溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了C語言中數據在內存中是怎么存儲的,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
常見的數據類型
| 常見的數據類型 | 字節 | |
|---|---|---|
| char | 字符數據類型 | 1 |
| short | 短整型 | 2 |
| int | 整形 | 4 |
| long | 長整型 | 4 |
| long long | 更長的整形 | 8 |
| float | 浮點型 | 4 |
| double | 雙精度浮點型 | 8 |
注意:
C語言里面沒有字符串類型
關于int和long的大小:C語言只是規定了:sizeof(long)>=sizeof(int)
布爾類型(_Bool)(C99引入)專門用來表示真假,但是在C語言中不需要布爾類型也可以表示真假
#include<stdbool.h>
int main()
{
_Bool flag = false;
_Bool flag2 = true;
if(flag)
{
printf("haha\n");
}
if(flag2)
{
printf("hehe\n");
}
return 0;
}//只打印了hehechar也屬于整形(每一個字符在儲存的時候是儲存他所對應的ascll值,ascll是整數)
| char | unsigned char | signed char |
| short | unsigned short | signed short |
| int | unsigned int | signed int |
| long | unsigned long | signed long |
有符號數和無符號數
有符號數
int main()
{
int a = 10;
int a = -10;
return 0;
}//a是一個有符號數,它可以儲存正負整數
//int ===> signed int
//short ===> signed short
//long ===> signed long無符號數
有一些變量只有正數由意義,例如年齡,價格。定義這些變量的時候就可以用無符號數定義 ,無符號數只能存儲正數。
int main()
{
unsigned int a = 10;
//無符號變量只能儲存正數
a = -10;
//即使這里輸入了一個負數,它也會把這個負數轉化成一個正數(不是簡單的去掉符號,這是關于二進制的計算)
return 0;
}是否char 等于signed char呢?
答案:取決于編譯器
我們會發現這樣一件事:
int 就是 signed int
short 就是 signed short
long 就是 signed long
char 等于signed char還是unsigned char 取決于編譯器,不同的編譯器可能是不同的結果,常見的編譯器下是等于signed char
對于有符號數字和無符號數字的打印
打印無符號數應該用%u
%u和%d打印的解讀方式不同:
使用%d 時,會認為這是一個有符號數,打印的時候會認為二進制中第一位是符號位;
使用%u時,會認為這是一個無符號數據,會認為整個二進制序列都是有效位。
#include<stdio.h>
int main()
{
unsigned int a = 10;
printf("%u",a);//正確的形式
//如果存儲了一個-10進去會怎么樣
a = -10;
printf("%u",a);
//會打印4294967286,而這個數據不是隨機數
return 0;
}為什么無符號整形儲存 -10 的時候會打印出來4284967286(并不是隨機數)?
%u在解讀的時候認為此時a仍然存儲的是正數,解讀了a的補碼。在本章后面介紹原反補嗎的時候在詳細解釋細節。
| 浮點型 | 大小 |
|---|---|
| float | 4 |
| double | 8 |
| 構造類型 | |
|---|---|
| 數組 | 數組名去掉后剩下的就是數組的類型 |
| 結構體 | struct |
| 枚舉類型 | enum |
| 聯合(聯合體)類型 | union |
| 指針類型 |
|---|
| char* pc |
| int * pi |
| float* pf |
| void* pv |
void表示空類型(無類型)
通常應用于函數的返回類型,函數的參數,指針類型
int a = 10; int b = -10;
然后我們觀察a、b在內存中的儲存
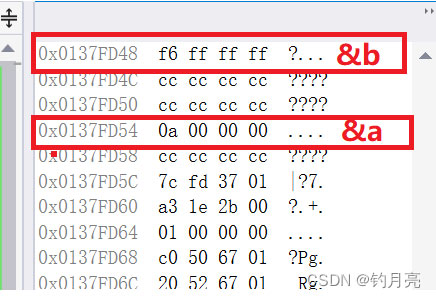
數據在內存里面是以二進制儲存的,但是編譯器是以十六進制展現給我們看的:
a在內存中的值是 :0a 00 00 00
b在內存中的值是: f6 ff ff ff
為什么是這樣的值呢?下面介紹整數的原碼、反碼、補碼。
原碼,反碼,補碼
整數二進制有3種表示形式,而內存中存儲的是二進制的補碼
例如 1 的原碼:
00000000 00000000 00000000 00000001
正整數
正整數的原碼、反碼和補碼相同
負整數
原碼:按照一個數的正負直接寫出來的二進制就是原碼
反碼:符號位不變,其他位按位取反 (并不是按位取反)
補碼:反碼的二進制序列加1
從原碼轉換成補碼:先取反再加一。
從補碼轉換成原碼:可以先減一再取反,也可以先取反再加一(和原碼轉換成補碼的過程相同)。
| 類型 | 數據:15 | 數據:-15 |
|---|---|---|
| 原碼 | 00000000 00000000 00000000 00001111 | 10000000 00000000 00000000 00001111 |
| 反碼 | 00000000 00000000 00000000 00001111 | 11111111 11111111 11111111 11110000 |
| 補碼 | 00000000 00000000 00000000 00001111 | 11111111 11111111 11111111 11110001 |
解釋為什么%u打印-10;會出現4294967286
用上面的方法我們就可以計算出-10的補碼:
| 數據 | 補碼 |
|---|---|
| 10 | 11111111 11111111 11111111 11110110 |
回到最開始使用%u打印-10會打印成4294967286,是因為在使用%u的時候,不會解讀符號位,會將整個32位二進制都當作有效位,讀出一個數據,而這個數據就是4294967286。
同時回到剛才a,b的值
int main()
{
int a = 10;
int b = -10;
//a: 00000000 00000000 00000000 00001010
//b: 11111111 11111111 11111111 11110110
}
//四個二進制位轉換成一個十六進制位
//a: 00 00 00 0a
//b: ff ff ff f6為什么和在內存界面看到的不同呢?
