溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下C++string底層框架的示例分析,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
主要說明淺拷貝和深拷貝的優缺點,以及仿寫string類的邏輯并分析實現過程
先來上一組代碼
class string{
public:
string(char* str="")
:_size(strlen(str))
,_capacity(_size)
{
_str = new char[_capacity+1];
strcpy(_str, str);
}
char& operator[](const char& pos) const {
return _str[pos];
}
~string(){
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};void Test1(){
string s1("never gonna give you up");
string s2 = s1;
s2[0] = 'Y';
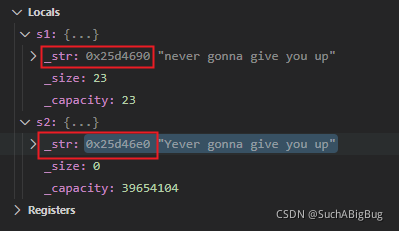
}當我們把s1拷貝給s2,這里是深拷貝還是淺拷貝呢?先不說答案我們debug看一下
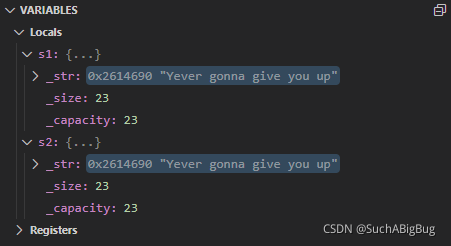
一目了然,這里的s1和s2為同一個地址
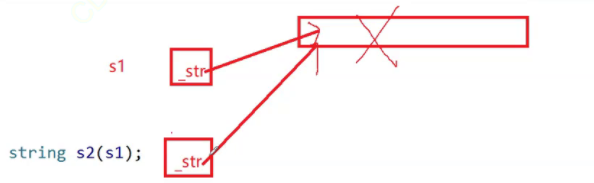
那么當我們改變s2[0]的值時,s1[0]也隨之改變,那么還是給人一種藕斷絲連的感覺沒有完全獨立拷貝,這就是淺拷貝,相信我們也看到了淺拷貝帶來的弊端
其次,當我們調用析構函數也會出現問題,由于他們指向的是同一塊空間,s2會先析構將里面的數組delete并置空
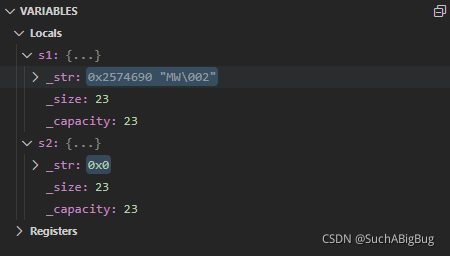
接著s1調用析構函數時就會報錯,所以不能指向同一塊空間
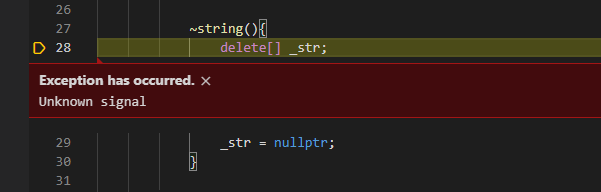
總結一下淺拷貝問題:
這塊空間會在兩個對象析構函數被delete兩次一個對象修改會影響另外一個對象
深拷貝怎么實現?
string(const string& s) //函數重載
:_str(new char[strlen(s._str)+1])
{
strcpy(this->_str, s._str);
}我們重新new一個空間給s2,下面下圖可以看到s1和s2在堆上不再是同一個空間
這里第一個參數是this被匿名了,為了方面看,我把this加了進去
和淺拷貝區別就在于指明了當前字符串需重新分配空間和重新賦值到新開的這組新空間,這里的深拷貝就不會出現上面的問題,當我們改變s2[0]的值,s1[0]不會跟著改變
賦值重載的方式解決淺拷貝問題
string& operator=(string& s){
if(this != &s){
char* tmp = new char[strlen(s._str)+1];
delete[] _str; //刪除this原來的內容
_str = tmp; //將新空間賦給_str
strcpy(_str, s._str);
_size = _capacity = strlen(s._str);
_str[_size] = '\0';
}
return *this;
}上面都為傳統寫法,通過new開辟一組新的堆空間,和現代寫法的思路是有區別的
這里是重新構造一個臨時string tmp變量新開了一組空間,然后再swap把兩者進行交換,等于this->_str獲得了這個新空間,最后把不需要的空間自動析構
string (const string& str)
:_str(nullptr)
{
string tmp(str);
swap(_str, tmp._str);
}
//這組沒有用到引用,因為形參自動調用拷貝構造
string& operator=(string t)
{
swap(_s,t._s);
return *this;
}那么是不是深拷貝一定就是最好的呢?
