溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
數據挖掘——推薦系統
大數據可以認為是許多數據的聚合,數據挖掘是把這些數據的價值發掘出來,比如有過去10年的氣象數據,通過數據挖掘,幾乎可以預測明天的天氣是怎么樣的,有較大概率是正確的。
機器學習是人工智能的核心,對大數據進行發掘,靠人工肯定是做不來的,那就得靠機器代替人工得到一個有效模型,通過該模型將大數據中的價值體現出來。
本章內容:
1) 數據挖掘和機器學習概念
2) 一個機器學習應用方向——推薦系統
3) 推薦算法——基于內容的推薦方法
4) 推薦算法——基于協同過濾的推薦方法
5) 基于MapReduce的協同過濾算法的實現
機器學習和數據挖掘技術已經開始在多媒體、計算機圖形學、計算機網絡乃至操作系統、軟件工程等計算機科學的眾多領域中發揮作用,特別是在計算機視 覺和自然語言處理領域,機器學習和數據挖掘已經成為最流行、最熱門的技術,以至于在這些領域的頂級會議上相當多的論文都與機器學習和數據挖掘技術有關。總的來看,引入機器學習和數據挖掘技術在計算機科學的眾多分支領域中都是一個重要趨勢。
對于數據挖掘,數據庫提供數據管理技術,機器學習提供數據分析技術。通常我們要處理的大數據通過HDFS云存儲平臺來進行數據管理,目前Hadoop生態圈已經發展成熟,各種工具和接口基本滿足大多數數據管理的需要。面對這樣龐大的數據資源,需要有一種方法需要讓其中的價值體現出來,機器學習提供了一系列的分析挖掘數據的方法。
Hadoop生態圈中有一個機器學習開源庫的項目——Mahout,提供了豐富的可擴展的機器學習領域經典算法的實現,旨在幫助開發人員更加方便快捷地創建智能應用程序,Mahout包含許多實現,包括聚類、分類、推薦過濾、頻繁子項挖掘。
推薦算法是最為大眾所知的一種機器學習模型。推薦是很多網站背后的核心組件之一,有時也是一個重要的收入來源。
一般來講,推薦系統試圖對用戶與某類物品之間的聯系建模。比如我們利用推薦系統來告訴用戶有哪些電影他們會可能喜歡。如果這一點做的很好的話,就能夠吸引更多的用戶持續使用我們的服務。這對雙方都有好處。同樣,如果能準確告訴用戶有哪些電影與某一個電影相似,就能方便用戶在站點上找到更多感興趣的信息。這也能提升用戶的體驗、參與度以及站點內容對用戶的吸引力。對于大型網站來說,很多內容是來自于獨立的第三方——內容提供商,比如淘寶的商品寶貝基本來自各個店鋪、奇藝上的電影很多來自與專業的傳媒集團和工作室、微信上制作精良的廣告也是來自于各個行業的廣告主。
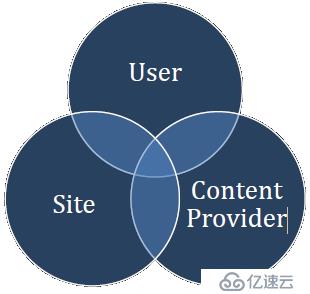
建立一個良好的推薦生態圈,對于用戶、網站平臺以及內容提供商,都是有好處的,首先用戶得到他們想要的物品,平臺獲得更多的流量和收入,內容提供商售賣其物品的效率也會提高,所以是一個三者共贏的一個場景,所以一個好的推薦系統會帶來很大的價值。
基于內容的推薦(Content Based)應該算最早被使用的推薦方法,它根據用戶過去喜歡的產品(本文統稱為 item),為用戶推薦和他過去喜歡的產品相似的產品。例如,一個推薦飯店的系統可以依據某個用戶之前喜歡很多的烤肉店而為他推薦烤肉店。 CB最早主要是應用在信息檢索系統當中,所以很多信息檢索及信息過濾里的方法都能用于CB中。
CB的過程一般包括以下三步:
1) Item Representation:為每個item抽取出一些特征(也就是item的content了)來表示此item;
2) Profile Learning:利用一個用戶過去喜歡(及不喜歡)的item的特征數據,來學習出此用戶的喜好特征(profile);
