溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Node中集群的示例分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
Node 在 v0.8 時直接引入了 cluster 模塊,用以解決多核 CPU 的利用率問題,同時也提供了較完善的 API,用以處理進程的健壯性問題。
cluster 模塊調用 fork 方法來創建子進程,該方法與 child_process 中的 fork 是同一個方法。 cluster 模塊采用的是經典的主從模型,cluster 會創建一個 master,然后根據你指定的數量復制出多個子進程,可以使用cluster.isMaster 屬性判斷當前進程是 master 還是 worker (工作進程)。由 master 進程來管理所有的子進程,主進程不負責具體的任務處理,主要工作是負責調度和管理。
cluster 模塊使用內置的負載均衡來更好地處理線程之間的壓力,該負載均衡使用了 Round-robin 算法(也被稱之為循環算法)。當使用 Round-robin 調度策略時,master accepts() 所有傳入的連接請求,然后將相應的TCP請求處理發送給選中的工作進程(該方式仍然通過 IPC 來進行通信)。 官方使用實例如下所示
const cluster = require('cluster');
const cpuNums = require('os').cpus().length;
const http = require('http');
if (cluster.isMaster) {
for (let i = 0; i < cpuNums; i++){
cluster.fork();
}
// 子進程退出監聽
cluster.on('exit', (worker,code,signal) => {
console.log('worker process died,id',worker.process.pid)
})
} else {
// 給子進程標注進程名
process.title = `cluster 子進程 ${process.pid}`;
// Worker可以共享同一個 TCP 連接,這里是一個 http 服務器
http.createServer((req, res)=> {
res.end(`response from worker ${process.pid}`);
}).listen(3000);
console.log(`Worker ${process.pid} started`);
}其實,cluster 模塊由 child_process 和 net 模塊的組合應用,cluster 啟動時,會在內部啟動 TCP 服務器,在 cluster.fork() 子進程時,將這個 TCP 服務器端 socket 的文件描述符發送給工作進程。如果工作進程是通過 cluster.fork() 復制出來的,那么它的環境變量里就存在 NODE_UNIQUE_ID,如果工作進程中存在 listen() 偵聽網絡端口的調用,它將拿到文件描述符,通過 SO_REUSEADDR 端口重用,從而實現多個子進程共享端口。
fork:復制一個工作進程后觸發該事件;
online:復制好一個工作進程后,工作進程主動發送一條 online 消息給主進程,主進程收到消息后,觸發該事件;
listening:工作進程中調用 listen() (共享了服務器端 Socket)后,發送一條 listening 消息給主進程,主進程收到消息后,觸發該事件;
disconnect:主進程和工作進程之間 IPC 通道斷開后會觸發該事件;
exit:有工作進程退出時會觸發該事件;
setup:cluster.setupMaster() 執行完后觸發該事件;
這些事件大多跟 child_process 模塊的事件相關,在進程間消息傳遞的基礎上完成的封裝。
cluster.on('fork', ()=> {
console.log('fork 事件... ');
})
cluster.on('online', ()=> {
console.log('online 事件... ');
})
cluster.on('listening', ()=> {
console.log('listening 事件... ');
})
cluster.on('disconnect', ()=> {
console.log('disconnect 事件... ');
})
cluster.on('exit', ()=> {
console.log('exit 事件... ');