答案是不一定,寫時拷貝在淺拷貝基礎上增加了引用計數方式,換句話說有多少個對象指向這塊空間,計數就會++,那么只有當某個對象去寫數據時,那個對象才會進行深拷貝,然后計數–
這本質上是寫的時候一種延遲深拷貝,但如果拷貝對象后沒有人進行修改,沒有進行深拷貝重開一塊空間,也就順理成章的提高效率。但是實際應用場景中不是很理想
這里私有成員結構就類似順序表,當我們增加或刪除數據時需要記錄當前的信息,以及是否需要擴容等,npos用于查找是否有此字符,默認返回-1
class string{
public:
private:
char* _str;
size_t _size;
size_t _capacity;
static const size_t npos;
};
const size_t string::npos = -1;void Test2(){
string s1("helloworld");
string s2(5, 'g');
string();
}上面的函數名都構成函數重載,目前實現了三種常見的
string(const char* str="")
:_size(strlen(str))
,_capacity(_size)
{
_str = new char[_capacity+1];
strcpy(_str, str);
}第一種最普遍,直接將字符串賦給s1即可
string(size_t n, char c)
:_size(n)
,_capacity(_size)
{
_str = new char[ _size + 1];
for(size_t i=0; i<n; ++i) _str[i] = c;
}第二種可以創建一組n個相同的字符
string()
:_str(new char[1])
,_size(0)
,_capacity(0)
{
*_str = '\0';
}最后一種創建一個空函數,里面并不為空,默認放一個斜杠零
~string(){
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}用于釋放空間,當我們new完一組空間后需要手動創建析構函數
下列賦值重載中,第一個支持讀和寫
char& operator[](size_t pos){
return _str[pos];
}第二個不支持寫
const char& operator[](size_t pos) const{
return _str[pos];
}這里我把賦值重載都給列出來,push_back函數在下面會提到
//可讀可寫
String& operator+=(char ch){
push_back(ch);
return *this;
}下列的賦值重載,實現依次比較數組中值的大小
//按照ASCII碼進行比較
//s1 > s2 ?
//"abc" "abc" false
//"abc" "ab" true
//"ab" "abc" false
bool operator>(const string& s1, const string& s2){
size_t i1 = 0, i2 =0;
while(i1 < s1.size() && i2 < s2.size()){
if(s1[i1] > s2[i2]){
return true;
}else if(s1[i1] < s2[i2]){
return false;
}else{
++i1;
++i2;
}
}
if(i1 == s1.size()){
return false;
}else{
return true;
}
return true;
}
bool operator==(const string& s1, const string& s2){
size_t i1 = 0, i2 =0;
while(i1 < s1.size() && i2 < s2.size()){
if(s1[i1] > s2[i2]){
return true;
}else if(s1[i1] < s2[i2]){
return false;
}else{
++i1;
++i2;
}
}
if(i1 == s1.size() && i2 == s2.size()){
return true;
}else{
return false;
}
}
bool operator!=(const string& s1, const string& s2){
return !(s1==s2);
}
bool operator>=(const string& s1, const string& s2){
return (s1>s2 || s1==s2);
}
bool operator<(const string& s1, const string& s2){
return !(s1 >= s2);
}
bool operator<=(const string& s1, const string& s2){
return !(s1>s2);
}
String operator+(const string& s1, const string& str){
String ret = s1;
ret += str;
return ret;
}resize分為三種情況
當n小于等于size,則size等于n
當n大于size但小于capacity,無法添加數據
當n大于capacity時,先增容,然后從size開始填數據,填到n
void reserve(size_t n){
if(n > _capacity){
char* tmp = new char[n+1]; //開一個更大的空間
strcpy(tmp, _str); //進行拷貝,然后釋放此空間
delete[] _str;
_str = tmp; //然后指向新開的空間
}
_capacity = n;
}
void resize(size_t n, char ch='\0'){
//大于,小于,等于的情況
if(n <= _size){
_size = n;
_str[_size] = '\0';
}else{
if(n > _capacity){ //空間不夠,先增容
reserve(n);
for(size_t i = _size; i<n; i++){ //從size開始填數據,填到n
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}
}在字符串的最后增加一個字符
void push_back(char c){
if(_size >= _capacity){