3) Recommendation Generation:通過比較上一步得到的用戶profile與候選item的特征,為此用戶推薦一組相關性最大的item。
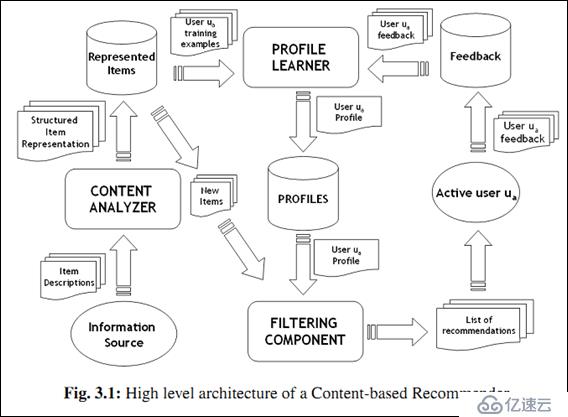
舉個例子說明前面的三個步驟。對于個性化閱讀來說,一個item就是一篇文章。根據上面的第一步,我們首先要從文章內容中抽取出代表它們的屬性。常用的方法就是利用出現在一篇文章中詞來代表這篇文章,而每個詞對應的權重往往使用信息檢索中的tf-idf來計算。比如對于本文來說,詞“CB”、“推薦”和“喜好”的權重會比較大,而“烤肉”這個詞的權重會比較低。利用這種方法,一篇抽象的文章就可以使用具體的一個向量來表示了。第二步就是根據用戶過去喜歡什么文章來產生刻畫此用戶喜好的 profile了,最簡單的方法可以把用戶所有喜歡的文章對應的向量的平均值作為此用戶的profile。比如某個用戶經常關注與推薦系統有關的文章,那么他的profile中“CB”、“CF”和“推薦”對應的權重值就會較高。在獲得了一個用戶的profile后,CB就可以利用所有item與此用戶profile的相關度對他進行推薦文章了。一個常用的相關度計算方法是cosine。最終把候選item里與此用戶最相關(cosine值最大)的N個item作為推薦返回給此用戶。
接下來我們詳細介紹下上面的三個步驟。
1) Item Representation:
真實應用中的item往往都會有一些可以描述它的屬性。這些屬性通常可以分為兩種:結構化的(structured)屬性與非結構化的(unstructured)屬性。所謂結構化的屬性就是這個屬性的意義比較明確,其取值限定在某個范圍;而非結構化的屬性往往其意義不太明確,取值也沒什么限制,不好直接使用。比如在交友網站上,item就是人,一個item會有結構化屬性如身高、學歷、籍貫等,也會有非結構化屬性(如item自己寫的交友宣言,博客內容等等)。對于結構化數據,我們自然可以拿來就用;但對于非結構化數據(如文章),我們往往要先把它轉化為結構化數據后才能在模型里加以使用。真實場景中碰到最多的非結構化數據可能就是文章了(如個性化閱讀中)。下面我們就詳細介紹下如何把非結構化的一篇文章結構化。
如何代表一篇文章在信息檢索中已經被研究了很多年了,下面介紹的表示技術其來源也是信息檢索,其名稱為向量空間模型(Vector Space Model,簡稱VSM)。
記我們要表示的所有文章集合為 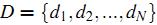 ,而所有文章中出現的詞(對于中文文章,首先得對所有文章進行分詞)的集合(也稱為詞典)為
,而所有文章中出現的詞(對于中文文章,首先得對所有文章進行分詞)的集合(也稱為詞典)為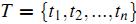 。也是說,我們有N篇要處理的文章,而這些文章里包含了n個不同的詞。我們最終要使用一個向量來表示一篇文章,比如第j篇文章被表示為
。也是說,我們有N篇要處理的文章,而這些文章里包含了n個不同的詞。我們最終要使用一個向量來表示一篇文章,比如第j篇文章被表示為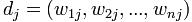 ,其中
,其中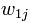 表示第1個詞
表示第1個詞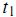 在文章j中的權重,值越大表示越重要;
在文章j中的權重,值越大表示越重要;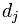 中其他向量的解釋類似。所以,為了表示第j篇文章,現在關鍵的就是如何計算