內存界面和我們計算出來的順序是相反的:
| 數據 | 計算結果 | 內存 |
|---|---|---|
| 10 | 00 00 00 0a | 0a 00 00 00 |
| -10 | ff ff ff f6 | f6 ff ff ff |
為什么會倒著存進去?
這就和字節序有關,下面我們來了解字節序
當儲存的內容超過一個字節的時候,儲存的時候就有順序
(一個char類型的數據是沒有字節序。char類型的數據只有一個字節,沒有順序)
機器有兩種對字節的存儲順序:
大端字節序存儲:
低字節數據存放在高地址處,高字節數據存放在低地址處
小端字節序存儲
低字節數據存放在低地址處,高字節數據存放在高地址處
我們用下面這個例子來解釋:
int main()
{
int a = 0x11223344;//0x開頭說明是十六進制數字
//再內存界面看到:44 33 22 11
return 0;
}
而我在觀察內存的時候發現我的機器是按照方式2進行存儲的,所以我的機器是采用的小端字節序。
那么有什么方法可以快速判斷自己當前使用的機器屬于哪一種字節序呢?
設計一個小程序判斷當前機器屬于哪種字節序
#include<stdio.h>
int main()
{
int a = 1;
//a的十六進制是 00 00 00 01
//如果是大端那么內存中為:00 00 00 01
//如果是小端那么內存中為:01 00 00 00
//只需要判斷第一個字節的內容是不是1
char*pc = (char*)&a;
//強制類型轉換截取了a的第一個字節
if(*pc)//也可以是:if(*(char*)&a)
{
printf("小端");
}
else
{
printf("大端");
}
return 0;
}例題1
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("%d %d %d ",a,b,c);//會打印出-1 -1 255
return 0;
}解釋:
第一步:
這里我們將三個相同的整數 -1 分別存進了兩種類型的變量,(在我所使用的VS2019編譯器下char和signed char等價),而這兩種類型又都屬于char類型
第二步:
char 類型的變量只能儲存一個字節(8個比特位)大小的數據,但是 -1 是整形(包含32個比特位),
這里就需要發生數據截斷: -1 的二進制補碼是11111111 11111111 11111111 11111111
截斷:將補碼的最后八位賦值給變量a、b、c。
第三步:
這里需要將char類型的數據以%d的方式打印,但是%d只能解讀整數數據(整數有四個字節),而char類型的三個變量都只有一個字節,所以這里會發生整型提升:
整形提升:對于有符號數據,高位補符號位,對于無符號數據:高位補0
| 數據(變量) | 整形提升前 | 整形提升后(補碼) | 原碼代表的數據 |
|---|---|---|---|
| a/b | 11111111 | 11111111 11111111 11111111 11111111 | -1 |
| c | 11111111 | 00000000 00000000 00000000 11111111 | 255 |
%d打印的時候會認為這就是要打印數據的補碼,按照打印正常整數的形式打印這三個變量
例題2
#include<stdio.h>
int main()
{
char a = -128;
printf("%u",a);//會打印4294967168
return 0;
}解釋:
第一步:
觀察數據: -128 是一個整數,二進制有32位 : 但是接受這個數據的變量是一個char類型的變量(只能接受8個比特位)
第二步:
數據的截斷:
| 數據 | 二進制(補碼) | 截取(a儲存的部分) |
|---|---|---|
| -128 | 11111111 11111111 11111111 10000000 | 10000000 |
聯想:這里如果是a = 128,那么階段后的值仍然是10000000
第三步:
打印整數(四個字節),所以這里需要發生整形提升(a是有符號char,高位補符號位)
| 數據(變量) | 整形提升前 | 整形提升后(補碼) |
|---|---|---|
| a | 10000000 | 11111111 11111111 11111111 10000000 |
第四步:
%u的形式打印這個變量,因為%u應該打印的是無符號整數,且打印的時候認為整個32位全為有效位,
就會打印出4294967168
| 常見的浮點數 | 例子 |
|---|---|
| 字面浮點數 | 3.14159 |
| 科學計數法的表示形式 | 1E10(1乘以10的10次方) |
注意:
在浮點型數據后面加了f是float類型,不加則默認是double類型
%f和%lf默認小數點后六位
我們通過下面這個例題來探究浮點型和整形在內存中的儲存方式有什么不同
#include<stdio.h>
int main()
{
int n = 9;
float* pf = (float*)&n;
//第一組
printf("n = %d\n", n); //打印出:9
printf("*pf = %f\n", *pf);//打印出:0.000000
//第二組
*pf = 9.0;
printf("n = %d\n", n); //打印出:1091567616
printf("*pf = %f\n", *pf);//打印出:9.000000
return 0;
}為什么會出現這樣的情況?