})
cluster.on('setup', ()=> {
console.log('setup 事件... ');
})由以上可知,master 進程通過 cluster.fork() 來創建 worker 進程,其實,cluster.fork() 內部是通過 child_process.fork() 來創建子進程。也就是說:master 與 worker 進程是父、子進程的關系;其跟 child_process 創建的父子進程一樣是通過 IPC 通道進行通信的。
IPC 的全稱是 Inter-Process Communication,即進程間通信,進程間通信的目的是為了讓不同的進程能夠互相訪問資源并進行協調工作。Node 中實現 IPC 通道的是管道(pipe)技術,具體實現由 libuv 提供,在 Windows 下由命名管道(named pipe)實現,*nix 系統則采用 Unix Domain Socket 實現。其變現在應用層上的進程間通信只有簡單的 message 事件和 send 方法,使用十分簡單。
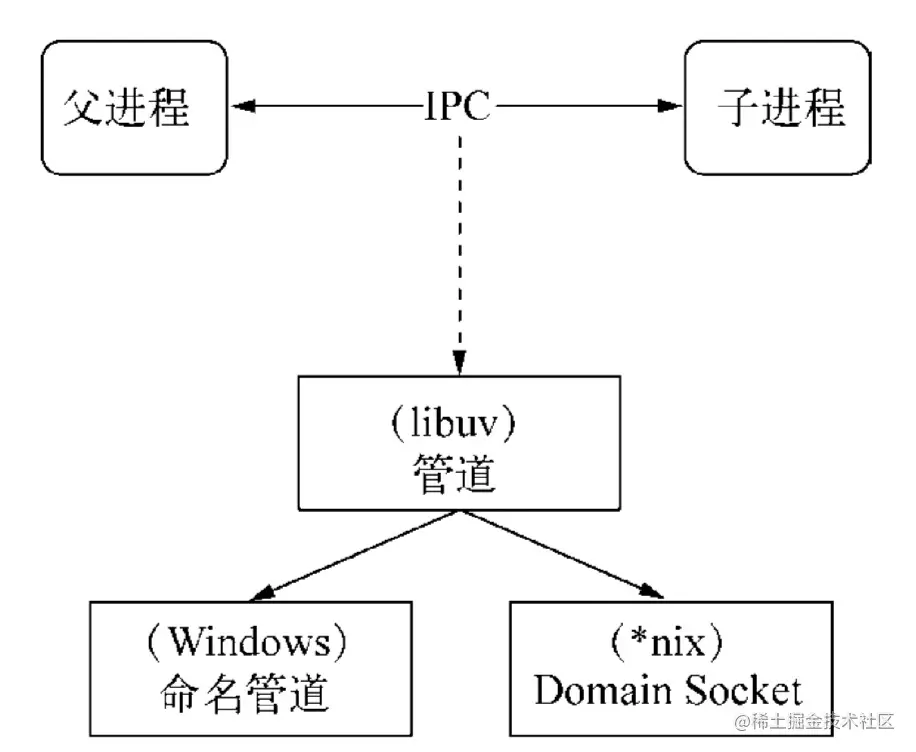
父進程在實際創建子進程之前,會創建 IPC 通道并監聽它,然后才真正創建出子進程,并通過環境變量(NODE_CHANNEL_FD)告訴子進程這個 IPC 通道的文件描述符。子進程在啟動過程中,根據文件描述符去連接這個已存在的 IPC 通道,從而完成父子進程之間的連接。

建立連接之后的父子進程就可以進行自由通信了。由于 IPC 通道是用命名管道或 Domain Socket 創建的,它們與網絡 socket 的行為比較類似,屬于雙向通信。不同的是它們在系統內核中就完成了進程間的通信,而不用經過實際的網絡層,非常高效。在 Node 中,IPC 通道被抽象為 Stream 對象,在調用 send 時發送數據(類似于 write ),接收到的消息會通過 message 事件(類似于 data)觸發給應用層。
master 和 worker 進程在 server 實例的創建過程中,是通過 IPC 通道進行通信的,那會不會對我們的開發造成干擾呢?比如,收到一堆其實并不需要關心的消息?答案肯定是不會?那么是怎么做到的呢?
Node 引入進程間發送句柄的功能,send 方法除了能通過 IPC 發送數據外,還能發送句柄,第二個參數為句柄,如下所示
child.send(meeage, [sendHandle])
句柄是一種可以用來標識資源的引用,它的內部包含了指向對象的文件描述符。例如句柄可以用來標識一個服務器端 socket 對象、一個客戶端 socket 對象、一個 UDP 套接字、一個管道等。 那么句柄發送跟我們直接將服務器對象發送給子進程有沒有什么差別?它是否真的將服務器對象發送給子進程?
其實 send() 方法在將消息發送到 IPC 管道前,將消息組裝成兩個對象,一個參數是 handle,另一個是 message,message 參數如下所示
{
cmd: 'NODE_HANDLE',
type: 'net.Server',
msg: message
}發送到 IPC 管道中的實際上是要發送的句柄文件描述符,其為一個整數值。這個 message 對象在寫入到 IPC 管道時會通過 JSON.stringify 進行序列化,轉化為字符串。子進程通過連接 IPC 通道讀取父進程發送來的消息,將字符串通過 JSON.parse 解析還原為對象后,才觸發 message 事件將消息體傳遞給應用層使用。在這個過程中,消息對象還要被進行過濾處理,message.cmd 的值如果以 NODE_ 為前綴,它將響應一個內部事件 internalMessage ,如果 message.cmd 值為 NODE_HANDLE,它將取出 message.type 值和得到的文件描述符一起還原出一個對應的對象。這個過程的示意圖如下所示

在 cluster 中,以 worker 進程通知 master 進程創建 server 實例為例子。worker 偽代碼如下:
// woker進程
const message = {
cmd: 'NODE_CLUSTER',
type: 'net.Server',
msg: message
};
process.send(message);master 偽代碼如下:
worker.process.on('internalMessage', fn);在前面的例子中,多個 woker 中創建的 server 監聽了同個端口 3000,通常來說,多個進程監聽同個端口,系統會報 EADDRINUSE 異常。為什么 cluster 沒問題呢?
