溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Python如何利用三層神經網絡實現手寫數字分類”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Python如何利用三層神經網絡實現手寫數字分類”吧!
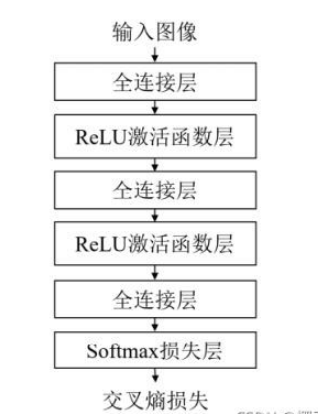
一個完整的神經網絡通常由多個基本的網絡層堆疊而成。本實驗中的三層全連接神經網絡由三個全連接層構成,在每兩個全連接層之間會插入ReLU激活函數引入非線性變換,最后使用Softmax層計算交叉嫡損失,如下圖所示。因此本實驗中使用的基本單元包括全連接層、ReLU激活函數、Softmax損失函數。
import numpy as np import struct import os
MNIST_DIR = "mnist_data" TRAIN_DATA = "train-images-idx3-ubyte" TRAIN_LABEL = "train-labels-idx1-ubyte" TEST_DATA = "t10k-images-idx3-ubyte" TEST_LABEL = "t10k-labels-idx1-ubyte"
數據集鏈接
數據集下載后一定記得解壓
class FullyConnectedLayer(object): def __init__(self, num_input, num_output): # 全連接層初始化 self.num_input = num_input self.num_output = num_output def init_param(self, std=0.01): # 參數初始化 self.weight = np.random.normal(loc=0, scale=std, size=(self.num_input, self.num_output)) self.bias = np.zeros([1, self.num_output]) def forward(self, input): # 前向傳播計算 self.input = input self.output = np.dot(self.input,self.weight)+self.bias return self.output def backward(self, top_diff): # 反向傳播的計算 self.d_weight =np.dot(self.input.T,top_diff) self.d_bias = top_diff # bottom_diff = np.dot(top_diff,self.weight.T) return bottom_diff def update_param(self, lr): # 參數更新 self.weight = self.weight - lr * self.d_weight self.bias = self.bias - lr * self.d_bias def load_param(self, weight, bias): # 參數加載 assert self.weight.shape == weight.shape assert self.bias.shape == bias.shape self.weight = weight self.bias = bias def save_param(self): # 參數保存 return self.weight, self.bias
class ReLULayer(object): def forward(self, input): # 前向傳播的計算 self.input = input output = np.maximum(self.input,0) return output def backward(self, top_diff): # 反向傳播的計算 b = self.input b[b>0] =1 b[b<0] = 0 bottom_diff = np.multiply(b,top_diff) return bottom_diff
class SoftmaxLossLayer(object): def forward(self, input): # 前向傳播的計算 input_max = np.max(input, axis=1, keepdims=True) input_exp = np.exp(input- input_max)#(64,10) partsum = np.sum(input_exp,axis=1) sum = np.tile(partsum,(10,1)) self.prob = input_exp / sum.T return self.prob def get_loss(self, label): # 計算損失 self.batch_size = self.prob.shape[0] self.label_onehot = np.zeros_like(self.prob) self.label_onehot[np.arange(self.batch_size), label] = 1.0 loss = -np.sum(self.label_onehot*np.log(self.prob)) / self.batch_size return loss def backward(self): # 反向傳播的計算 bottom_diff = (self.prob - self.label_onehot)/self.batch_size return bottom_diff
class MNIST_MLP(object):
def __init__(self, batch_size=64, input_size=784, hidden1=32, hidden2=16, out_classes=10, lr=0.01, max_epoch=1,print_iter=100):
self.batch_size = batch_size
self.input_size = input_size
self.hidden1 = hidden1
self.hidden2 = hidden2
self.out_classes = out_classes
self.lr = lr
self.max_epoch = max_epoch
self.print_iter = print_iter
def shuffle_data(self):
np.random.shuffle(self.train_data)
def build_model(self): # 建立網絡結構
self.fc1 = FullyConnectedLayer(self.input_size, self.hidden1)
self.relu1 = ReLULayer()
self.fc2 = FullyConnectedLayer(self.hidden1, self.hidden2)
self.relu2 = ReLULayer()
self.fc3 = FullyConnectedLayer(self.hidden2, self.out_classes)
self.softmax = SoftmaxLossLayer()
self.update_layer_list = [self.fc1, self.fc2, self.fc3]
def init_model(self):
for layer in self.update_layer_list:
layer.init_param()
def forward(self, input): # 神經網絡的前向傳播
h2 = self.fc1.forward(input)
h2 = self.relu1.forward(h2)
h3 = self.fc2.forward(h2)
h3 = self.relu2.forward(h3)
h4 = self.fc3.forward(h3)
self.prob = self.softmax.forward(h4)