回答這個問題前,先來了解浮點型的二進制存儲形式:
國際標準電氣電子工程師學會(IEEE):任何一個二進制浮點數V都可以表示成下面的形式
表示形式:(-1)^S * M * 2^E
(-1)^S表示符號位,當S為0 時表示正數,當S為1時,表示負數
M表示有效數字,大于等于1,小于等于2
2^E表示指數位
| (5.5)十進制 | (5.5)二進制 |
|---|---|
| 5.5 | 101.1 |
| 5.5*(10^1) | 1.011*(2^2) |
十進制浮點數:5.5 轉化成二進制:101.1 可以寫成:(-1)^0 * 1.011 * (2^2) S = 0 M = 1.011 E = 2 只需要儲存SME三個值
IEEE浮點數標準定義了兩種基本的格式:以四個字節表示的的單精度格式和八個字節表示的雙精度格式
單精度浮點數儲存格式(32位)
| 第一位 | 接著8位 | 剩下23位 |
|---|---|---|
| 符號位 | 指數位 | 有效位 |
雙精度浮點數儲存格式(64位)
| 第一位 | 接著11位 | 剩下52位 |
|---|---|---|
| 符號位 | 指數位 | 有效位 |
IEEE754對于有效數字M和指數E有一些特別的規定:
關于M:
1.我們已經知道1<=M<2,也即是說M一定可以寫成這樣的形式:1.xxxxxx
其中xxxxxx表示小數點后面的部分
2.在計算機內部儲存M時,由于第一位總是1,所以把這個1省略,只保存后面的小數部分,這樣可以節約一位有效數字,這樣的話儲存的數據精度就可以提升一位:例如在單精度浮點型存儲格式中,最后23位作為有效位,但是儲存在計算機的數據精度是24位
關于E:
計算機會認為這是一個無符號數,但是十幾行會存在很多E取負數的情況,所以IEEE754規定:存入內存時,E的真實值必須在加上一個中間數 ,對于單精度,這個中間數(也叫做偏移量)是127,對于雙精度,這個中間數是1023
例如:對于十進制的數字0.5,它的二進制是0.1,E= -1;那么我們就需要把-1在加上127得到126后,將126儲存在指數位
E: 指數位值減去127(1023)得到真實值
M: 有效位的數值前面加上1.
E:
真實的E是一個十分小的數字,接近0;
這時候不用計算,E直接就等于1-127(1-1023)就是它的真實值
M:
M不再在前面加上1,而是還原成0.XXXXXX的小數,這樣做是為了表示正負0,以及接近于0的很小的數字。
真實的E是一個十分大的數字,代表正負無窮大的數字
解釋上面的例子
第一組為什么以%f打印整數9,會打印出0.000000?
原因:
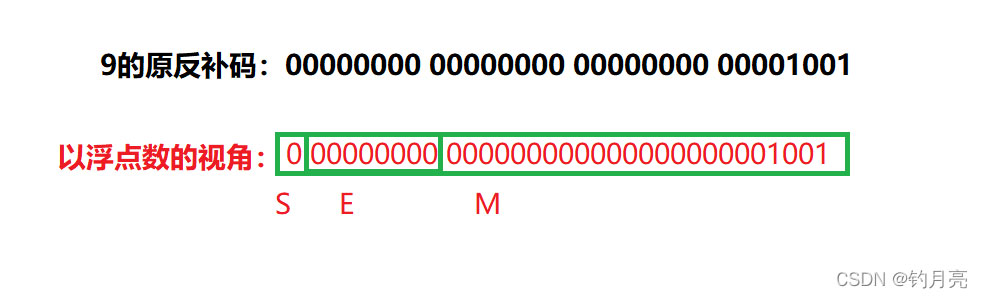
此時E為全0,是一個會被判定成一個十分小的數據,所以打印0.000000
為什么第二組中以%d的形式打印*pf時,會打印出1091567616?

上述內容就是C語言中數據在內存中是怎么存儲的,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





