溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
快一年沒寫博客了,終于回來了,最近因公司業務需要,要基于cdh發行版打包自定義patch的rpm,于是又搞起了bigtop,就是那個hadoop編譯打包rpm和deb的工具,由于國內基本沒有相關的資料和文檔,所以覺得有必要把閱讀bigtop源碼和修改的思路分享一下。
我記得很早以前,bigtop在1.0.0以前版本吧,是用make進行打包的,其實這個0.9.0以前的版本,擱我覺得就不應該出現在apache正式倉庫里,就應該放在incubator里面,但是估計由于是cdh主導開發的,而Doug Cutting又是前基金會主席,所以,一個基本沒有產品化的東西從孵化器提升到頂級項目相對容易一些吧。cloudera官方在github上開源的的cdh-package應該是基于bigtop 0.6.0的,不過由于他們的每個git分支只更新rpm的spec文件,所以,貌似默認情況下根本使不了,不厚道啊。而apache的bigtop又沒有cdh相關的avro,sentry,llama等依賴,所以只能自己讀源碼修改。
解決方案一:基于cdh-package進行修改,優勢是貼近cloudera,可能需要修改的代碼量比較少,劣勢是基于make,后期維護性和可擴展性較差,我可不想去改Makefile那種東西。
解決方案二:基于apache bigtop進行修改,優勢是使用gradle編譯,可維護性可擴展性好,劣勢是代碼修改量大。
考慮再三,我決定還是貼近社區,遠離資本家,跟廣大無產階級走,所以我選擇了apache bigtop,另外,cdh-package除了需要java1.7以外,還需要java1.5,所以。Let it be.
當然,這里有很多坑都需要踩,其中最大的一個坑就是GFW。感謝政府對我一奔四十的老爺們的思想保護,遠離黃賭毒,用偉大的長城防火墻屏蔽了全世界。偉大的長城防火墻不但有花季護航,還有而立護航,不惑護航,知天命護航,耳順護航及古稀護航,耄耋護航,期頤護航等眾多配置選項,保護國人從生到死不受國外先進技術的侵蝕。
所以,如果你想正常編譯hadoop及其周邊生態,聽我的,買個國外的云主機,絕對事半功倍。同時,為了保證對bigtop修改本身的版本控制及錯誤回滾,git或者svn是需要的。
以下內容基于bigtop 1.1.0 production以及美國云主機
打包編譯相關技能天賦加點:
gradle, maven, ant, forrest, groovy, shell, rpm spec.特別是shell和spec的天賦要盡可能點滿,不行就去看rpm.org里面的文檔。而maven和ant基本都是自動施法,不太需要點天賦。另外,maven, ant, java本身的版本就不再贅述了。
按照我對bigtop源碼的理解,分為執行層,編譯層和腳本層。執行層即gradle和gradle的相關定義文件。編譯層包括maven, ant,嵌套在maven里的ant,forrest,scala等。腳本層為rpm的spec文件,deb的定義文件以及他們所包含的編譯相關腳本,如do-build-components這類腳本。
定義編譯什么東西及它的版本,下載地址的定義,文件名的定義是在bigtop.bom中定義的,然后會調用package.gradle來進行自動下載及配置編譯目錄,打包目錄等。之后會通過package.gradle調用rpmbuild來讀取spec文件,spec文件會通過內部的Source0這類的定義來讀取編譯腳本,最終通過rpmbuild來建立所有需要的rpm包。
初始下載解壓縮bigtop-1.1.0之后,需要先對bigtop依賴的包進行初始化,會下載protobuf,snappy什么的。完成之后用戶可以編譯的是apache的hadoop及周邊相關,編譯之后是可以用,但是不符合我的需求。為啥,因為cloudera 2B似的為顯示自己牛逼,兼容,搞了一個畫蛇添足的0.20-mapreduce。由于之前集群安裝的是cdh的hadoop,已安裝的rpm依賴里面有0.20的安裝包,所以,如果我用原生apache bigtop打包出來的 cdh hadoop,是沒有0.20這個package的。那么在自己做了repository之后用yum update,會提示缺少0.20的依賴,需要使用--skip-broken來安裝,作為一個×××座是不允許這種情況發生的。另外,據同事反饋,cdh的hadoop如果使用apache的zookeeper做ha時會出現找不到znode的問題,無法ha。
所以,唯一的解決辦法是找到cdh的spec文件,打的跟cdh一模一樣才可以。這東西其實并不難找,留個問題自己發現吧。不過,直接取出來的cdh spec文件與打包腳本,在apache bigtop上是不能直接使用的。需要修改不少地方,比如像prelink,還有需要建立一套busybox出來,當然其他的打包依賴還有諸如boost,llvm,thrift等等。還有,cdh會把自己的編譯依賴建立在/opt/toolchain下面,但是apache bigtop不會有這東西,自己建軟鏈就可以解決了。
寫著寫著趴下瞇了一會午覺,起來突然不知道該寫什么了,如果熟悉之前說的天賦加點,這玩意確實沒什么難度。如果不熟悉,那這玩意是相當的難以理解和使用,會遇到各種各樣的報錯,特別是如果在rpmbuild過程中報錯,是很難找到出錯原因的。
至于建立yum倉庫這種事情就更不用描述了。
整個項目的關鍵點就是腳本和spec語言,gradle語言都是次要的。
最后,為顯示自己牛逼,放兩張截圖出來。
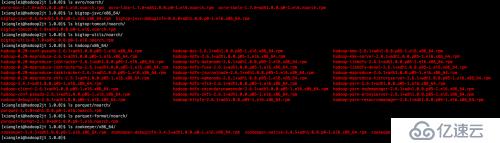

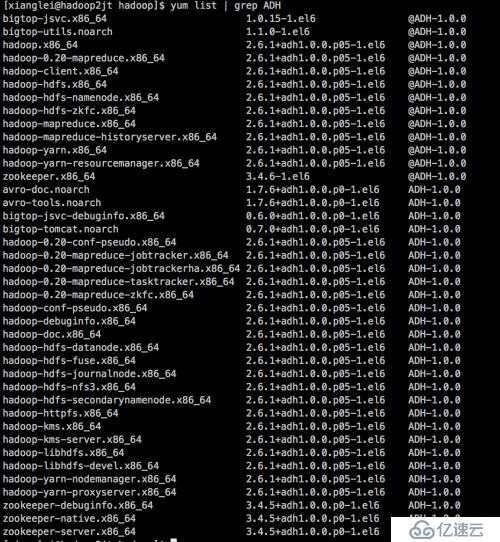
我的下一個milestone是把hortonworks的storm package打到cdh hadoop上面跑。不過在實現這個目標之前,似乎公司要把我派去寫hive和pig腳本,真是沒興趣啊。
最后,打個廣告,Nathan Marz (Storm作者) 的書,《大數據系統構建--Lambda架構實踐》上市。譯者:馬延輝,魏東琦,還有我,歡迎大家踴躍購買,看完之后批評指正。
購買鏈接
京東
當當
亞馬遜
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





