溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關java中Kafka如何使用,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
官方文檔:http://kafka.apache.org/
中文文檔:https://kafka.apachecn.org/
Apache Kafka是分布式發布-訂閱消息系統。
Apache Kafka與傳統消息系統相比,有以下不同:
它被設計為一個分布式系統,易于向外擴展;
它同時為發布和訂閱提供高吞吐量;
它支持多訂閱者,當失敗時能自動平衡消費者;
它將消息持久化到磁盤,因此可用于批量消費,例如ETL,以及實時應用程序。
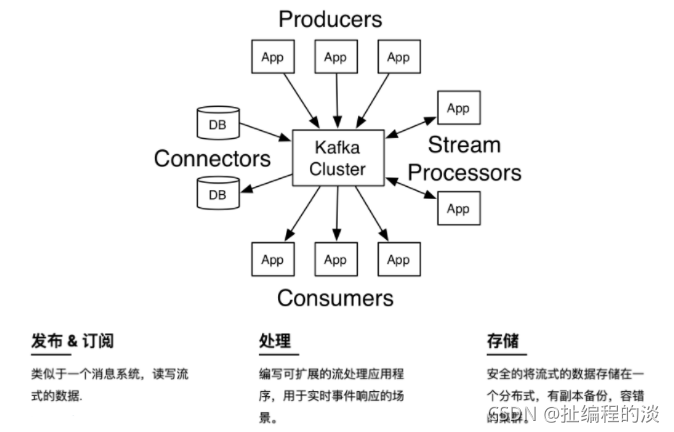
首先是一些概念:
Kafka作為一個集群,運行在一臺或者多臺服務器上.Kafka 通過 topic 對存儲的流數據進行分類。每條記錄中包含一個key,一個value和一個timestamp(時間戳)。
Kafka有四個核心的API:
The Producer API 允許一個應用程序發布一串流式的數據到一個或者多個Kafka topic。
The Consumer API 允許一個應用程序訂閱一個或多個 topic ,并且對發布給他們的流式數據進行處理。
The Streams API 允許一個應用程序作為一個流處理器,消費一個或者多個topic產生的輸入流,然后生產一個輸出流到一個或多個topic中去,在輸入輸出流中進行有效的轉換。
The Connector API 允許構建并運行可重用的生產者或者消費者,將Kafka topics連接到已存在的應用程序或者數據系統。比如,連接到一個關系型數據庫,捕捉表(table)的所有變更內容。
支持的語言(除了Java之外的):

常見概念:
1 Topics和日志
讓我們首先深入了解下Kafka的核心概念:提供一串流式的記錄— topic
Topic 就是數據主題,是數據記錄發布的地方,可以用來區分業務系統。Kafka中的Topics總是多訂閱者模式,一個topic可以擁有一個或者多個消費者來訂閱它的數據。
對于每一個topic, Kafka集群都會維持一個分區日志,如下所示:
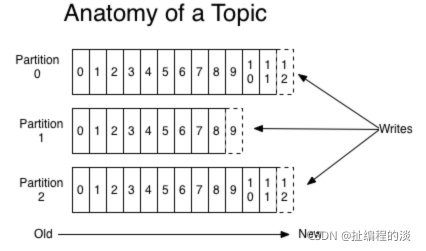
每個分區都是有序且順序不可變的記錄集,并且不斷地追加到結構化的commit log文件。分區中的每一個記錄都會分配一個id號來表示順序,我們稱之為offset,offset用來唯一的標識分區中每一條記錄。
Kafka 集群保留所有發布的記錄—無論他們是否已被消費—并通過一個可配置的參數——保留期限來控制. 舉個例子, 如果保留策略設置為2天,一條記錄發布后兩天內,可以隨時被消費,兩天過后這條記錄會被拋棄并釋放磁盤空間。Kafka的性能和數據大小無關,所以長時間存儲數據沒有什么問題.
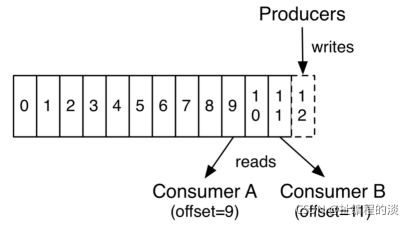
日志中的 partition(分區)有以下幾個用途。第一,當日志大小超過了單臺服務器的限制,允許日志進行擴展。每個單獨的分區都必須受限于主機的文件限制,不過一個主題可能有多個分區,因此可以處理無限量的數據。第二,可以作為并行的單元集—關于這一點,更多細節如下
2 分布式
日志的分區partition (分布)在Kafka集群的服務器上。每個服務器在處理數據和請求時,共享這些分區。每一個分區都會在已配置的服務器上進行備份,確保容錯性.
