采集、聚合和傳輸的系統。支持在日志系統中定制各類數據發送方,用于收集數據;同時,Flume提供對數據進行簡單處理,并寫到各種數據接受方(比如文本、HDFS、Hbase等)的能力。
flume的數據流由事件(Event)貫穿始終。事件是Flume的基本數據單位,它攜帶日志數據(字節數組形式)并且攜帶有頭信息,這些Event由Agent外部的Source生成,當Source捕獲事件后會進行特定的格式化,然后Source會把事件推入(單個或多個)Channel中。你可以把Channel看作是一個緩沖區,它將保存事件直到Sink處理完該事件。Sink負責持久化日志或者把事件推向另一個Source。
Flume的可靠性
當節點出現故障時,日志能夠被傳送到其他節點上而不會丟失。Flume提供了三種級別的可靠性保障,從強到弱依次分別為:end-to-end(收到數據agent首先將event寫到磁盤上,當數據傳送成功后,再刪除;如果數據發送失敗,可以重新發送。),Store on failure(這也是scribe采用的策略,當數據接收方crash時,將數據寫到本地,待恢復后,繼續發送),Besteffort(數據發送到接收方后,不會進行確認)。
Flume的可恢復性:
還是靠Channel。推薦使用FileChannel,事件持久化在本地文件系統里(性能較差)。
Flume的一些核心概念:
Agent使用JVM 運行Flume。每臺機器運行一個agent,但是可以在一個agent中包含多個sources和sinks。
1. Client 生產數據,運行在一個獨立的線程。
2. Source 從Client收集數據,傳遞給Channel。
3. Sink 從Channel收集數據,運行在一個獨立線程。
4. Channel 連接 sources 和 sinks ,這個有點像一個隊列。
5. Events 可以是日志記錄、 avro 對象等。
Flume以agent為最小的獨立運行單位。一個agent就是一個JVM。單agent由Source、Sink和Channel三大組件構成,如下圖:
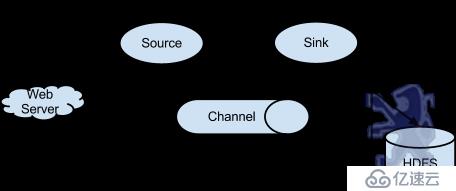
值得注意的是,Flume提供了大量內置的Source、Channel和Sink類型。不同類型的Source,Channel和Sink可以自由組合。組合方式基于用戶設置的配置文件,非常靈活。比如:Channel可以把事件暫存在內存里,也可以持久化到本地硬盤上。Sink可以把日志寫入HDFS, HBase,甚至是另外一個Source等等。Flume支持用戶建立多級流,也就是說,多個agent可以協同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,這也正是NB之處。如下圖所示:

二、Flume+Kafka+SparkStreaming應用場景:
1、Flume集群采集外部系統的業務信息,將采集后的信息發生到Kafka集群,最終提供Spark Streaming流框架計算處理,流處理完成后再將最終結果發送給Kafka存儲。
2、Flume集群采集外部系統的業務信息,將采集后的信息發生到Kafka集群,最終提供Spark Streaming流框架計算處理,流處理完成后再將最終結果發送給Kafka存儲,同時將最終結果通過Ganglia監控工具進行圖形化展示。
3、我們要做:Sparkstreaming 交互式的360度的可視化,Spark streaming交互式3D可視化UI;Flume集群采集外部系統的業務信息,將采集后的信息發生到Kafka集群,最終提供Spark Streaming流框架計算處理,流處理完成后再將最終結果發送給Kafka存儲,將最終結果同時存儲在數據庫(Mysql)、內存中間件(Redis、MemSQL)中,同時將最終結果通過Ganglia監控工具進行圖形化展示,架構如下圖:

三、Kafka數據寫入Spark Streaming有二種方式:
一種是Receivers,這個方法使用了Receivers來接收數據,Receivers的實現使用到Kafka高層次的消費者API,對于所有的Receivers,接收到的數據將會保存在Spark 分布式的executors中,然后由Spark Streaming啟動的Job來處理這些數據;然而,在默認的配置下,這種方法在失敗的情況下會丟失數據,為了保證零數據丟失,你可以在Spark Streaming中使用WAL日志功能,這使得我們可以將接收到的數據保存到WAL中(WAL日志可以存儲在HDFS上),所以在失敗的時候,我們可以從WAL中恢復,而不至于丟失數據。
另一種是DirectAPI,產生數據和處理數據的時候是在兩臺機器上?其實是在同一臺數據上,由于在一臺機器上有Driver和Executor,所以這臺機器要足夠強悍。
Flume集群將采集的數據放到Kafka集群中,Spark Streaming會實時在線的從Kafka集群中通過DirectAPI拿數據,可以通過Kafka中的topic+partition查詢最新的偏移量(offset)來讀取每個batch的數據,即使讀取失敗也可再根據偏移量來讀取失敗的數據,保證應用運行的穩定性和數據可靠性。
溫馨提示:
1、Flume集群數據寫入Kafka集群時可能會導致數據存放不均衡,即有些Kafka節點數據量很大、有些不大,后續會對分發數據進行自定義算法來解決數據存放不均衡問題。
2、個人強烈推薦在生產環境下用DirectAPI,但是我們的發行版,會對DirectAPI進行優化,降低其延遲。
總結:
實際生產環境下,搜集分布式的日志以Kafka為核心。
備注:
資料來源于:DT_大數據夢工廠(IMF傳奇行動絕密課程)
更多私密內容,請關注微信公眾號:DT_Spark
如果您對大數據Spark感興趣,可以免費聽由王家林老師每天晚上20:00開設的Spark永久免費公開課,地址YY房間號:68917580
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