因為獨立啟動的進程中,TCP 服務器端 socket 套接字的文件描述符并不相同,導致監聽到相同的端口時會拋出異常。但對于 send() 發送的句柄還原出來的服務而言,它們的文件描述符是相同的,所以監聽相同端口不會引起異常。
這里需要注意的是,多個應用監聽相同端口時,文件描述符同一時間只能被某個進程所用,換言之就是網絡請求向服務器端發送時,只有一個幸運的進程能夠搶到連接,也就是說只有它能為這個請求進行服務,這些進程服務是搶占式的。
每當 worker 進程創建 server 實例來監聽請求,都會通過 IPC 通道,在 master 上進行注冊。當客戶端請求到達,master 會負責將請求轉發給對應的 worker;
具體轉發給哪個 worker?這是由轉發策略決定的,可以通過環境變量 NODE_CLUSTER_SCHED_POLICY 設置,也可以在 cluster.setupMaster(options) 時傳入,默認的轉發策略是輪詢(SCHED_RR);
當有客戶請求到達,master 會輪詢一遍 worker 列表,找到第一個空閑的 worker,然后將該請求轉發給該worker;
pm2 是 node 進程管理工具,可以利用它來簡化很多 node 應用管理的繁瑣任務,如性能監控、自動重啟、負載均衡等。
pm2 自身是基于 cluster 模塊進行封裝的, 本節我們主要 pm2 的 Satan 進程、God Daemon 守護進程 以及兩者之間的進程間遠程調用 RPC。
撒旦(Satan),主要指《圣經》中的墮天使(也稱墮天使撒旦),被看作與上帝的力量相對的邪惡、黑暗之源,是God 的對立面。
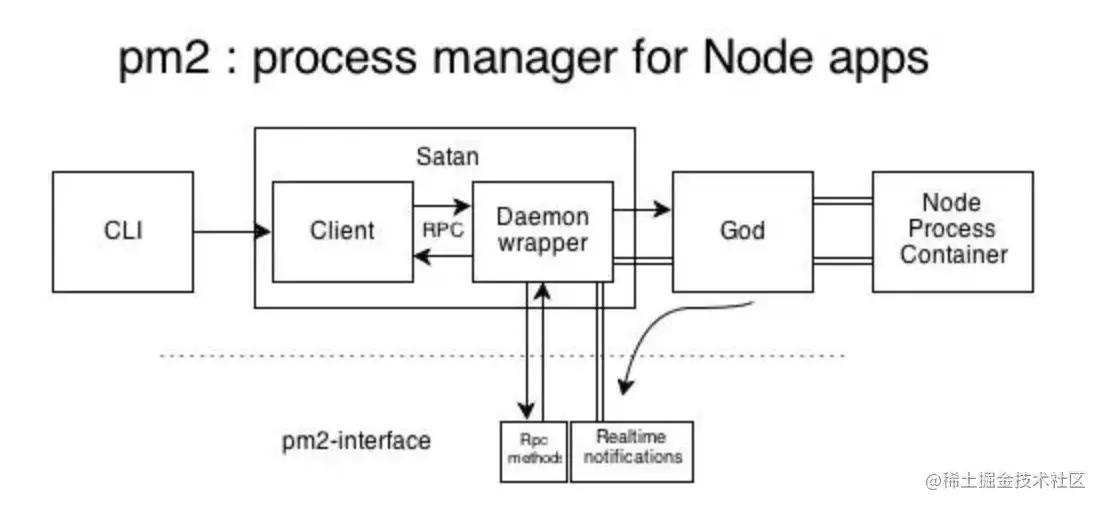
其中 Satan.js 提供程序的退出、殺死等方法,God.js 負責維持進程的正常運行,God 進程啟動后一直運行,相當于 cluster 中的 Master進程,維持 worker 進程的正常運行。
RPC(Remote Procedure Call Protocol)是指遠程過程調用,也就是說兩臺服務器A,B,一個應用部署在A 服務器上,想要調用 B 服務器上應用提供的函數/方法,由于不在一個內存空間,不能直接調用,需要通過網絡來表達調用的語義和傳達調用的數據。同一機器不同進程間的方法調用也屬于 rpc 的作用范疇。 執行流程如下所示
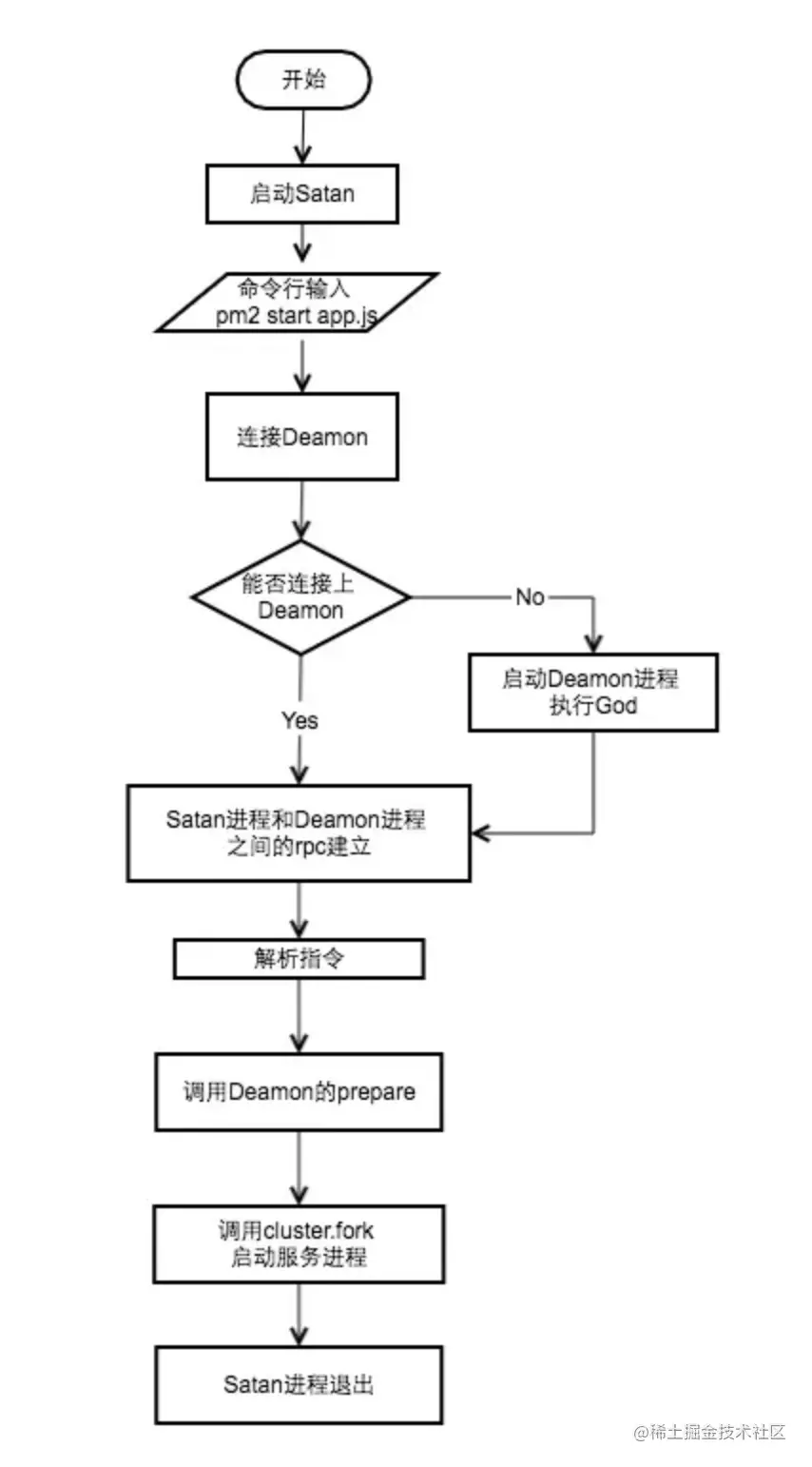