每個分區都有一臺 server 作為 “leader”,零臺或者多臺server作為 follwers 。leader server 處理一切對 partition (分區)的讀寫請求,而follwers只需被動的同步leader上的數據。當leader宕機了,followers 中的一臺服務器會自動成為新的 leader。每臺 server 都會成為某些分區的 leader 和某些分區的 follower,因此集群的負載是平衡的。
3 生產者
生產者可以將數據發布到所選擇的topic中。生產者負責將記錄分配到topic的哪一個 partition(分區)中。可以使用循環的方式來簡單地實現負載均衡,也可以根據某些語義分區函數(例如:記錄中的key)來完成。下面會介紹更多關于分區的使用。
4 消費者
消費者使用一個 消費組 名稱來進行標識,發布到topic中的每條記錄被分配給訂閱消費組中的一個消費者實例.消費者實例可以分布在多個進程中或者多個機器上。
如果所有的消費者實例在同一消費組中,消息記錄會負載平衡到每一個消費者實例.
如果所有的消費者實例在不同的消費組中,每條消息記錄會廣播到所有的消費者進程.
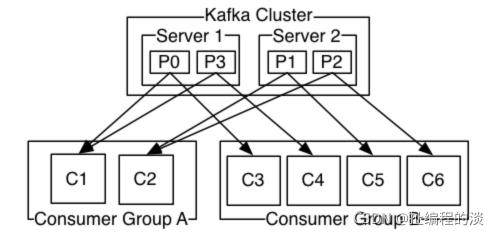
如圖,這個 Kafka 集群有兩臺 server 的,四個分區(p0-p3)和兩個消費者組。消費組A有兩個消費者,消費組B有四個消費者。
通常情況下,每個 topic 都會有一些消費組,一個消費組對應一個"邏輯訂閱者"。一個消費組由許多消費者實例組成,便于擴展和容錯。這就是發布和訂閱的概念,只不過訂閱者是一組消費者而不是單個的進程。
在Kafka中實現消費的方式是將日志中的分區劃分到每一個消費者實例上,以便在任何時間,每個實例都是分區唯一的消費者。維護消費組中的消費關系由Kafka協議動態處理。如果新的實例加入組,他們將從組中其他成員處接管一些 partition 分區;如果一個實例消失,擁有的分區將被分發到剩余的實例。
Kafka 只保證分區內的記錄是有序的,而不保證主題中不同分區的順序。每個 partition 分區按照key值排序足以滿足大多數應用程序的需求。但如果你需要總記錄在所有記錄的上面,可使用僅有一個分區的主題來實現,這意味著每個消費者組只有一個消費者進程。
保證
high-level Kafka給予以下保證:
生產者發送到特定topic partition 的消息將按照發送的順序處理。 也就是說,如果記錄M1和記錄M2由相同的生產者發送,并先發送M1記錄,那么M1的偏移比M2小,并在日志中較早出現一個消費者實例按照日志中的順序查看記錄.對于具有N個副本的主題,我們最多容忍N-1個服務器故障,從而保證不會丟失任何提交到日志中的記錄.