中其他向量的解釋類似。所以,為了表示第j篇文章,現在關鍵的就是如何計算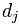 各分量的值了。例如,我們可以選取
各分量的值了。例如,我們可以選取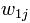 為1,如果詞
為1,如果詞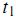 出現在第 j 篇文章中;選取為0,如果
出現在第 j 篇文章中;選取為0,如果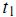 未出現在第j篇文章中。我們也可以選取
未出現在第j篇文章中。我們也可以選取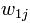 為詞
為詞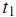 出現在第 j 篇文章中的次數(frequency)。但是用的最多的計算方法還是信息檢索中常用的詞頻-逆文檔頻率(term frequency–inverse document frequency,簡稱tf-idf)。第j篇文章中與詞典里第k個詞對應的tf-idf為:
出現在第 j 篇文章中的次數(frequency)。但是用的最多的計算方法還是信息檢索中常用的詞頻-逆文檔頻率(term frequency–inverse document frequency,簡稱tf-idf)。第j篇文章中與詞典里第k個詞對應的tf-idf為:
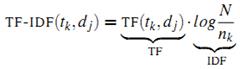
其中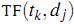 是第k個詞在文章j中出現的次數,而
是第k個詞在文章j中出現的次數,而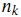 是所有文章中包括第k個詞的文章數量。
是所有文章中包括第k個詞的文章數量。
最終第k個詞在文章j中的權重由下面的公式獲得:
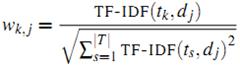
做歸一化的好處是不同文章之間的表示向量被歸一到一個量級上,便于下面步驟的操作。
2) Profile Learning
假設用戶u已經對一些item給出了他的喜好判斷,喜歡其中的一部分item,不喜歡其中的另一部分。那么,這一步要做的就是通過用戶u過去的這些喜好判斷,為他產生一個模型。有了這個模型,我們就可以根據此模型來判斷用戶u是否會喜歡一個新的item。所以,我們要解決的是一個典型的有監督分類問題,理論上機器學習里的分類算法都可以照搬進這里。
下面我們簡單介紹下CB里常用的學習算法——KNN:
對于一個新的item,最近鄰方法首先找用戶u已經評判過并與此新item最相似的k個item,然后依據用戶u對這k個item的喜好程度來判斷其對此新item的喜好程度。這種做法和CF中的item-based kNN很相似,差別在于這里的item相似度是根據item的屬性向量計算得到,而CF中是根據所有用戶對item的評分計算得到。
對于這個方法,比較關鍵的可能就是如何通過item的屬性向量計算item之間的兩兩相似度。[2]中建議對于結構化數據,相似度計算使用歐幾里得距離;而如果使用向量空間模型(VSM)來表示item的話,則相似度計算可以使用cosine。
3) Recommendation Generation
通過上一步的學習,會得到一個推薦列表,我們直接把這個列表中與用戶屬性最相關的n個item作為推薦返回給用戶即可。
