溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中pytorch神經網絡Dropout怎么用,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
在之前我們討論權重衰減(L2正則化)時看到的那樣,參數的范數也代表了一種有用的簡單性度量。簡單性的另一個有用角度是平滑性,即函數不應該對其輸入的微笑變化敏感。例如,當我們對圖像進行分類時,我們預計向像素添加一些隨機噪聲應該是基本無影響的。
dropout在正向傳播過程中,計算每一內部層同時注入噪聲,這已經成為訓練神經網絡的標準技術。這種方法之所以被稱為dropout,因為我們從表面上看是在訓練過程中丟棄(drop out)一些神經元。在整個訓練過程的每一次迭代中,dropout包括在計算下一層之前將當前層中的一些節點置零。
那么關鍵的挑戰就是如何注入這種噪聲,一種想法是以一種無偏的方式注入噪聲。這樣在固定住其他層時,每一層的期望值等于沒有噪音時的值。

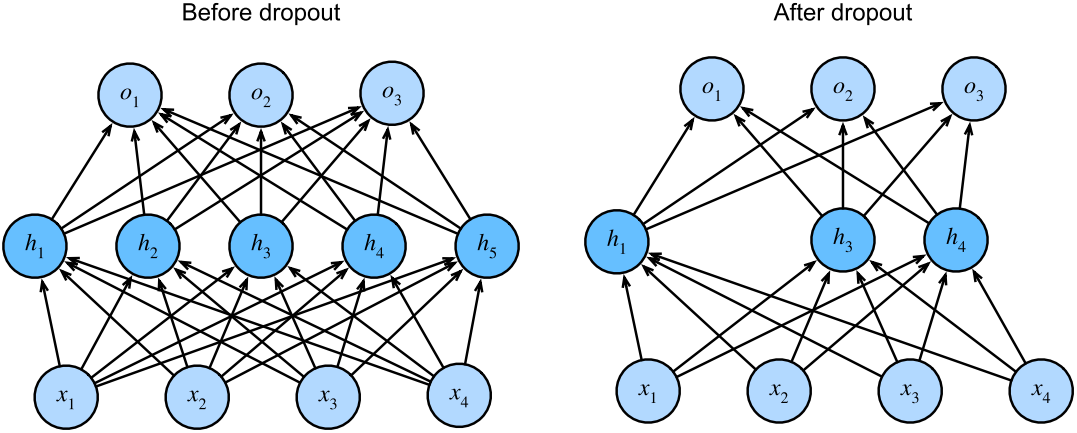
之前多層感知機是帶有一個隱藏層和5個隱藏單元的。當我們將dropout應用到隱藏層時,以 p的概率將隱藏單元置為零時,結果可以看作是一個只包含原始神經元子集的網絡。右圖中,刪除了 h3和 h6。因此,輸出的計算不再依賴于 h3或 h6,并且它們各自的梯度在執行反向傳播時也會消失。這樣,輸出層的計算不能過度依賴于 h2,…,h6的任何一個元素。
通常,我們在測試時僅用dropout。給定一個訓練好的模型和一個新的樣本,我們不會丟棄任何節點,因此不需要標準化。
對于高級API,我們所需要做的就是在每個全連接層之后添加一個Dropout層,將丟棄概率作為唯一的參數傳遞給它的構造函數。在訓練過程中,Dropout層將根據指定的丟棄概率隨機丟棄上一層的輸出(相當于下一層的輸入)。當不處于訓練模式時,Dropout層僅在測試時傳遞數據。
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), # 在第一個全連接層之后添加一個dropout層 nn.Dropout(dropout1), nn.Linear(256, 256), nn.ReLU(), # 在第二個全連接層之后添加一個dropout層 nn.Dropout(dropout2), nn.Linear(256, 10)) def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights)
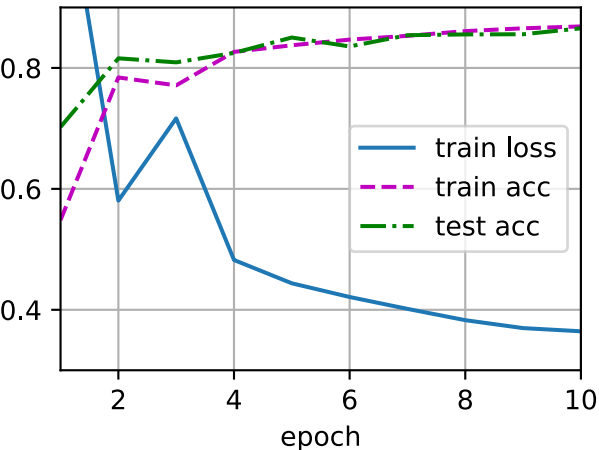
接下來,我們對模型進行訓練和測試。
trainer = torch.optim.SGD(net.parameters(), lr=lr) d2l.train_ch4(net, train_iter, test_iter, loss, num_epochs, trainer)
關于“Python中pytorch神經網絡Dropout怎么用”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