return self.prob
def backward(self): # 神經網絡的反向傳播
dloss = self.softmax.backward()
dh3 = self.fc3.backward(dloss)
dh3 = self.relu2.backward(dh3)
dh2 = self.fc2.backward(dh3)
dh2 = self.relu1.backward(dh2)
dh2 = self.fc1.backward(dh2)
def update(self, lr):
for layer in self.update_layer_list:
layer.update_param(lr)
def load_mnist(self, file_dir, is_images='True'):
bin_file = open(file_dir, 'rb')
bin_data = bin_file.read()
bin_file.close()
if is_images:
fmt_header = '>iiii'
magic, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, bin_data, 0)
else:
fmt_header = '>ii'
magic, num_images = struct.unpack_from(fmt_header, bin_data, 0)
num_rows, num_cols = 1, 1
data_size = num_images * num_rows * num_cols
mat_data = struct.unpack_from('>' + str(data_size) + 'B', bin_data, struct.calcsize(fmt_header))
mat_data = np.reshape(mat_data, [num_images, num_rows * num_cols])
return mat_data
def load_data(self):
train_images = self.load_mnist(os.path.join(MNIST_DIR, TRAIN_DATA), True)
train_labels = self.load_mnist(os.path.join(MNIST_DIR, TRAIN_LABEL), False)
test_images = self.load_mnist(os.path.join(MNIST_DIR, TEST_DATA), True)
test_labels = self.load_mnist(os.path.join(MNIST_DIR, TEST_LABEL), False)
self.train_data = np.append(train_images, train_labels, axis=1)
self.test_data = np.append(test_images, test_labels, axis=1)
def load_model(self, param_dir):
params = np.load(param_dir).item()
self.fc1.load_param(params['w1'], params['b1'])
self.fc2.load_param(params['w2'], params['b2'])
self.fc3.load_param(params['w3'], params['b3'])
def save_model(self, param_dir):
params = {}
params['w1'], params['b1'] = self.fc1.save_param()
params['w2'], params['b2'] = self.fc2.save_param()
params['w3'], params['b3'] = self.fc3.save_param()
np.save(param_dir, params)
def train(self):
max_batch_1 = self.train_data.shape[0] / self.batch_size
max_batch = int(max_batch_1)
for idx_epoch in range(self.max_epoch):
mlp.shuffle_data()
for idx_batch in range(max_batch):
batch_images = self.train_data[idx_batch * self.batch_size:(idx_batch + 1) * self.batch_size, :-1]
batch_labels = self.train_data[idx_batch * self.batch_size:(idx_batch + 1) * self.batch_size, -1]
prob = self.forward(batch_images)
loss = self.softmax.get_loss(batch_labels)
self.backward()
self.update(self.lr)
if idx_batch % self.print_iter == 0:
print('Epoch %d, iter %d, loss: %.6f' % (idx_epoch, idx_batch, loss))
def evaluate(self):
pred_results = np.zeros([self.test_data.shape[0]])
for idx in range(int(self.test_data.shape[0] / self.batch_size)):
batch_images = self.test_data[idx * self.batch_size:(idx + 1) * self.batch_size, :-1]
prob = self.forward(batch_images)
pred_labels = np.argmax(prob, axis=1)
pred_results[idx * self.batch_size:(idx + 1) * self.batch_size] = pred_labels
accuracy = np.mean(pred_results == self.test_data[:, -1])
print('Accuracy in test set: %f' % accuracy)7.完整流程
if __name__ == '__main__':
h2, h3, e = 128, 64, 20
mlp = MNIST_MLP(hidden1=h2, hidden2=h3,max_epoch=e)
mlp.load_data()
mlp.build_model()
mlp.init_model()
mlp.train()
mlp.save_model('mlp-%d-%d-%depoch.npy' % (h2,h3,e))
mlp.load_model('mlp-%d-%d-%depoch.npy' % (h2, h3, e))
mlp.evaluate()pycharm在初次運行時,會在以下代碼報錯:
mlp.load_model('mlp-%d-%d-%depoch.npy' % (h2, h3, e))ValueError: Object arrays cannot be loaded when allow_pickle=False
經過上網查看原因后,發現是numpy版本太高引起
解決方法:
點擊報錯處,進入源代碼(.py),注釋掉693行:
#if not allow_pickle:
#raise ValueError("Object arrays cannot be loaded when "
# "allow_pickle=False")
# Now read the actual data.
if dtype.hasobject:
# The array contained Python objects. We need to unpickle the data.
#if not allow_pickle:
#raise ValueError("Object arrays cannot be loaded when "
# "allow_pickle=False")
if pickle_kwargs is None:
pickle_kwargs = {}
try:
array = pickle.load(fp, **pickle_kwargs)
except UnicodeError as err:
if sys.version_info[0] >= 3:
# Friendlier error message在不改變網絡結構的條件下我通過自行調節參數主要體現在:
if __name__ == '__main__': h2, h3, e = 128, 64, 20
class MNIST_MLP(object): def __init__(self, batch_size=64, input_size=784, hidden1=32, hidden2=16, out_classes=10, lr=0.01, max_epoch=1,print_iter=100):
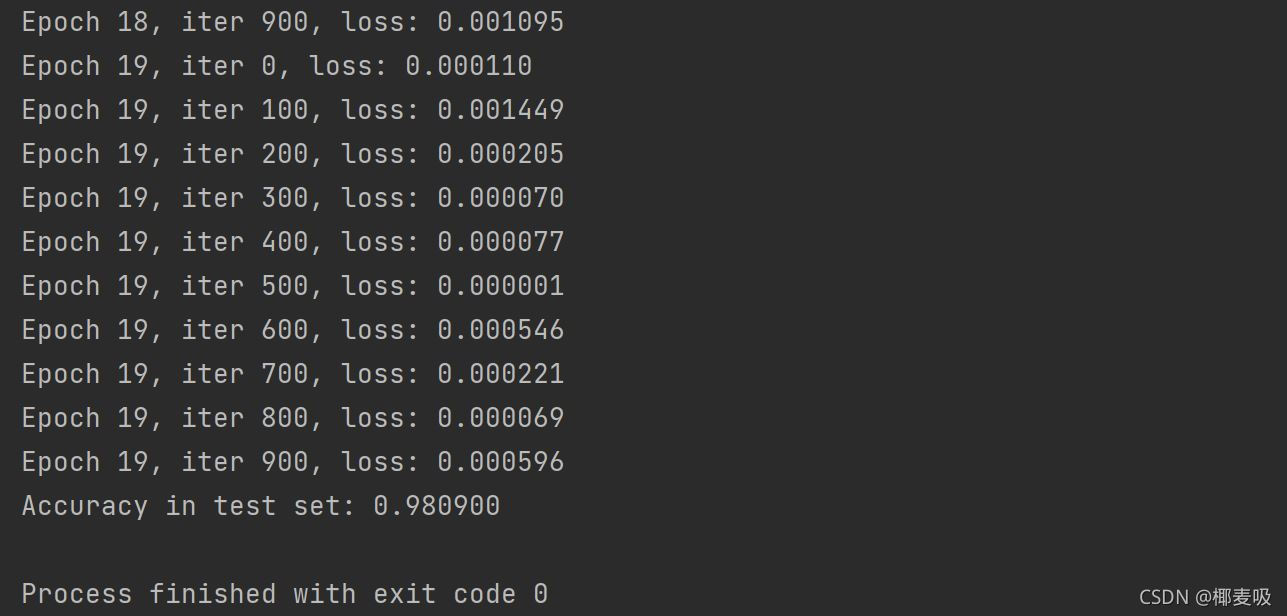
為了提高準確率,當然你可以從其他方面進行修改,以下是我得出的輸出結果:
ValueError: Object arrays cannot be loaded when allow_pickle=False解決方案
在讀.npz文件時報下面錯誤:
population_data=np.load("./data/populations.npz")
print(population_data.files)#里面有兩個數組 data feature_names
data=population_data['data']
print(data)
print(population_data['feature_names'])報錯:
['data', 'feature_names']
Traceback (most recent call last):
File "E:/pycharm file/使用scikit-learn構建模型/構建一元線性模型.py", line 32, in <module>
data=population_data['data']
File "E:\pycharm file\venv\lib\site-packages\numpy\lib\npyio.py", line 262, in __getitem__
pickle_kwargs=self.pickle_kwargs)
File "E:\pycharm file\venv\lib\site-packages\numpy\lib\format.py", line 692, in read_array
raise ValueError("Object arrays cannot be loaded when "
ValueError: Object arrays cannot be loaded when allow_pickle=False報錯為:numpy版本太高,我用的是1.16.3,應該降級為1.16.2
兩種解決方案:
Numpy 1.16.3幾天前發布了。從發行版本中說明:“函數np.load()和np.lib.format.read_array()采用allow_pickle關鍵字,現在默認為False以響應CVE-2019-6446 < nvd.nist.gov/vuln/detail / CVE-2019-6446 >“。降級到1.16.2對我有幫助,因為錯誤發生在一些library內部
第一種:點擊報錯處,進入源代碼(.py),注釋掉693行:
#if not allow_pickle:
#raise ValueError("Object arrays cannot be loaded when "
# "allow_pickle=False")
# Now read the actual data.
if dtype.hasobject:
# The array contained Python objects. We need to unpickle the data.
#if not allow_pickle:
#raise ValueError("Object arrays cannot be loaded when "
# "allow_pickle=False")
if pickle_kwargs is None:
pickle_kwargs = {}
try:
array = pickle.load(fp, **pickle_kwargs)
except UnicodeError as err:
if sys.version_info[0] >= 3:
# Friendlier error message修改后成功解決了問題,但改掉源碼不知道會不會有后遺癥
第二種:降級numpy版本
pip install numpy==1.16.2
上述兩種方法都可以成功解決報錯問題
感謝各位的閱讀,以上就是“Python如何利用三層神經網絡實現手寫數字分類”的內容了,經過本文的學習后,相信大家對Python如何利用三層神經網絡實現手寫數字分類這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