每次命令行的輸入都會執行一次 satan 程序,如果 God 進程不在運行,首先需要啟動 God 進程。然后根據指令,Satan 通過 rpc 調用 God 中對應的方法執行相應的邏輯。
以 pm2 start app.js -i 4 為例,God 在初次執行時會配置 cluster,同時監聽 cluster 中的事件:
// 配置cluster
cluster.setupMaster({
exec : path.resolve(path.dirname(module.filename), 'ProcessContainer.js')
});
// 監聽cluster事件
(function initEngine() {
cluster.on('online', function(clu) {
// worker進程在執行
God.clusters_db[clu.pm_id].status = 'online';
});
// 命令行中 kill pid 會觸發exit事件,process.kill不會觸發exit
cluster.on('exit', function(clu, code, signal) {
// 重啟進程 如果重啟次數過于頻繁直接標注為stopped
God.clusters_db[clu.pm_id].status = 'starting';
// 邏輯
// ...
});
})();在 God 啟動后, 會建立 Satan 和 God 的rpc鏈接,然后調用 prepare 方法,prepare 方法會調用 cluster.fork 來完成集群的啟動
God.prepare = function(opts, cb) {
// ...
return execute(opts, cb);
};
function execute(env, cb) {
// ...
var clu = cluster.fork(env);
// ...
God.clusters_db[id] = clu;
clu.once('online', function() {
God.clusters_db[id].status = 'online';
if (cb) return cb(null, clu);
return true;
});
return clu;
}感謝各位的閱讀!關于“Node中集群的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