關于保證的更多細節可以看文檔的設計部分。
Kafka依賴于Zookeeper,而Zookeeper又依賴于Java,因此在使用Kafka之前要安裝jdk1.8的環境和啟動zookeeper服務器。
下載或安裝地址:
JDK1.8://www.mlszssj.com/article/229780.htm:
http://www.mlszssj.com/article/229783.htm:
https://kafka.apachecn.org/downloads.html
好,下面我們開始進行安裝
[root@iZ2ze4m2ri7irkf6h7n8zoZ local]# tar -zxf kafka_2.11-1.0.0.tgz [root@iZ2ze4m2ri7irkf6h7n8zoZ local]# mv kafka_2.11-1.0.0 kafka-2.11
首先檢查下自己的jdk 是否安裝:
[root@iZ2ze4m2ri7irkf6h7n8zoZ local]# java -version java version "1.8.0_144" Java(TM) SE Runtime Environment (build 1.8.0_144-b01) Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
啟動Zookeeper:
[root@iZ2ze4m2ri7irkf6h7n8zoZ zookeeper-3.5.9]# ls bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.txt [root@iZ2ze4m2ri7irkf6h7n8zoZ zookeeper-3.5.9]# cd conf/ [root@iZ2ze4m2ri7irkf6h7n8zoZ conf]# ls configuration.xsl log4j.properties zoo_sample.cfg [root@iZ2ze4m2ri7irkf6h7n8zoZ conf]# cp zoo_sample.cfg zoo.cfg [root@iZ2ze4m2ri7irkf6h7n8zoZ conf]# cd ../bin/ [root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ls README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zkServer.sh zkTxnLogToolkit.sh zkCleanup.sh zkCli.sh zkEnv.sh zkServer-initialize.sh zkTxnLogToolkit.cmd [root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./zkServer. zkServer.cmd zkServer.sh [root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.5.9/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
啟動Kafka:
[root@iZ2ze4m2ri7irkf6h7n8zoZ kafka-2.11]# ls bin config libs LICENSE NOTICE site-docs [root@iZ2ze4m2ri7irkf6h7n8zoZ kafka-2.11]# cd config/ [root@iZ2ze4m2ri7irkf6h7n8zoZ config]# ls connect-console-sink.properties connect-file-source.properties log4j.properties zookeeper.properties connect-console-source.properties connect-log4j.properties producer.properties connect-distributed.properties connect-standalone.properties server.properties connect-file-sink.properties consumer.properties tools-log4j.properties [root@iZ2ze4m2ri7irkf6h7n8zoZ config]# cd ../bin/ [root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-server-start.sh ../config/server.properties [2021-11-20 10:21:10,326] INFO KafkaConfig values: ...... [2021-11-20 10:21:12,423] INFO Kafka version : 1.0.0 (org.apache.kafka.common.utils.AppInfoParser) [2021-11-20 10:21:12,423] INFO Kafka commitId : aaa7af6d4a11b29d (org.apache.kafka.common.utils.AppInfoParser) [2021-11-20 10:21:12,424] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
新建和查看topic
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic ymx Created topic "ymx". [root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-topics.sh --list --zookeeper localhost:2181 ymx
生產者發送消息:
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic ymx >Hello Kafka! >Hello Ymx! >Hello Kafka and Ymx! >
消費者消費消息:
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ymx --from-beginning Hello Kafka! Hello Ymx! Hello Kafka and Ymx!
首先要copy下配置文件
[root@iZ2ze4m2ri7irkf6h7n8zoZ config]# cp server.properties server-01.properties [root@iZ2ze4m2ri7irkf6h7n8zoZ config]# cp server.properties server-02.properties [root@iZ2ze4m2ri7irkf6h7n8zoZ config]# vim server-01.properties #### 內容開始 #### broker.id=1 # 21行左右,broker的唯一標識(同一個集群中) listeners=PLAINTEXT://:9093 # 31行左右,放開,代表kafka的端口號 log.dirs=/tmp/kafka-logs-01 # 60行左右,用逗號分隔的目錄列表,在其中存儲日志文件 #### 內容結束 #### [root@iZ2ze4m2ri7irkf6h7n8zoZ config]# vim server-02.properties #### 內容開始 #### broker.id=2 # 21行左右,broker的唯一標識(同一個集群中) listeners=PLAINTEXT://:9094 # 31行左右,放開,代表kafka的端口號 log.dirs=/tmp/kafka-logs-02 # 60行左右,用逗號分隔的目錄列表,在其中存儲日志文件 #### 內容結束 ####
根據配置文件啟動Kafka(同一主機下)
