溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“python機器學習中特征工程算法的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“python機器學習中特征工程算法的示例分析”這篇文章吧。
機器學習是從數據中,自動分析獲得規律(模型),并利用規律對未知數據進行預測。
機器學習的歷史數據通常使用csv文件存儲。
不用mysql的原因:
1、文件大的話讀取速度慢;
2、格式不符合機器學習要求的格式
Kaggle:大數據競賽平臺、80萬科學家、真實數據、數據量巨大
Kaggle網址:https://www.kaggle.com/datasets
UCI:360個數據集、覆蓋科學生活經濟等領域、數據量幾十萬
UCI數據集網址: http://archive.ics.uci.edu/ml/
scikit-learn:數據量較小、方便學習
scikit-learn網址:http://scikit-learn.org/stable/datasets/index.html#datasets
特征值(用以判斷目標值所用的條件:比如房子的面積朝向等)+目標值(希望實現的目標:比如房子價格)
有些數據集可以沒有目標值。
”將原始數據轉換為能更好地代表預測模型的潛在問題的特征“的過程,叫做特征工程,能夠提高對未知數據的預測準確性。特征如果不好,很可能即使算法好,結果也不會盡如人意。
pandas可用于數據讀取、對數據的基本處理
sklearn有更多對于特征的處理的強大的接口
特征抽取:
特征抽取API:sklearn.feature_extraction
API:sklearn.feature_extraction.DictVectorizer
語法如下:

字典數據抽取:將字典中的類別數據分別進行轉換為特征數據。因此,如果輸入的是數組形式,并且有類別的這些特征,需要先轉換成字典數據,然后進行抽取。
Count
類:sklearn.feature_extraction.text.CountVectorizer
用法:

1.統計所有文章當中所有的詞,重復的只看做一次
2.對每篇文章,在詞的列表里面,統計每個詞出現的次數
3.單個字母不統計
注意:該方法默認不支持中文,每個中文漢字被視為一個英文字母,中間有空格或者逗號就會被分開,同樣的,一個漢字不予統計。(中文可使用jieba分詞:pip install jieba,使用:jieba.cut("我是一個程序員"))
上面的countvec不能處理中性詞比如“明天,中午,因為”等。于是可以使用tfidf方法。
tf:term frequency詞頻(和countvec方法一樣)
idf:inverse document frequency逆文檔頻率 log(總文檔數量/該詞出現的文檔數)
tf * idf 重要性程度
類:sklearn.feature_extraction.text.TfidfVectorizer
特征預處理:通過特定的統計方法,將數據轉換為算法要求的數據
特征預處理API:sklearn.preprocessing

歸一化API:sklearn.preprocessing.MinMaxScaler

多個特征同等重要并且特征數據之間差距較大的時候,進行歸一化。但歸一化容易受異常點的影響,因此該方法魯棒性較差,只適合傳統精確小數據場景。
將原始數據變換到均值為0,標準差為1的范圍內

標準化API:
sklearn.preprocessing.StandardScaler

標準化適合現代嘈雜大數據場景,在已有樣本足夠多的情況下比較穩定。
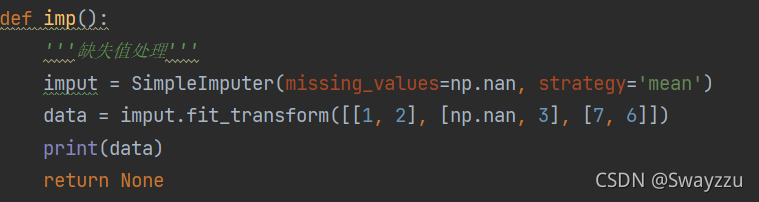
插補:通過缺失值每行或每列的平均值、中位數來填補(一般按列填補)
API:sklearn.impute.SimpleImputer
數據當中的缺失值標記:默認為np.nan
以上是“python機器學習中特征工程算法的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