俗話說“物以類聚、人以群分”,繼續拿看電影這個例子來說,如果你喜歡《蝙蝠俠》、《碟中諜》、《星際穿越》、《源代碼》等電影,另外有個人也都喜歡這些電影,而且他還喜歡《鋼鐵俠》,則很有可能你也喜歡《鋼鐵俠》這部電影。
所以說,當一個用戶 A 需要個性化推薦時,可以先找到和他興趣相似的用戶群體G,然后把 G 喜歡的、并且 A 沒有聽說過的物品推薦給 A,這就是基于用戶的系統過濾算法。
根據上述基本原理,我們可以將基于用戶的協同過濾推薦算法拆分為兩個步驟:
1) 發現興趣相似的用戶
通常用 Jaccard 公式或者余弦相似度計算兩個用戶之間的相似度。設 N(u) 為用戶 u 喜歡的物品集合,N(v) 為用戶 v 喜歡的物品集合,那么 u 和 v 的相似度是多少呢:
Jaccard 公式:
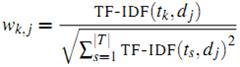
余弦相似度:
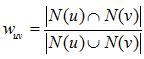
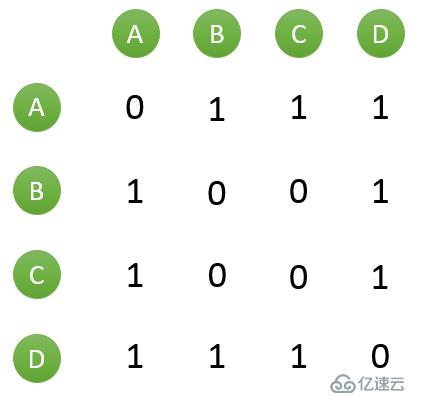
假設目前共有4個用戶: A、B、C、D;共有5個物品:a、b、c、d、e。用戶與物品的關系(用戶喜歡物品)如下圖所示:
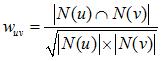
如何一下子計算所有用戶之間的相似度呢?為計算方便,通常首先需要建立“物品—用戶”的倒排表,如下圖所示:

然后對于每個物品,喜歡他的用戶,兩兩之間相同物品加1。例如喜歡物品 a 的用戶有 A 和 B,那么在矩陣中他們兩兩加1。如下圖所示:

計算用戶兩兩之間的相似度,上面的矩陣僅僅代表的是公式的分子部分。以余弦相似度為例,對上圖進行進一步計算:
到此,計算用戶相似度就大功告成,可以很直觀的找到與目標用戶興趣較相似的用戶。
2) 推薦物品
首先需要從矩陣中找出與目標用戶 u 最相似的 K 個用戶,用集合 S(u, K) 表示,將 S 中用戶喜歡的物品全部提取出來,并去除 u 已經喜歡的物品。對于每個候選物品 i ,用戶 u 對它感興趣的程度用如下公式計算:
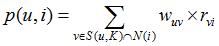
其中 rvi 表示用戶 v 對 i 的喜歡程度,在本例中都是為 1,在一些需要用戶給予評分的推薦系統中,則要代入用戶評分。
舉個例子,假設我們要給 A 推薦物品,選取 K = 3 個相似用戶,相似用戶則是:B、C、D,那么他們喜歡過并且 A 沒有喜歡過的物品有:c、e,那么分別計算 p(A, c) 和 p(A, e):
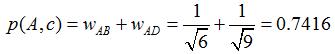
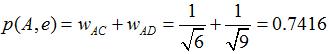
看樣子用戶 A 對 c 和 e 的喜歡程度可能是一樣的,在真實的推薦系統中,只要按得分排序,取前幾個物品就可以了。
如何用4個月學會Hadoop開發并找到年薪25萬工作?
免費分享一套17年最新Hadoop大數據教程和100道Hadoop大數據必會面試題。
因為鏈接經常被和諧,需要的朋友請加微信 ganshiyun666 來獲取最新下載鏈接,注明“51CTO”
教程已幫助300+人成功轉型Hadoop開發,90%起薪超過20K,工資比之前翻了一倍。
百度Hadoop核心架構師親自錄制
內容包括0基礎入門、Hadoop生態系統、真實商業項目實戰3大部分。其中商業案例可以讓你接觸真實的生產環境,訓練自己的開發能力。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