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-server-start.sh ../config/server-01.properties
報錯信息:
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-server-start.sh ../config/server-01.properties Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Cannot allocate memory' (errno=12) # # There is insufficient memory for the Java Runtime Environment to continue. # Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memory. # An error report file with more information is saved as: # /usr/local/kafka-2.11/bin/hs_err_pid4036.log
原因:物理機或虛擬機內存不足,不足以保證Kafka啟動或運行時需要的內容容量
解決方式:
增加物理機或虛擬機的內存
減少Kafka啟動所需內容的配置,將要修改的文件為kafka-server-start.sh
export KAFKA_HEAP_OPTS="-Xmx512M -Xms256M" #29行左右
解決好之后我們開始啟動:
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-server-start.sh ../config/server-01.properties [2021-11-20 10:58:33,138] INFO KafkaConfig values:
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-server-start.sh ../config/server-02.properties [2021-11-20 10:59:04,187] INFO KafkaConfig values:
ps:看下我們的阿里云服務器的狀況
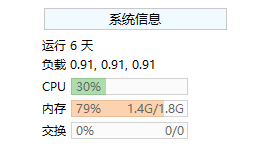
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic mr-yan Created topic "mr-yan". [root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic mr-yan Topic:mr-yan PartitionCount:1 ReplicationFactor:3 Configs: Topic: mr-yan Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
PartitionCount:主題分區數。
ReplicationFactor:用來設置主題的副本數。
leader:是負責給定分區所有讀寫操作的節點。每個節點都是隨機選擇的部分分區的領導者。
replicas:是復制分區日志的節點列表,不管這些節點是leader還是僅僅活著。
isr:是一組“同步”replicas,是replicas列表的子集,它活著并被指到leader。
進行集群環境下的使用:
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic mr-yan >Hello Kafkas! >Hello Mr.Yan >
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic mr-yan Hello Kafkas! Hello Mr.Yan
首先我們停掉一個Kafka的Broker:
[root@iZ2ze4m2ri7irkf6h7n8zoZ ~]# ps -ef|grep server-01.properties root 19859 28247 1 10:58 pts/3 ../config/server-01.properties root 23934 16569 0 11:12 pts/11 00:00:00 grep --color=auto server-01.properties [root@iZ2ze4m2ri7irkf6h7n8zoZ ~]# kill -9 28247 [root@iZ2ze4m2ri7irkf6h7n8zoZ ~]# ps -ef|grep server-01.properties root 32604 16569 0 11:13 pts/11 00:00:00 grep --color=auto server-01.properties [root@iZ2ze4m2ri7irkf6h7n8zoZ ~]# cd /usr/local/kafka-2.11/bin/ [root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic mr-yan Topic:mr-yan PartitionCount:1 ReplicationFactor:3 Configs: Topic: mr-yan Partition: 0 Leader: 0 Replicas: 1,0,2 Isr: 0,2
查看生產者和消費者的變化,并再次使用,發現仍可以進行使用
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic mr-yan >Hello Kafkas! >Hello Mr.Yan >[2021-11-20 11:12:28,881] WARN [Producer clientId=console-producer] Connection to node 1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) >Hello Kafkas too! >Hello Mr.Yan too! >
[root@iZ2ze4m2ri7irkf6h7n8zoZ bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic mr-yan Hello Kafkas! Hello Mr.Yan [2021-11-20 11:12:28,812] WARN [Consumer clientId=consumer-1, groupId=console-consumer-22158] Connection to node 1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) [2021-11-20 11:12:29,165] WARN [Consumer clientId=consumer-1, groupId=console-consumer-22158] Connection to node 1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) Hello Kafkas too! Hello Mr.Yan too!
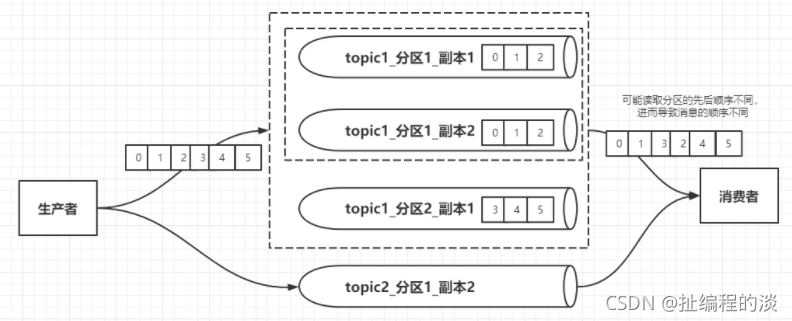
主題,分區,副本的概念
Kafka是根據主題(topic)進行消息的傳遞,但是又有分區和副本的概念,下面來分別解釋下:
分區:kafka對每一條消息的key做一個hashcode運算,然后將得到的數值對分區數量進行模運算就得到了這條消息所在分區的數字。副本:同一分區的幾個副本之間保存的是相同的數據,副本之間的關系是“一主多從”,其中的主(leader)則負責對外提供讀寫操作的服務,而從(follower)則負責與主節點同步數據,當主節點宕機,從節點之間能重新選舉leader進行對外服務。
kafka會保證同一個分區內的消息有序,但是不保證主題內的消息有序。
關于“java中Kafka如何使用”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