//這種如果size和capacity都為0,那么計算出的2倍w也為0,最后調用析構的時候報錯
//reserve(_capacity * 2);
size_t newCapacity = _capacity == 0 ? 4 : _capacity*2;
reserve(newCapacity);
}
_str[_size] = c;
++_size;
_str[_size] = '\0';
}在字符串的最后增加一串字符,這里需要注意判斷原本容量的大小是否比新增的字符串容量要小,如果是就需要新reserve一組更大的空間
void append(const char* s){
size_t len = strlen(s);
if(_size + len >= _capacity){
reserve(_size + len);
}
strcpy(_str + _size, s); //把這個字符串給拷貝過去
_size += len;
}在pos位置,插入字符或者字符串,這里我們實際應用中,不推薦使用,因為數組數據過于龐大時,在中間插入后,pos后面的數據都需要依次向后挪動
string& insert(size_t pos, char ch){
assert(pos<=_size); //pos不能超出此范圍
if(_size == _capacity){
size_t newcapacity = _capacity == 0 ? 4 : _capacity*2;
reserve(newcapacity);
}
size_t end = _size+1;
while( end > _size){
_str[end-1] = _str[end];
--end;
}
_str[_size] = ch;
++_size;
return *this;
}
string& insert(size_t pos, const char* str){
assert(pos <= _size);
size_t len = strlen(str);
if(len == 0){
return *this;
}
if(len + _size > _capacity){
reserve(len + _size);
}
size_t end = _size + len;
while(end >= pos + len){
_str[end] = _str[end-len];
--end;
}
for(size_t i= 0; i<len; ++i){
_str[pos + i] = str[i];
}
_size += len;
return *this;
}String& erase(size_t pos, size_t len=npos){
assert(pos < _size);
//1. pos后面刪完
//2. pos后面刪一部分
if(len == npos || len+pos >= _size){
_str[pos] = '\0';
_size = pos;
}else{
//刪一部分
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}查找匹配的第一個字符,返回其下標
//查找,直接返回字符的下標位置
size_t find(char ch, size_t pos=0){
for(size_t i = pos; i<_size; ++i){
if(_str[i] == ch ){
return i;
}
}
return npos;
}查找字符串,這里就直接調用C語言中的strstr函數進行暴力匹配查找
size_t find(const char* sub, size_t pos=0){
const char* p = strstr(_str+pos, sub);
if(p == nullptr){
return npos;
}else{
return p-_str;
}
}前面不加const的支持數據修改
初次用迭代器玩不明白,其實刨開看也沒有特別神奇,只不過是封裝起來了
typedef char* iterator;
typedef const char* const_iterator;
iterator begin(){
return _str;
}
iterator end(){
return _str + _size;
}
const_iterator begin() const{
return _str;
}
const_iterator end() const{
return _str + _size;
}//流插入
ostream& operator<<(ostream& out, const String& s){
for(size_t i = 0; i<s.size(); ++i){
out << s[i];
}
return out;
}
//流提取
istream& operator>>(istream& in, String& s){
s.clear();
char ch;
// in >> ch; 遇到換行會自動停止
ch = in.get();
while(ch != ' ' && ch != '\n'){
s += ch; //提取字符串到這個String s字符串中去
ch = in.get();
}
return in;
}//上面的是遇到空格就停止了然后傳給cout,而下面我們要實現一行哪怕中間有空格
istream& getline(istream& in, String& s){
s.clear();
char ch;
ch = in.get();
// while(ch != ' ' && ch != '\n'){
while(ch != '\n'){ //遇到空格不結束
s += ch;
ch = in.get();
}
return in;
}我們可以看到流提取和getline的最大區別在于,流提取遇到空格后,就直接結束了
而getline不一樣,函數里面忽略判斷空格條件,而只保留判斷換行符
void test1(){
// cin >> s1;
// cout << s1 << endl; //注意如果有空格的hello world,hello打印出來了但是 world check the rythm還在緩沖區
getline(cin, s1); //打印帶有空格的一個字符串
cout << s1 <<endl;
}看完了這篇文章,相信你對“C++string底層框架的示例分析”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





